

eSentire delivers private and secure generative AI interactions to customers with Amazon SageMaker
eSentire is an industry-leading provider of Managed Detection & Response (MDR) services protecting users, data, and applications of over 2,000 organizations globally across more than 35 industries… In 2023, eSentire was looking for ways to deliver differentiated customer experiences by contin…
eSentire is an industry-leading provider of Managed Detection & Response (MDR) services protecting users, data, and applications of over 2,000 organizations globally across more than 35 industries. These security services help their customers anticipate, withstand, and recover from sophisticated cyber threats, prevent disruption from malicious attacks, and improve their security posture.
In 2023, eSentire was looking for ways to deliver differentiated customer experiences by continuing to improve the quality of its security investigations and customer communications. To accomplish this, eSentire built AI Investigator, a natural language query tool for their customers to access security platform data by using AWS generative artificial intelligence (AI) capabilities.
In this post, we share how eSentire built AI Investigator using Amazon SageMaker to provide private and secure generative AI interactions to their customers.
Benefits of AI Investigator
Before AI Investigator, customers would engage eSentire’s Security Operation Center (SOC) analysts to understand and further investigate their asset data and associated threat cases. This involved manual effort for customers and eSentire analysts, forming questions and searching through data across multiple tools to formulate answers.
eSentire’s AI Investigator enables users to complete complex queries using natural language by joining multiple sources of data from each customer’s own security telemetry and eSentire’s asset, vulnerability, and threat data mesh. This helps customers quickly and seamlessly explore their security data and accelerate internal investigations.
Providing AI Investigator internally to the eSentire SOC workbench has also accelerated eSentire’s investigation process by improving the scale and efficacy of multi-telemetry investigations. The LLM models augment SOC investigations with knowledge from eSentire’s security experts and security data, enabling higher-quality investigation outcomes while also reducing time to investigate. Over 100 SOC analysts are now using AI Investigator models to analyze security data and provide rapid investigation conclusions.
Solution overview
eSentire customers expect rigorous security and privacy controls for their sensitive data, which requires an architecture that doesn’t share data with external large language model (LLM) providers. Therefore, eSentire decided to build their own LLM using Llama 1 and Llama 2 foundational models. A foundation model (FM) is an LLM that has undergone unsupervised pre-training on a corpus of text. eSentire tried multiple FMs available in AWS for their proof of concept; however, the straightforward access to Meta’s Llama 2 FM through Hugging Face in SageMaker for training and inference (and their licensing structure) made Llama 2 an obvious choice.
eSentire has over 2 TB of signal data stored in their Amazon Simple Storage Service (Amazon S3) data lake. eSentire used gigabytes of additional human investigation metadata to perform supervised fine-tuning on Llama 2. This further step updates the FM by training with data labeled by security experts (such as Q&A pairs and investigation conclusions).
eSentire used SageMaker on several levels, ultimately facilitating their end-to-end process:
- They used SageMaker notebook instances extensively to spin up GPU instances, giving them the flexibility to swap high-power compute in and out when needed. eSentire used instances with CPU for data preprocessing and post-inference analysis and GPU for the actual model (LLM) training.
- The additional benefit of SageMaker notebook instances is its streamlined integration with eSentire’s AWS environment. Because they have vast amounts of data (terabyte scale, over 1 billion total rows of relevant data in preprocessing input) stored across AWS—in Amazon S3 and Amazon Relational Database Service (Amazon RDS) for PostgreSQL clusters—SageMaker notebook instances allowed secure movement of this volume of data directly from the AWS source (Amazon S3 or Amazon RDS) to the SageMaker notebook. They needed no additional infrastructure for data integration.
- SageMaker real-time inference endpoints provide the infrastructure needed for hosting their custom self-trained LLMs. This was very useful in combination with SageMaker integration with Amazon Elastic Container Registry (Amazon ECR), SageMaker endpoint configuration, and SageMaker models to provide the entire configuration required to spin up their LLMs as needed. The fully featured end-to-end deployment capability provided by SageMaker allowed eSentire to effortlessly and consistently update their model registry as they iterate and update their LLMs. All of this was entirely automated with the software development lifecycle (SDLC) using Terraform and GitHub, which is only possible through SageMaker ecosystem.
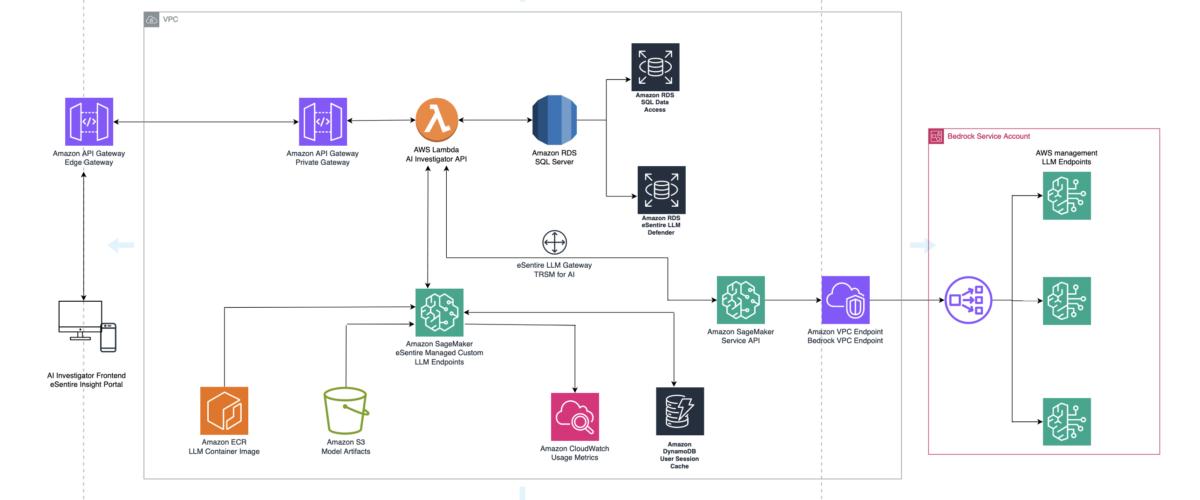
The following diagram visualizes the architecture diagram and workflow.

The application’s frontend is accessible through Amazon API Gateway, using both edge and private gateways. To emulate intricate thought processes akin to those of a human investigator, eSentire engineered a system of chained agent actions. This system uses AWS Lambda and Amazon DynamoDB to orchestrate a series of LLM invocations. Each LLM call builds upon the previous one, creating a cascade of interactions that collectively produce high-quality responses. This intricate setup makes sure that the application’s backend data sources are seamlessly integrated, thereby providing tailored responses to customer inquiries.
When a SageMaker endpoint is constructed, an S3 URI to the bucket containing the model artifact and Docker image is shared using Amazon ECR.
For their proof of concept, eSentire selected the Nvidia A10G Tensor Core GPU housed in an MLG5 2XL instance for its balance of performance and cost. For LLMs with significantly larger numbers of parameters, which demand greater computational power for both training and inference tasks, eSentire used 12XL instances equipped with four GPUs. This was necessary because the computational complexity and the amount of memory required for LLMs can increase exponentially with the number of parameters. eSentire plans to harness P4 and P5 instance types for scaling their production workloads.
Additionally, a monitoring framework that captures the inputs and outputs of AI Investigator was necessary to enable threat hunting visibility to LLM interactions. To accomplish this, the application integrates with an open sourced eSentire LLM Gateway project to monitor the interactions with customer queries, backend agent actions, and application responses. This framework enables confidence in complex LLM applications by providing a security monitoring layer to detect malicious poisoning and injection attacks while also providing governance and support for compliance through logging of user activity. The LLM gateway can also be integrated with other LLM services, such as Amazon Bedrock.
Amazon Bedrock enables you to customize FMs privately and interactively, without the need for coding. Initially, eSentire’s focus was on training bespoke models using SageMaker. As their strategy evolved, they began to explore a broader array of FMs, evaluating their in-house trained models against those provided by Amazon Bedrock. Amazon Bedrock offers a practical environment for benchmarking and a cost-effective solution for managing workloads due to its serverless operation. This serves eSentire well, especially when customer queries are sporadic, making serverless an economical alternative to persistently running SageMaker instances.
From a security perspective as well, Amazon Bedrock doesn’t share users’ inputs and model outputs with any model providers. Additionally, eSentire have custom guardrails for NL2SQL applied to their models.
Results
The following screenshot shows an example of eSentire’s AI Investigator output. As illustrated, a natural language query is posed to the application. The tool is able to correlate multiple datasets and present a response.

Dustin Hillard, CTO of eSentire, shares: “eSentire customers and analysts ask hundreds of security data exploration questions per month, which typically take hours to complete. AI Investigator is now with an initial rollout to over 100 customers and more than 100 SOC analysts, providing a self-serve immediate response to complex questions about their security data. eSentire LLM models are saving thousands of hours of customer and analyst time.”
Conclusion
In this post, we shared how eSentire built AI Investigator, a generative AI solution that provides private and secure self-serve customer interactions. Customers can get near real-time answers to complex questions about their data. AI Investigator has also saved eSentire significant analyst time.
The aforementioned LLM gateway project is eSentire’s own product and AWS bears no responsibility.
If you have any comments or questions, share them in the comments section.
About the Authors
 Aishwarya Subramaniam is a Sr. Solutions Architect in AWS. She works with commercial customers and AWS partners to accelerate customers’ business outcomes by providing expertise in analytics and AWS services.
Aishwarya Subramaniam is a Sr. Solutions Architect in AWS. She works with commercial customers and AWS partners to accelerate customers’ business outcomes by providing expertise in analytics and AWS services.
 Ilia Zenkov is a Senior AI Developer specializing in generative AI at eSentire. He focuses on advancing cybersecurity with expertise in machine learning and data engineering. His background includes pivotal roles in developing ML-driven cybersecurity and drug discovery platforms.
Ilia Zenkov is a Senior AI Developer specializing in generative AI at eSentire. He focuses on advancing cybersecurity with expertise in machine learning and data engineering. His background includes pivotal roles in developing ML-driven cybersecurity and drug discovery platforms.
 Dustin Hillard is responsible for leading product development and technology innovation, systems teams, and corporate IT at eSentire. He has deep ML experience in speech recognition, translation, natural language processing, and advertising, and has published over 30 papers in these areas.
Dustin Hillard is responsible for leading product development and technology innovation, systems teams, and corporate IT at eSentire. He has deep ML experience in speech recognition, translation, natural language processing, and advertising, and has published over 30 papers in these areas.
Author: Aishwarya Subramaniam