

Evaluating prompts at scale with Prompt Management and Prompt Flows for Amazon Bedrock
As generative artificial intelligence (AI) continues to revolutionize every industry, the importance of effective prompt optimization through prompt engineering techniques has become key to efficiently balancing the quality of outputs, response time, and costs… A high-quality prompt maximizes the …
As generative artificial intelligence (AI) continues to revolutionize every industry, the importance of effective prompt optimization through prompt engineering techniques has become key to efficiently balancing the quality of outputs, response time, and costs. Prompt engineering refers to the practice of crafting and optimizing inputs to the models by selecting appropriate words, phrases, sentences, punctuation, and separator characters to effectively use foundation models (FMs) or large language models (LLMs) for a wide variety of applications. A high-quality prompt maximizes the chances of having a good response from the generative AI models.
A fundamental part of the optimization process is the evaluation, and there are multiple elements involved in the evaluation of a generative AI application. Beyond the most common evaluation of FMs, the prompt evaluation is a critical, yet often challenging, aspect of developing high-quality AI-powered solutions. Many organizations struggle to consistently create and effectively evaluate their prompts across their various applications, leading to inconsistent performance and user experiences and undesired responses from the models.
In this post, we demonstrate how to implement an automated prompt evaluation system using Amazon Bedrock so you can streamline your prompt development process and improve the overall quality of your AI-generated content. For this, we use Amazon Bedrock Prompt Management and Amazon Bedrock Prompt Flows to systematically evaluate prompts for your generative AI applications at scale.
The importance of prompt evaluation
Before we explain the technical implementation, let’s briefly discuss why prompt evaluation is crucial. The key aspects to consider when building and optimizing a prompt are typically:
- Quality assurance – Evaluating prompts helps make sure that your AI applications consistently produce high-quality, relevant outputs for the selected model.
- Performance optimization – By identifying and refining effective prompts, you can improve the overall performance of your generative AI models in terms of lower latency and ultimately higher throughput.
- Cost efficiency – Better prompts can lead to more efficient use of AI resources, potentially reducing costs associated with model inference. A good prompt allows for the use of smaller and lower-cost models, which wouldn’t give good results with a bad quality prompt.
- User experience – Improved prompts result in more accurate, personalized, and helpful AI-generated content, enhancing the end user experience in your applications.
Optimizing prompts for these aspects is an iterative process that requires an evaluation for driving the adjustments in the prompts. It is, in other words, a way to understand how good a given prompt and model combination are for achieving the desired answers.
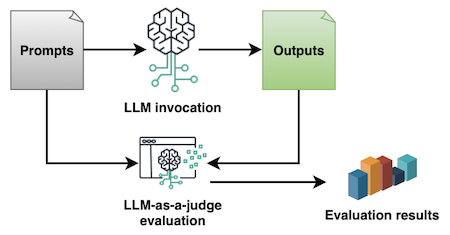
In our example, we implement a method known as LLM-as-a-judge, where an LLM is used for evaluating the prompts based on the answers it produced with a certain model, according to predefined criteria. The evaluation of prompts and their answers for a given LLM is a subjective task by nature, but a systematic prompt evaluation using LLM-as-a-judge allows you to quantify it with an evaluation metric in a numerical score. This helps to standardize and automate the prompting lifecycle in your organization and is one of the reasons why this method is one of the most common approaches for prompt evaluation in the industry.

Let’s explore a sample solution for evaluating prompts with LLM-as-a-judge with Amazon Bedrock. You can also find the complete code example in amazon-bedrock-samples.
Prerequisites
For this example, you need the following:
- An AWS account and a user with an AWS Identity and Access Management (IAM) role authorized to use Amazon Bedrock. For guidance, refer to the instructions in Getting started with Amazon Bedrock. Make sure the role includes the permissions for using Prompt Flows for Amazon Bedrock, as explained in Prerequisites for Prompt flows for Amazon Bedrock.
- Access provided to the models you use for invocation and evaluation. For guidance, follow the instructions in Manage access to Amazon Bedrock foundation models.
Set up the evaluation prompt
To create an evaluation prompt using Amazon Bedrock Prompt Management, follow these steps:
- On the Amazon Bedrock console, in the navigation pane, choose Prompt management and then choose Create prompt.
- Enter a Name for your prompt such as
prompt-evaluatorand a Description such as “Prompt template for evaluating prompt responses with LLM-as-a-judge.” Choose Create.

- In the Prompt field, write your prompt evaluation template. In the example, you can use a template like the following or adjust it according to your specific evaluation requirements.
- Under Configurations, select a model to use for running evaluations with the prompt. In our example we selected Anthropic Claude Sonnet. The quality of the evaluation will depend on the model you select in this step. Make sure you balance the quality, response time, and cost accordingly in your decision.
- Set the Inference parameters for the model. We recommend that you keep Temperature as 0 for making a factual evaluation and to avoid hallucinations.
You can test your evaluation prompt with sample inputs and outputs using the Test variables and Test window panels.
- Now that you have a draft of your prompt, you can also create versions of it. Versions allow you to quickly switch between different configurations for your prompt and update your application with the most appropriate version for your use case. To create a version, choose Create version at the top.
The following screenshot shows the Prompt builder page.

Set up the evaluation flow
Next, you need to build an evaluation flow using Amazon Bedrock Prompt Flows. In our example, we use prompt nodes. For more information on the types of nodes supported, check the Node types in prompt flow documentation. To build an evaluation flow, follow these steps:
- On the Amazon Bedrock console, under Prompt flows, choose Create prompt flow.
- Enter a Name such as
prompt-eval-flow. Enter a Description such as “Prompt Flow for evaluating prompts with LLM-as-a-judge.” Choose Use an existing service role to select a role from the dropdown. Choose Create. - This will open the Prompt flow builder. Drag two Prompts nodes to the canvas and configure the nodes as per the following parameters:
- Flow input
- Output:
- Name:
document, Type: String
- Name:
- Output:
- Invoke (Prompts)
- Node name:
Invoke - Define in node
- Select model: A preferred model to be evaluated with your prompts
- Message:
{{input}} - Inference configurations: As per your preferences
- Input:
- Name:
input, Type: String, Expression:$.data
- Name:
- Output:
- Name:
modelCompletion, Type: String
- Name:
- Node name:
- Evaluate (Prompts)
- Node name:
Evaluate - Use a prompt from your Prompt Management
- Prompt:
prompt-evaluator - Version: Version 1 (or your preferred version)
- Select model: Your preferred model to evaluate your prompts with
- Inference configurations: As set in your prompt
- Input:
- Name:
input, Type: String, Expression:$.data - Name:
output, Type: String, Expression:$.data
- Name:
- Output
- Name:
modelCompletion, Type: String
- Name:
- Node name:
- Flow output
- Node name:
End - Input:
- Name:
document, Type: String, Expression:$.data
- Name:
- Node name:
- Flow input
- To connect the nodes, drag the connecting dots, as shown in the following diagram.

- Choose Save.
You can test your prompt evaluation flow by using the Test prompt flow panel. Pass an input, such as the question, “What is cloud computing in a single paragraph?” It should return a JSON with the result of the evaluation similar to the following example. In the code example notebook, amazon-bedrock-samples, we also included the information about the models used for invocation and evaluation to our result JSON.
As the example shows, we asked the FM to evaluate with separate scores the prompt and the answer the FM generated from that prompt. We asked it to provide a justification for the score and some recommendations to further improve the prompts. All this information is valuable for a prompt engineer because it helps guide the optimization experiments and helps them make more informed decisions during the prompt life cycle.
Implementing prompt evaluation at scale
To this point, we’ve explored how to evaluate a single prompt. Often, medium to large organizations work with tens, hundreds, and even thousands of prompt variations for their multiple applications, making it a perfect opportunity for automation at scale. For this, you can run the flow in full datasets of prompts stored in files, as shown in the example notebook.
Alternatively, you can also rely on other node types in Amazon Bedrock Prompt Flows for reading and storing in Amazon Simple Storage Service (Amazon S3) files and implementing iterator and collector based flows. The following diagram shows this type of flow. Once you have established a file-based mechanism for running the prompt evaluation flow on datasets at scale, you can also automate the whole process by connecting it your preferred continuous integration and continuous development (CI/CD) tools. The details for these are out of the scope of this post.

Best practices and recommendations
Based on our evaluation process, here are some best practices for prompt refinement:
- Iterative improvement – Use the evaluation feedback to continuously refine your prompts. The prompt optimization is ultimately an iterative process.
- Context is key – Make sure your prompts provide sufficient context for the AI model to generate accurate responses. Depending on the complexity of the tasks or questions that your prompt will answer, you might need to use different prompt engineering techniques. You can check the Prompt engineering guidelines in the Amazon Bedrock documentation and other resources on the topic provided by the model providers.
- Specificity matters – Be as specific as possible in your prompts and evaluation criteria. Specificity guides the models towards desired outputs.
- Test edge cases – Evaluate your prompts with a variety of inputs to verify robustness. You might also want to run multiple evaluations on the same prompt for comparing and testing output consistency, which might be important depending on your use case.
Conclusion and next steps
By using the LLM-as-a-judge method with Amazon Bedrock Prompt Management and Amazon Bedrock Prompt Flows, you can implement a systematic approach to prompt evaluation and optimization. This not only improves the quality and consistency of your AI-generated content but also streamlines your development process, potentially reducing costs and improving user experiences.
We encourage you to explore these features further and adapt the evaluation process to your specific use cases. As you continue to refine your prompts, you’ll be able to unlock the full potential of generative AI in your applications. To get started, check out the full with the code samples used in this post. We’re excited to see how you’ll use these tools to enhance your AI-powered solutions!
For more information on Amazon Bedrock and its features, visit the Amazon Bedrock documentation.
About the Author

Antonio Rodriguez is a Sr. Generative AI Specialist Solutions Architect at Amazon Web Services. He helps companies of all sizes solve their challenges, embrace innovation, and create new business opportunities with Amazon Bedrock. Apart from work, he loves to spend time with his family and play sports with his friends.
Author: Antonio Rodriguez