

Fine-tune large multimodal models using Amazon SageMaker
Large multimodal models (LMMs) integrate multiple data types into a single model… By combining text data with images and other modalities during training, multimodal models such as Claude3, GPT-4V, and Gemini Pro Vision gain more comprehensive understanding and improved ability to process diverse …
Large multimodal models (LMMs) integrate multiple data types into a single model. By combining text data with images and other modalities during training, multimodal models such as Claude3, GPT-4V, and Gemini Pro Vision gain more comprehensive understanding and improved ability to process diverse data types. The multimodal approach allows models to handle a wider range of real-world tasks that involve both text and non-text inputs. In this way, multimodality helps overcome the restrictions of pure text models. LMMs have the potential to profoundly impact various industries, such as healthcare, business analysis, autonomous driving, and so on.
However, a general-purpose language model can only process relatively simple visual tasks such as answering basic questions about an image or generating short captions. This is primarily due to the lack of access to detailed pixel-level information, object segmentation data, and other granular annotations that would allow the model to precisely understand and reason about the various elements, relationships, and context within an image. Without this fine-grained visual understanding, the language model is constrained to more superficial, high-level analysis and generation capabilities related to images. Fine-tuning LMMs on domain-specific data can significantly improve their performance for targeted tasks. The prospect of fine-tuning open source multimodal models like LLaVA are highly appealing because of their cost effectiveness, scalability, and impressive performance on multimodal benchmarks. For those seeking flexible and economical solutions, the ability to use and customize these powerful models holds immense potential.
In this blog post, we demonstrate how to fine-tune and deploy the LLaVA model on Amazon SageMaker. The source code is available in this GitHub repository.
LLaVA overview
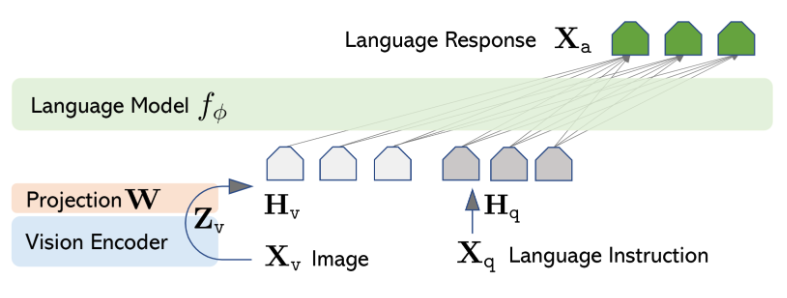
LLaVA is trained end-to-end to enable general-purpose understanding across both visual and textual data. In the LLaVA model architecture, pre-trained language models such as Vicuna or LLaMA are combined with visual models such as CLIP’s visual encoder. The integration converts the visual features from images into a format that matches the language model’s embeddings through a projection layer.
LLaVA training happens in two stages, as shown in Figure 1 that follows. The first stage is pre-training, which uses image-text pairs to align the visual features with the language model’s embeddings. In this stage, the visual encoder and language model weights are kept frozen, and only the projection matrix is trained. The second stage is fine-tuning the whole model end-to-end. Here, the visual encoder’s weights are frozen, while the projection layer and language model are updated.

Figure 1: LLaVA architecture
Prepare data
When it comes to fine-tuning the LLaVA model for specific tasks or domains, data preparation is of paramount importance because having high-quality, comprehensive annotations enables the model to learn rich representations and achieve human-level performance on complex visual reasoning challenges. In this post, we focus on preparing an instruction dataset.
Data annotation
The dataset should contain image text pairs that involve reasoning to answer questions about images. To help the model gain comprehensive understanding during the training process, text data should be enriched with contextual nuances. For example, instead of simply asking the model to describe the image, ask specific questions about the image and relating to its content.
To demonstrate LLaVA’s capabilities, we created a small synthetic dataset focused on understanding and interpreting infographics and charts. We used Amazon Bedrock and Python for this task. Specifically, we employed the Amazon Bedrock LLaMA2-70B model to generate text descriptions and question-answer pairs based on those descriptions. Subsequently, we used Python to generate different types of visual presentation such as pie charts and funnel charts based on the text descriptions. If you already have an existing dataset, this method can be used as a data augmentation technique to expand your dataset and potentially enhance the fine-tuning outcome. By creating synthetic examples of text descriptions, question-answer pairs, and corresponding charts, you can augment your dataset with multimodal examples tailored to your specific use case.
The dataset we created consists of image-text pairs, with each image being an infographic, chart, or other data visualization. The corresponding text is a series of questions about the infographic along with ground truth answers, formatted in a question-answer style intended to resemble how a human might ask the model about the information contained in the image. Some examples of generated questions for images as shown in Figure 2 include:
- What is the percentage of people who spend less than 2 hours a day on screen time?
- What proportion of people do not exercise at all weekly?
- How many people are teachers?

Figure 2: Example charts in the training dataset (left is a pie chart of distribution of daily screen time, right is a funnel chart of occupation)
Data structure
These image-text pairs must be formatted in JSON lines (.jsonl) format, where each line is a training sample. An example training sample follows. Specifically, the id field is the unique identifier of a training sample, the image field specifies the name of the image, and the conversations field provides a question-and-answer pair.
By training the model to answer in-depth and analytical questions about infographics it hasn’t seen before, we aim to strengthen model’s ability to generalize its understanding of data visualizations and draw accurate insights.
Fine tune the model
After the data is prepared, we upload it to Amazon Simple Storage Service (Amazon S3) as the SageMaker training input. In configuring the SageMaker training job, we use the TrainingInput object to specify the input data location in Amazon S3 and define how SageMaker should handle it during training. In this case, input_mode='FastFile' indicates the use of S3 fast file mode, which is ideal for scenarios where the dataset is stored as individual files in S3. S3 fast file mode is also advantageous when working with large datasets or when fast access to data is critical for training performance.
We will reuse the training script from LLaVA, which uses DeepSpeed for training efficiency. DeepSpeed is a library that helps train very large deep learning models faster and more efficiently. ZeRO, short for Zero Redundancy Optimizer, is a memory optimization technique in DeepSpeed that reduces the required memory footprint for data parallelism by partitioning optimization states and gradients across data-parallel processes, enabling larger model sizes and batch sizes within limited GPU memory. This allows you to train much larger models on the same hardware. ZeRO Stage 2 reduces memory usage by splitting the model’s optimizer state, gradients, and parameters across multiple processes. Each process only stores a part of these, reducing the memory needed per process. If you run into CUDA memory errors with this configuration, try the Stage 3 configuration instead. Stage 3 offloads gradients to the CPU, which slows training but might solve the memory issue. The training command follows. See the LLaVA: Large Language and Vision Assistant on GitHub for more details about the training parameters
LLaVA allows you to fine-tune all parameters of the base model or use LoRA to tune a smaller number of parameters. LoRA’s strategy keeps the original pre-trained model backbone unchanged and adds new, easier-to-train layers. This allows quick adaptation to new tasks without retraining the whole network. You can use the lora_enable parameter to specify the fine-tuning method. For full parameter fine-tuning, ml.p4d.24xlarge is recommended, while ml.g5.12xlarge is sufficient for LoRA fine-tuning if LLaMA-13B language model is used.
The following code initializes a SageMaker Estimator using the HuggingFace SDK. It sets up a SageMaker training job to run the custom training script from LLaVA. This allows the script to be run within the SageMaker managed environment, benefiting from its scalability. Then we bring our own Docker container to run the SageMaker training job. You can download the Docker image from this code repo, where the dependencies of the training LLaVA model are installed. To learn more about how to adapt your own Docker container to work with SageMaker, see adapting your own training container.
For logging purpose, you can use metric definitions to extract key metrics from the training script’s printed logs and send them to Amazon CloudWatch. The following is an example metric definition that logs training loss at each epoch, the model’s learning rate, and training throughput.
Deploy and test
After the training job finishes, the fine-tuned model is uploaded to Amazon S3. You can then use the following code to deploy the model on SageMaker.
For testing, provide an image and question pair and make an inference call against the SageMaker endpoint as follows:
Conclusion
Our exploration into fine-tuning the LLaVA visual language model on Sagemaker for a custom visual question answering task has shed light on the advancements made in bridging the gap between textual and visual comprehension. LLaVA represents a significant step forward in multimodal AI, demonstrating the ability to jointly understand and reason about textual and visual information in a unified model. By using large-scale pretraining on image-text pairs, LLaVA has acquired robust visiolinguistic representations that can be effectively adapted to downstream tasks through fine-tuning. This enables LLaVA to excel at tasks that require deep comprehension of both modalities, such as visual question answering, image captioning, and multimodal information retrieval. However, the fine-tuning mechanism has limitations. In particular, the adjustment of the projection layer and language model themselves while freezing the vision model presents a set of challenges, such as the requirement for a massive amount of data and the lack of capability in handling challenging vision tasks. Confronting these challenges directly allows us to unlock the full potential of multimodal models, paving the way for more sophisticated applications.
Acknowledgement
The authors extend their gratitude to Manoj Ravi, Jenny Vega, and Santhosh Kuriakose for their insightful feedback and review of the post.
Reference
About the Authors
 Dr. Changsha Ma is an AI/ML Specialist at AWS. She is a technologist with a PhD in Computer Science, a master’s degree in Education Psychology, and years of experience in data science and independent consulting in AI/ML. She is passionate about researching methodological approaches for machine and human intelligence. Outside of work, she loves hiking, cooking, hunting food, and spending time with friends and families.
Dr. Changsha Ma is an AI/ML Specialist at AWS. She is a technologist with a PhD in Computer Science, a master’s degree in Education Psychology, and years of experience in data science and independent consulting in AI/ML. She is passionate about researching methodological approaches for machine and human intelligence. Outside of work, she loves hiking, cooking, hunting food, and spending time with friends and families.
 Jun Shi is a Senior Solutions Architect at Amazon Web Services (AWS). His current areas of focus are AI/ML infrastructure and applications. He has over a decade experience in the FinTech industry as software engineer.
Jun Shi is a Senior Solutions Architect at Amazon Web Services (AWS). His current areas of focus are AI/ML infrastructure and applications. He has over a decade experience in the FinTech industry as software engineer.
 Alfred Shen is a Senior AI/ML Specialist at AWS. He has been working in Silicon Valley, holding technical and managerial positions in diverse sectors including healthcare, finance, and high-tech. He is a dedicated applied AI/ML researcher, concentrating on CV, NLP, and multimodality. His work has been showcased in publications such as EMNLP, ICLR, and Public Health.
Alfred Shen is a Senior AI/ML Specialist at AWS. He has been working in Silicon Valley, holding technical and managerial positions in diverse sectors including healthcare, finance, and high-tech. He is a dedicated applied AI/ML researcher, concentrating on CV, NLP, and multimodality. His work has been showcased in publications such as EMNLP, ICLR, and Public Health.
Author: Changsha Ma