

Foundational data protection for enterprise LLM acceleration with Protopia AI
New and powerful large language models (LLMs) are changing businesses rapidly, improving efficiency and effectiveness for a variety of enterprise use cases… AWS is especially well suited to provide enterprises the tools necessary for deploying LLMs at scale to enable critical decision-making… …
This post is written in collaboration with Balaji Chandrasekaran, Jennifer Cwagenberg and Andrew Sansom and Eiman Ebrahimi from Protopia AI.
New and powerful large language models (LLMs) are changing businesses rapidly, improving efficiency and effectiveness for a variety of enterprise use cases. Speed is of the essence, and adoption of LLM technologies can make or break a business’s competitive advantage. AWS is especially well suited to provide enterprises the tools necessary for deploying LLMs at scale to enable critical decision-making.
In their implementation of generative AI technology, enterprises have real concerns about data exposure and ownership of confidential information that may be sent to LLMs. These concerns of privacy and data protection can slow down or limit the usage of LLMs in organizations. Enterprises need a responsible and safer way to send sensitive information to the models without needing to take on the often prohibitively high overheads of on-premises DevOps.
The post describes how you can overcome the challenges of retaining data ownership and preserving data privacy while using LLMs by deploying Protopia AI’s Stained Glass Transform to protect your data. Protopia AI has partnered with AWS to deliver the critical component of data protection and ownership for secure and efficient enterprise adoption of generative AI. This post outlines the solution and demonstrates how it can be used in AWS for popular enterprise use cases like Retrieval Augmented Generation (RAG) and with state-of-the-art LLMs like Llama 2.
Stained Glass Transform overview
Organizations seek to retain full ownership and control of their sensitive enterprise data. This is a pillar of responsible AI and an emerging data protection and privacy requirement above and beyond basic security and legal guarantees of LLM providers.
Although enterprise business units want to utilize LLMs for various tasks, they are also concerned about trade secrets, intellectual property, and other proprietary information leaking through data sent to these models. At the same time, enterprise security, compliance, data management, and information offices are apprehensive of exposing or leaking plain text customer information or other regulated data outside of the enterprise. AWS and Protopia AI are partnering to deliver the critical component that solves this common enterprise customer need.
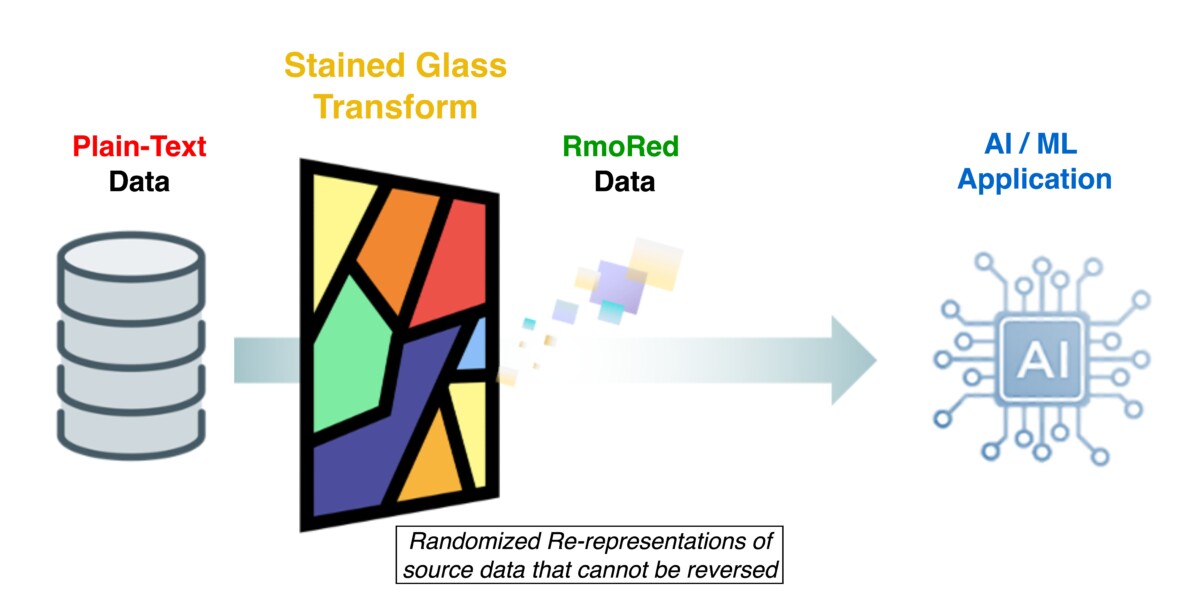
Protopia AI’s Stained Glass Transform (SGT) solves these challenges by converting unprotected enterprise data to a randomized re-representation, referred to as RmoRed data, as shown in the following figure. This representation is a stochastic embedding of the original data, preserving the information the target LLM needs to function without exposing sensitive prompts or queries, context, or fine-tuning data. This re-representation is a one-way transformation that can’t be reversed, ensuring holistic privacy of enterprise data and protection against leaking plain text sensitive information to LLMs. SGT’s applicability is not limited to language models. Randomized re-representations can also be generated for visual and structured data. The name Stained Glass Transform is rooted in the visual appearance of randomized re-representations of visual data that can resemble viewing the data through stained glass, as demonstrated in this US Navy use case.

SGT works with state-of-the-art LLMs such as Llama 2. The following figure shows an example of applying SGT to a Llama 2 model for instruction following while adding a layer of protection to the instruction and context. The left side of the figure shows an example of a financial document as context, with the instruction asking the model to summarize the document. On the bottom left, the response generated by Llama 2 when operating on the raw prompt is shown. When using SGT, the embeddings associated with this prompt are transformed on the client side into stochastic embeddings, as described in more detail later in this post. The bottom right shows Llama 2 can still generate a correct response if the RmoRed data (post-transformation embeddings) are sent instead of the unprotected embeddings. The top right shows that if the RmoRed data leaked, a reconstruction of the original prompt would result in unintelligible text.

To create an SGT for a given model such as Llama 2, Protopia AI provides a lightweight library called the Stained Glass SDK, which is an extension of PyTorch. As shown in the following figure, after an SGT is created, it can be integrated into deployment pipelines in multiple ways. The transform that is created from the SDK can be deployed locally, in a hybrid setup, or completely on the cloud. This is possible because SGT is designed to be a lightweight process requiring very little compute resources and as such has minimal impact on the inference critical path. Another key evaluation is retention of model accuracy using re-represented data. We observe that across different data types and model variations, accuracy is retained within desirable tolerance limits when using re-represented data.

These options for deployment and maintaining the accuracy allows for confident adoption of SGT by all the stakeholders within an enterprise organization. To further protect the output of the LLM, Protopia AI can encode query outputs to a representation whose decoder is only available to the enterprise data owner.
Solution overview
The previous section described how you can use Stained Glass Transform in a variety of architectures. The following figure details the steps involved in creating, deploying, and using SGT for LLMs:
- SGT creation – The team that trains the baseline LLM foundation model (providers of proprietary LLMs, cloud service provider, or enterprise ML teams creating their own LLMs) runs Protopia AI’s Stained Glass SDK software without altering their existing practices for training and deploying the LLM. After the foundation model training is complete, the SDK runs as an optimization pass over the language model to compute the SGT. This optimization pass is delivered through an extension to PyTorch. The SDK wraps the foundation model and mathematically discovers a unique Stained Glass Transform for that LLM. Further details of the underlying math can be found in the accompanying whitepaper. Note that because the team training the LLM itself is also running the Stained Glass SDK, there is no exposure or sending of model weights that is necessary for this step to be completed.
- SGT release and deployment – The SGT that is output from the earlier optimization step is deployed as part of the data pipeline that feeds the trained LLM. As described in the previous section, the SGT sits on the enterprise client side.
- SGT use – The SGT runs on the prompts created by the enterprise and generates protected prompts, which are sent to the deployed LLM. This enables the enterprise to retain ownership of their sensitive queries and context. Using Protopia AI Stained Glass, the unprotected sensitive data does not leave the enterprise’s site or trust zone.

You can use the Stained Glass SDK to create an SGT in multiple ways. For example, you can use the Stained Glass SDK in self-managed machine learning (ML) environments with Amazon Elastic Kubernetes Service (Amazon EKS) for training and inferencing or within Amazon Elastic Compute Cloud (Amazon EC2) directly. Another option is it can run within Amazon SageMaker to create an SGT for a given trained model. Transforming the input for deployment during inference from the client is independent of the chosen deployment implementation.
The following figure illustrates a possible implementation in a self-managed ML environment where training a Stained Glass Transform is performed on Amazon EKS.

In this workflow, a container is created using the Stained Glass SDK and deployed to Amazon Elastic Container Registry (Amazon ECR). This container is then deployed on Amazon EKS to train an SGT that is saved to Amazon Simple Storage Service (Amazon S3). If you’re using Amazon EC2, you can train a transformation directly on your instance as part of your ML setup. The Stained Glass SDK can run on a variety of instance types, including Amazon P5, P4, or G5 instance families, based on your base LLM requirements. After the LLM is deployed to be used for inference, the client application uses the created SGT, which is a lightweight operation, to transform prompts and context before sending them to the LLM. By doing so, only transformed data is exposed to the LLM, and ownership of the original input is retained on the client side.
The following figure demonstrates how you can train a transform and run inferencing on SageMaker.

The creation of the SGT follows a similar path as the Amazon EKS setup by ingesting the training data from Amazon S3, training an SGT on a container, and saving it to Amazon S3. You can use the Stained Glass SDK in your existing SageMaker setup with Amazon SageMaker Studio, SageMaker notebooks, and a SageMaker training job. The LLM is hosted as a SageMaker endpoint that is accessible by the client application. The inferencing for the client application is also identical to the Amazon EKS setup, except for what is serving the model.
Randomized re-representations to protect LLM prompts and fine-tuning data
This section covers a variety of use cases demonstrating how randomized re-representation protects LLM prompts. The examples illustrate major implications for enterprise generative AI efforts: opening new doors to AI use cases, accelerating speed to market while properly protecting enterprise data, and retaining ownership of the sensitive data required for use in LLM prompts.
RAG use case
A popular enterprise use case for LLMs is Retrieval Augmented Generation (RAG). The following figure shows an illustrative example where the prompts and sources are protected using Stained Glass. The left side of the figure shows the unprotected prompts and source information. In an enterprise implementation of RAG, the sources could include sensitive information such as enterprise trade secrets, intellectual property, or financial information. The right side shows the best possible reconstruction in human readable text from the RmoRed prompts created by the SGT.

We can observe that even in the best possible reconstruction, the information is completely obfuscated. However, the response from the model with and without the transformation is the same, with pointers to the original source documents, thereby preserving the accuracy of both the question and source documents while performing this popular enterprise use case.
Broad applicability across LLMs and languages
One of the highlights of the Stained Glass SDK is that it’s highly resilient to model advancements and adaptable to state-of-the-art models such as Llama 2. The following figure shows an SGT that was created on a Llama 2 LLM that was previously fine-tuned for working with Japanese text. This example further illustrates that SGTs can be created and applied for any language and that even inputs for fine-tuned models can be transformed. The general applicability of SGT is driven by the robust foundation of the Stained Glass SDK being model- and data-agnostic.

Protecting fine-tuning data as well as prompts
Stained Glass Transform is not limited solely to protecting data at inference time; it can also protect data used to fine-tune a foundation model. The process for creating the transformation for fine-tuning datasets is the same as that explained in the solution architecture section earlier in this post. The transformation is created for the foundation model to be fine-tuned without accessing the fine-tuning data. After the SGT has been created and trained for the foundation model, the fine-tuning dataset is transformed to randomized re-representations that will then be used to fine-tune the foundation model. This process is explained in more detail in the accompanying whitepaper.
In the following example, an enterprise customer needed to fine-tune an existing model for network log anomaly detection. They used Stained Glass to transform the sensitive fine-tuning dataset to randomized embeddings, which were used to fine-tune their foundation model. They found that the detection model that was fine-tuned on the transformed representations performed with almost identical accuracy compared to the hypothetical scenario of fine-tuning the foundation model on the unprotected fine-tuning dataset. The following table shows two examples of plain text data records from the fine-tuning dataset and a reconstruction to text of those same data records from the fine-tuning dataset.

Under the hood of Stained Glass Transform for LLMs
When applied to computer vision, SGT operates on input pixel features, and for LLMs, it operates at the embedding level. To highlight how Stained Glass Transform works, imagine the prompt embeddings as a matrix, as illustrated on the left of the following figure. In each entry, there is a deterministic value. This value can be mapped to the original data, exposing the unprotected prompt. Stained Glass Transform converts this matrix of deterministic values to a matrix whose elements are a cloud of possibilities.

The transformed prompt is rendered by sampling noise from probability distributions defined by the SGT and adding the sampled noise to the deterministic embeddings, which randomizes the original prompt values irreversibly. The model still understands the randomized re-represented prompt at the mathematical level and can carry out its task accurately.
Conclusion
This post discussed how Protopia AI’s Stained Glass Transform decouples raw data ownership and protection from the ML operations process, enabling enterprises to retain ownership and maintain privacy of sensitive information in LLM prompts and fine-tuning data. By using this state-of-the-art data protection for LLM usage, enterprises can accelerate adoption of foundation models and LLMs by worrying less about exposure of sensitive information. By safely unlocking the value in real enterprise data, organizations can enable the promised efficiencies and business outcomes of LLMs more efficiently and quickly. To learn more about this technology, you can find further reading in the accompanying whitepaper and connect with Protopia AI to get access and try it on your enterprise data.
About Protopia AI
Protopia AI is a leader in data protection and privacy-preserving AI/ML technologies based in Austin, Texas, and specializes in enabling AI algorithms and software platforms to operate without the need to access plain text information. Over the past 2 years, Protopia AI has successfully demonstrated its flagship Stained Glass Transform product across a variety of ML use cases and data types with the US Navy, leading financial services, and global technology providers.
Protopia AI works with enterprises, generative AI and LLM providers, and Cloud Service Providers (CSPs) to enable maintaining ownership and confidentiality of enterprise data while using AI/ML solutions. Protopia AI has partnered with AWS to deliver a critical component of data protection and ownership for enterprise adoption of generative AI, and was one of 21 startups selected for the inaugural AWS Generative AI Accelerator in 2023.
About the authors
 Balaji Chandrasekaran is the VP for Go-to-Market & Customer Enablement at Protopia AI, works closely with clients to leverage AI in their business while prioritizing data protection and privacy. Prior to Protopia AI, Balaji was the Product Lead for AI Solutions at Infor, developing value-centric products while acting as a trusted partner for enterprise customers across diverse industries. Outside work, he enjoys music, hiking, and traveling with family.
Balaji Chandrasekaran is the VP for Go-to-Market & Customer Enablement at Protopia AI, works closely with clients to leverage AI in their business while prioritizing data protection and privacy. Prior to Protopia AI, Balaji was the Product Lead for AI Solutions at Infor, developing value-centric products while acting as a trusted partner for enterprise customers across diverse industries. Outside work, he enjoys music, hiking, and traveling with family.
 Jennifer Cwagenberg leads the engineering team at Protopia AI and works to ensure that the Stained Glass technology meets the needs of their customers to protect their data. Jennifer has prior experience with security working at Toyota in their Product Cybersecurity Group, managing Cloud workloads at N-able, and responsible for data at Match.com.
Jennifer Cwagenberg leads the engineering team at Protopia AI and works to ensure that the Stained Glass technology meets the needs of their customers to protect their data. Jennifer has prior experience with security working at Toyota in their Product Cybersecurity Group, managing Cloud workloads at N-able, and responsible for data at Match.com.
 Andrew Sansom is an AI Solutions Engineer at Protopia AI where he helps enterprises use AI while preserving private and sensitive information in their data. Prior to Protopia AI, he worked as a Technical Consultant focused on enabling AI solutions for clients across many industries including Finance, Manufacturing, Healthcare, and Education. He also taught Computer Science and Math to High School, University, and Professional students.
Andrew Sansom is an AI Solutions Engineer at Protopia AI where he helps enterprises use AI while preserving private and sensitive information in their data. Prior to Protopia AI, he worked as a Technical Consultant focused on enabling AI solutions for clients across many industries including Finance, Manufacturing, Healthcare, and Education. He also taught Computer Science and Math to High School, University, and Professional students.
 Eiman Ebrahimi, PhD, is a co-founder and the Chief Executive Officer of Protopia AI. Dr. Ebrahimi is passionate about enabling AI to enrich the human experience across different societal and industry verticals. Protopia AI is a vision for enhancing the lens through which AI observes the necessary and quality data it needs while creating novel capabilities for safeguarding sensitive information. Prior to Protopia AI, he was a Senior Research Scientist at NVIDIA for 9 years. His work at NVIDIA research aimed to solve problems of accessing massive datasets in ML/AI. He also co-authored peer-reviewed publications on how to utilize the power of thousands of GPUs to make training large language models feasible.
Eiman Ebrahimi, PhD, is a co-founder and the Chief Executive Officer of Protopia AI. Dr. Ebrahimi is passionate about enabling AI to enrich the human experience across different societal and industry verticals. Protopia AI is a vision for enhancing the lens through which AI observes the necessary and quality data it needs while creating novel capabilities for safeguarding sensitive information. Prior to Protopia AI, he was a Senior Research Scientist at NVIDIA for 9 years. His work at NVIDIA research aimed to solve problems of accessing massive datasets in ML/AI. He also co-authored peer-reviewed publications on how to utilize the power of thousands of GPUs to make training large language models feasible.
 Rohit Talluri is a Generative AI GTM Specialist at Amazon Web Services (AWS). He is partnering with top generative AI model builders, strategic customers, key AI/ML partners, and AWS Service Teams to enable the next generation of artificial intelligence, machine learning, and accelerated computing on AWS. He was previously an Enterprise Solutions Architect, and the Global Solutions Lead for AWS Mergers & Acquisitions Advisory.
Rohit Talluri is a Generative AI GTM Specialist at Amazon Web Services (AWS). He is partnering with top generative AI model builders, strategic customers, key AI/ML partners, and AWS Service Teams to enable the next generation of artificial intelligence, machine learning, and accelerated computing on AWS. He was previously an Enterprise Solutions Architect, and the Global Solutions Lead for AWS Mergers & Acquisitions Advisory.
Author: Balaji Chandrasekaran