

Game Developer’s Guide to Amazon DocumentDB (with MongoDB compatibility) Part Three: Operation Best Practices
Introduction To continue our discussion about Amazon DocumentDB best practices in part two, we are going to focus on data protection, scaling, monitoring, and cost optimization in this blog… Protecting data To protect your data stored in Amazon DocumentDB, you should encrypt it by enabling …
Introduction
To continue our discussion about Amazon DocumentDB best practices in part two, we are going to focus on data protection, scaling, monitoring, and cost optimization in this blog.
Protecting data
To protect your data stored in Amazon DocumentDB, you should encrypt it by enabling the storage encryption option during cluster creation. Encryption is enabled cluster-wide by default and applied to all instances, logs, automated backups, and snapshots. Amazon DocumentDB handles encryption and decryption of your data transparently, with minimal impact on performance. You can use the default AWS key or bring your own key to encrypt your data.
Amazon DocumentDB supports role-based access control (RBAC), which should be used to enforce least privilege for read-only access to databases or collections, and for multi-tenant application designs. The article Introducing role-based access control for Amazon DocumentDB (with MongoDB compatibility) explains the concepts and capabilities of RBAC in Amazon DocumentDB.
Using AWS Secrets Manager, you can retrieve Amazon DocumentDB passwords programmatically and automatically rotate them to replace hardcoded credentials in your code as explained in How to rotate Amazon DocumentDB and Amazon Redshift credentials in AWS Secrets Manager.
AWS CloudTrail integrates with Amazon DocumentDB, providing a tracking record of database actions taken by users, roles, or other AWS services, and capturing all API calls for Amazon DocumentDB. See Logging Amazon DocumentDB API Calls with AWS CloudTrail for details. In addition, you can opt in to the auditing feature of Amazon DocumentDB to record Data Definition Language (DDL), Data Manipulation Language (DML), authentication, authorization, and user management events to Amazon CloudWatch Logs in JSON document format. See Auditing Amazon DocumentDB Events for details.
Scaling
As discussed in part one, Amazon DocumentDB supports both vertical and horizontal scaling. We’ll dive deeper to focus on read consistency and preference, read and write traffic, dynamic read preference, and asymmetric workloads.
Let’s dive into read consistency and read preferences. Reads from the primary instance are strongly consistent providing read-after-write consistency. On the other end, when looking at replicas, the reads are eventually consistent. The latency between primary and replicas is typically less than 100ms. To scale your reads, it is recommended to use replica instances. This is done using readPreference of secondaryPreferred. In a situation that a replica instance goes down, the read request is directed to next available replica instance. Lastly, if no read replicas are available, then the reads are directed to the primary instance.
Now that we have a general understanding of how read consistency and preferences work, let’s talk about scaling out the read traffic. Let’s take the example where we have a three-instance cluster (primary and two read replicas) and we want to scale to support high read throughput. We can simply add read replicas! You can scale up to 15 total read replicas per cluster. If you use the read preference as secondaryPreferred, the driver will use the new replicas automatically. Sometimes you may want to have your default setting, but need to override per query basis for a stronger consistency. For example, while your default may be pointing to a secondaryPrefered read replica you can construct a query that overrides that and pulls from “primary” instead.
While it’s generally recommended to use homogenous instances in a cluster, you can consider asymmetric workloads. For example, if your workload has on-demand or periodic analytic needs such as running a report every month, you can right-size the cluster for the online workload and add a new node for analytics. From there you run the reporting queries against the new node and when you are done, shut down the node to save on cost.
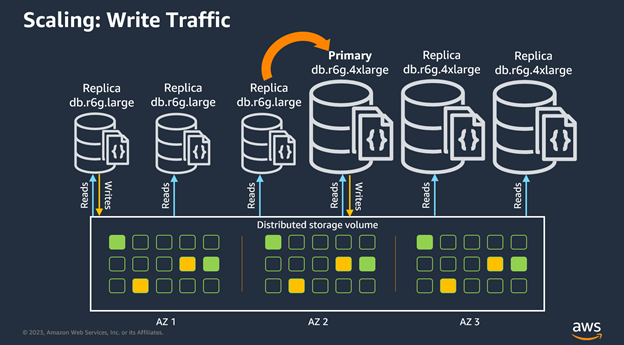
Thus far we’ve talked about scaling needs for reading, but let’s focus on scaling strategies for writes! Let’s say that your write throughput has increased, or you are expecting it to increase. Currently we are using a cluster with three r6g.large instances, but we want to move to r6g.4xlarge instances. First, we would add the three new r6g.4xlarge nodes to the cluster, and to be safe we will choose a higher promotion tier for the larger sized nodes. Note that Amazon DocumentDB will bias to choose larger nodes to become the primary by default. Now for the magic; we invoke an auto failover and the larger instance will automatically be selected as primary. When that occurs, you can safely delete the smaller r6g.large instances. The following image visualizes this process.”

Lastly, let’s finish off the topic of scaling with storage and I/O. Storage, as well as I/O, automatically scales within Amazon DocumentDB. Storage is scaled in 10GiB segments up to 128 TiB. If you are migrating workloads to Amazon DocumentDB and you are intending to delete some data, like historical data that’s no longer needed, do so before you migrate over the data to Amazon DocumentDB to reduce cost.
Monitoring
The subject of monitoring for many of AWS services is rich in details and features. Amazon DocumentDB is no different. Let’s take a high-level look at the main areas that cover the breadth of monitoring for this service.
Amazon CloudWatch
Amazon DocumentDB publishes more than 50 operational CloudWatch metrics that can be monitored. CloudWatch allows you to set alarms and send notifications when metrics cross predetermined values. These metrics provide information about instances (BufferCacheHitRation, FreeableMemory, and others) clusters (DBClusterReplicaLagMaximum, VolumeWriteIOPS, and others), storage (VolumeBytesUsed), and backup (SnapshotStorageUsed, TotalBackupStorageBilled, and others).
If you wish to go deeper on Amazon DocumentDB CloudWatch metrics, Monitoring metrics and setting up alarms on your Amazon DocumentDB clusters covers it in great detail.
Profiler and Auditing
What is the profiler? The profiler helps you identify slow queries as well as discover opportunities for new indexes. Furthermore, it helps you detect optimizations for existing indexes to improve query performance. You define a threshold, and any operation that takes longer than that threshold to run are logged to CloudWatch Logs. Use these logs to identify queries that are not using an index or that are using indexes that are not optimal. Lastly, starting profiler will help us troubleshoot any slow running queries. Read Profiling Amazon DocumentDB Operations for details.
What is auditing? Auditing allows you to log certain events that occur in Amazon DocumentDB. The events can be DDL events (authorization, managing users, creating indexes, etc.) and DML events (create, read, update, and delete). Since audit logs are written to CloudWatch logs, you can alarm on specific operations that occur. For example, 10 incorrect login attempts in a single minute. Read Introducing DML auditing for Amazon DocumentDB for details.
The profiler and auditing are disabled by default, so you must activate and configure them before use. Use the following links to the developer guide for information on how to activate them.
How to start the profiler?
How to activate auditing?
Performance Insights
Performance Insights adds to the existing Amazon DocumentDB monitoring features to illustrate your cluster performance and help you analyze any issues that affect it. With the Performance Insights dashboard, you can visualize the database load, and filter the load by waits, query statements, hosts, or applications. Performance Insights is included with Amazon DocumentDB instances and stores 7 days of performance history in a rolling window at no additional cost. Performance Insights is disabled by default and can be enabled per instance. For a quick demo, the video Getting started with Amazon DocumentDB Observability and Monitoring covers this feature.
Event Subscriptions
Lastly, you may want to subscribe to events that occur within Amazon DocumentDB. Amazon DocumentDB groups these events into categories that you can subscribe to so that you can be notified when an event in that category occurs. What are the different categories of events generated by Amazon DocumentDB? Cluster, instance, cluster snapshot, and parameter group events. You can easily subscribe to all events in a category from all resources (for example all cluster events for all clusters) or a specific event in a category from a specific resource (for example failover events for the primary instance in the production cluster). These events are generated by default so no additional Amazon DocumentDB configuration is required. Read Using Amazon DocumentDB Event Subscriptions for details.
Optimizing cost
Amazon DocumentDB provides per second billing for instances, with a 10-minute minimum billing period. To proactively manage the spend of your Amazon DocumentDB clusters, create billing alerts at thresholds of 50 percent and 75 percent of your expected bill for the month. Read Create a billing alarm for more information about creating billing alerts. You can track your costs at a granular level and understand how your costs are being allocated across resources by tagging your clusters and instances. To learn how to track the instance, storage, IOPS, and backup storage costs for your Amazon DocumentDB clusters, read Using cost allocation tags with Amazon DocumentDB.
To help manage costs for non-production environments, you should temporarily stop all the instances in your cluster (for up to seven days) when they aren’t needed, and restart them to resume your work. While your cluster is stopped, you are only charged for storage, manual snapshots, and automated backup storage within your specified retention window. You aren’t charged for any instance hours. See Stopping and Starting an Amazon DocumentDB Cluster for details
Compute and storage are decoupled in Amazon DocumentDB by design. Data is replicated six ways across three Availability Zones, providing highly durable storage regardless of the number of instances in the cluster. It’s recommended to have three or more instances for your production clusters to achieve high availability; whereas for non-production environments, you can reduce cost by running a single instance if downtime can be tolerated.
Both Time To Live indexes and change streams features will additional IOs when data is read, inserted, updated and deleted. If you are not utilizing these features in your application, deactivate them to reduce costs.
As your data grows, you should consider implementing an appropriate data archival strategy to maintain only operational data in your cluster and archive infrequently accessed data to other low-cost storage options such as Amazon Simple Storage Service (Amazon S3). Read Optimize data archival costs in Amazon DocumentDB using rolling collections to understand how to implement data archival strategy for Amazon DocumentDB.
As we round the corner on optimizing cost, let’s take a look at backups. First off, you cannot turn off backups. The minimum backup retention period is one day, and the maximum retention period is thirty-five days. Like many other familiar best practices for backup tolerance, we recommend setting retention based on your Recovery Point Objective (RPO). The backup window you define is useful to start other automated processes such as building development and test clusters from the snapshot created. Lastly, it can take up to five minutes to get live data to the backup. This means that you can recover to anytime from five minutes ago until the backup retention period.
Examples
To help you get started, we have included links to code samples. These include how to connect to Amazon DocumentDB in multiple popular programming languages, code from blogs, and AWS Lambda samples.
Connecting Programmatically to Amazon DocumentDB
Lambda function samples
Code samples from other blogs
Main Amazon DocumentDB samples GitHub repository
Summary
In this post, we’ve discussed important best practices for managing and optimizing Amazon DocumentDB clusters. Gaming customers are adopting Amazon DocumentDB to simplify the design and management of the backend database engine that powers their amazing games. By leveraging the best practices outlined in this post, you can have a good head start in your successful implementation of Amazon DocumentDB.
To learn more about Amazon DocumentDB, you can follow our videos for Amazon DocumentDB Insider Hour where you can find detailed information on well-architected lens, workshop, migration, and new launches. There are also Amazon Document tools on GitHub that you can use for your evaluation and migration efforts.
Author: Jackie Jiang