

Game Developer’s Guide to Amazon DocumentDB (with MongoDB compatibility) Part Two: Design and Development Best Practices
In this blog, we will cover capacity planning, data modeling, indexing, and connecting to DocumentDB cluster… Let’s take a look at cluster sizing as it relates to instance performance… For more information on indexing refer to How to index on Amazon DocumentDB (with MongoDB compatibility) …
Introduction
In part one, we introduced key features of Amazon DocumentDB and explained how they can be applied to solve common database use cases in game development. In part two and part three of this blog series, we are going to focus on best practices for improving the overall scalability, performance, security, and observability of Amazon DocumentDB.
In this blog, we will cover capacity planning, data modeling, indexing, and connecting to DocumentDB cluster.
Capacity Planning
While Amazon DocumentDB separates storage from compute, which allows them to be scaled independently, Storage scales automatically and compute instances can be scaled up or scaled out as required. The data is replicated six ways across three availability zones for high durability.
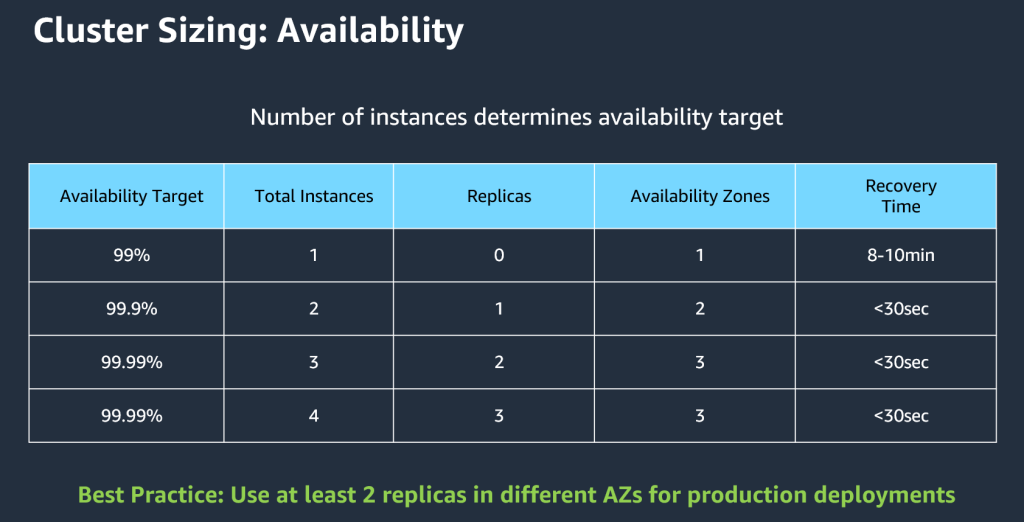
Three main areas to think about when reviewing sizing are availability and instance performance. We’ll be discussing more around performance and backups later on, but from a sizing perspective there are some items that need to be brought up. The number of instances determines availability target. The following diagram shows how the number of instances determines the availability target.

One instance is okay for development and testing environments and you’ll get two nines of availability. Two instances would be considered a minimum for a production environment and you will get three nines of availability. Using three instances is the best practice for production (it also happens to be the default) and gives you four nines of availability. Anything over three instances does not improve the availability target, but can be useful for scaling read capacity.
Let’s take a look at cluster sizing as it relates to instance performance. Keep in mind that the instance size determines the processing power and the size of memory. Ultimately, it’s the vCPU and memory per instance combo that determines the overall performance. Amazon DocumentDB provides a range of instance classes to choose from and new, expanded options are added over time.
Another best practice is to ensure indices and the working set fit in cache. Also, cache size is 2/3 of available RAM, the rest is used by the Amazon DocumentDB service. For example, if you have a working set of about 20 GB’s, the recommendation is to leverage at a minimum a r6g.xlarge with 32GiB memory. The following diagram shows more class sizes with estimated cache values.

The Amazon DocumentDB Specialist Solution Architects have developed a sizing calculator to provide a size and price estimate.
Data Modeling
Data modeling is the process of designing how an application stores data in a given database. Why is data modeling important? In short, because it can have implications when it comes to performance and cost.
As a document database, Amazon DocumentDB makes it easy to store, query, and index JSON data. Data is represented by JSON documents that support a flexible, semi-structured schema. This leads to a common misconception that it doesn’t really matter which fields your documents can have, or how different the document structures can be from one another. This can lead to anti-patterns such as large documents and arrays with a large number of elements resulting in poor performance and increased cost.
A flexible schema means that you don’t have to define a schema before inserting data and modifying the document structure can be done without downtime. Also, documents in a single collection can have different fields and different data types for common fields across documents.
Consider the following sample player profile and game documents. They both have different structures and both have a modified field. However, modified is a string in the player profile document and an ISODate in the game document.
There are two main approaches to data modeling in Amazon DocumentDB: the embedded model and the reference model. In the embedded model related data is stored, or embedded, in a single JSON document. This is a good option for entities that have one to one relationship. In the reference model data is stored in multiple documents that refer to each other. This is a good option for entities that have one to many relationship. Most use cases land on a mix of embedding and referring for the data model.
Here is an example of representing a player’s game library using the embedded and reference models.
Embedded model
In this approach, the details of every game in the player’s library is embedded in the document representing the player. This will lead to duplication of data across player profiles.
Reference model
In this approach the details of each game are stored in a separate document. The document representing the player stores the ID of the document representing the game. There is little duplication of data but the client code will need to retrieve multiple documents to get all of the information about all of the games in a user’s library.
For more information on data modeling refer to the following resources:
Data Modeling Methodology for Amazon DocumentDB virtual workshop
Introduction to data modeling with Amazon DocumentDB (with MongoDB compatibility) for relational database users
Document modeling with Amazon DocumentDB and Hackolade
Indexing
To get the best query performance in Amazon DocumentDB you need to create the right indexes. Without an index, Amazon DocumentDB has to scan every document in a collection to select those documents that match the query.
The first step is to identify the queries that run and which queries require an index. While an index can improve query performance, not all queries will require an index. For example, if you have an analytical query with no strict SLAs you should choose to not create an index to support that query.
Next, for the queries that do require an index, identify the appropriate fields for indexing. We will use a gaming portal use case as an example.
| Query | Description | Field(s) |
| Q1 | Player logs in to portal | playerID |
| Q2 | Player views game details | gameID |
| Q3 | Player views their game library | playerID |
| Q4 | Analytics reports | no index required (no SLA) |
In this example the playerID and gameID fields are used for querying. Two indexes can be created to satisfy these queries. A single field index on playerID to support queries Q1 and Q3. A single field index on gameID to support query Q2.
As a best practice we recommend creating indexes on fields with high cardinality as this helps with high selectivity of documents. Consider this sample player profile document:
In this case, the playerID field has extremely high cardinality since every player has a unique ID. The username field also has high cardinality since user names are likely unique. The firstName and lastName fields have lower cardinality since many people can have the same first or last name. Finally, the accountActive field has extremely low cardinality since there are two possible values: true or false.
A final best practice is to remove any unused indexes as they consume storage, and index updates consume CPU but provide no benefit.
For more information on indexing refer to
How to index on Amazon DocumentDB (with MongoDB compatibility)
Connecting to cluster
Amazon DocumentDB provides multiple connection options including cluster endpoint, reader endpoint, and instance endpoint to serve a wide range of use cases. We recommend that you connect to the cluster using the cluster endpoint in replica set mode and route read requests to your replicas using the built-in read preference capabilities of your driver. By doing so, you can maximize read scaling while meeting your application’s read consistency requirements.
The cluster endpoint provides failover capability for your application. If your cluster’s current primary instance fails, and your cluster has at least one active read replica, the cluster endpoint automatically redirects connection requests to a new primary instance. Connecting in replica set mode enables your application to automatically discover the cluster topography while instances are being added or removed from the cluster.

When you connect to your cluster as a replica set, you can specify the readPreference for the connection. It is recommended to use secondaryPreferred read preference to enable replica reads and free up the primary instance to handle write requests. This enables you to utilize your cluster resources including the total number of connections and cursors allowed. The following is an example connection string using cluster endpoint in replica set mode and with readPreference setting:
client = pymongo.MongoClient(‘mongodb://<user-name>:<password>@mycluster.us-east-1.docdb.amazonaws.com:27017/?replicaSet=rs0&readPreference=secondaryPreferred’)
Note: when using an SSH tunnel, we recommend that you connect to your cluster using the cluster endpoint without replica set mode as it will result in an error.
Reads from Amazon DocumentDB replicas are eventually consistent. Consistency typically occurs less than 100 milliseconds after the primary instance has written an update. You can monitor the replica lag for your cluster using the Amazon CloudWatch metrics DBInstanceReplicaLag and DBClusterReplicaLagMaximum.
If your application needs to have read-after-write consistency, which can be served only from the primary instance in Amazon DocumentDB, you should create two client connection pools: one for writes only and reads that need read-after-write consistency, and the second connection pool is for regular read with eventual consistency. Here’s an example:
clientPrimary = pymongo.MongoClient(‘mongodb://<user-name>:<password>@mycluster.us-east-1.docdb.amazonaws.com:27017/?replicaSet=rs0&readPreference=primary’)
secondaryPreferred = pymongo.MongoClient(‘mongodb://<username>:<password>@mycluster.us-east-1.docdb.amazonaws.com:27017/?replicaSet=rs0&readPreference=secondaryPreferred’)
Transport Layer Security (TLS) can be used to encrypt the connection between your application and your Amazon DocumentDB cluster. By default, encryption in transit is enabled for newly created Amazon DocumentDB clusters. When encryption in transit is enabled, secure connections using TLS are required to connect to the cluster. Here’s an example:
client = pymongo.MongoClient(‘mongodb://<sample-user>:<password>@sample-cluster.us-east-1.docdb.amazonaws.com:27017/?tls=true&tlsCAFile=global-bundle.pem&replicaSet=rs0&readPreference=secondaryPreferred&retryWrites=false’)
To encrypt data in transit, download the public key for Amazon DocumentDB named global-bundle.pem using the following operation.
wget https://truststore.pki.rds.amazonaws.com/global/global-bundle.pem
To view more code examples for programmatically connecting to a TLS-enabled Amazon DocumentDB cluster, see Connecting with TLS Enabled.
Design your application to be resilient against network and database errors. Use your driver’s error handling mechanism and associated retry techniques to properly address transient errors and persistent errors. Read
Building resilient applications with Amazon DocumentDB (with MongoDB compatibility), Part 2: Exception handling for best practices on how to implement this.
Summary
In this blog, we’ve discussed important best practices for designing the data model for and connecting to Amazon DocumentDB cluster. In part three, we’ll focus on operational best practices for managing Amazon DocumentDB clusters. Stay tuned!
Author: Jackie Jiang