

Governing the ML lifecycle at scale, Part 2: Multi-account foundations
Your multi-account strategy is the core of your foundational environment on AWS… Design decisions around your multi-account environment are critical for operating securely at scale… Grouping your workloads strategically into multiple AWS accounts enables you to apply different controls across wo…
Your multi-account strategy is the core of your foundational environment on AWS. Design decisions around your multi-account environment are critical for operating securely at scale. Grouping your workloads strategically into multiple AWS accounts enables you to apply different controls across workloads, track cost and usage, reduce the impact of account limits, and mitigate the complexity of managing multiple virtual private clouds (VPCs) and identities by allowing different teams to access different accounts that are tailored to their purpose.
In Part 1 of this series, Governing the ML lifecycle at scale, Part 1: A framework for architecting ML workloads using Amazon SageMaker, you learned about best practices for operating and governing machine learning (ML) and analytics workloads at scale on AWS. In this post, we provide guidance for implementing a multi-account foundation architecture that can help you organize, build, and govern the following modules: data lake foundations, ML platform services, ML use case development, ML operations, centralized feature stores, logging and observability, and cost and reporting.
We cover the following key areas of the multi-account strategy for governing the ML lifecycle at scale:
- Implementing the recommended account and organizational unit structure to provide isolation of AWS resources (compute, network, data) and cost visibility for ML and analytics teams
- Using AWS Control Tower to implement a baseline landing zone to support scaling and governing data and ML workloads
- Securing your data and ML workloads across your multi-account environment at scale using the AWS Security Reference Architecture
- Using the AWS Service Catalog to scale, share, and reuse ML across your multi-account environment and for implementing baseline configurations for networking
- Creating a network architecture to support your multi-account environment and facilitate network isolation and communication across your multi-tenant environment
Your multi-account foundation is the first step towards creating an environment that enables innovation and governance for data and ML workloads on AWS. By integrating automated controls and configurations into your account deployments, your teams will be able to move quickly and access the resources they need, knowing that they are secure and comply with your organization’s best practices and governance policies. In addition, this foundational environment will enable your cloud operations team to centrally manage and distribute shared resources such as networking components, AWS Identity and Access Management (IAM) roles, Amazon SageMaker project templates, and more.
In the following sections, we present the multi-account foundation reference architectures, discuss the motivation behind the architectural decisions made, and provide guidance for implementing these architectures in your own environment.
Organizational units and account design
You can use AWS Organizations to centrally manage accounts across your AWS environment. When you create an organization, you can create hierarchical groupings of accounts within organizational units (OUs). Each OU is typically designed to hold a set of accounts that have common operational needs or require a similar set of controls.
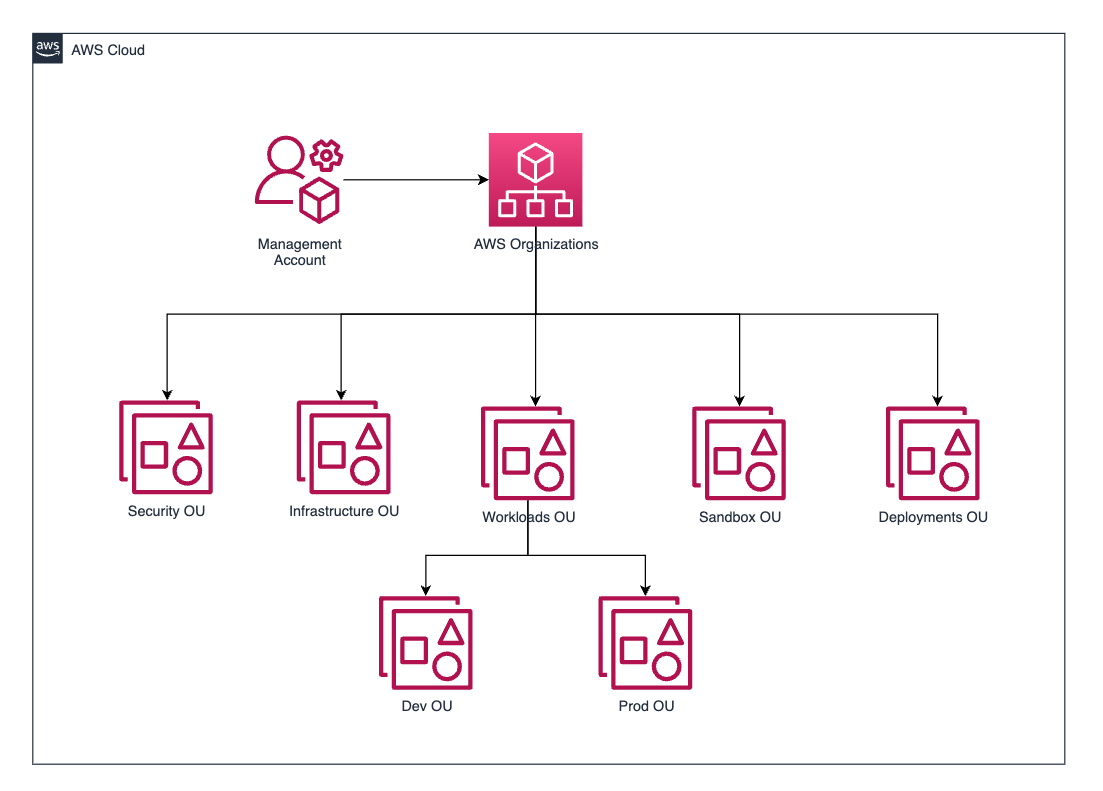
The recommended OU structure and account structure you should consider for your data and ML foundational environment is based on the AWS whitepaper Organizing Your AWS Environment Using Multiple Accounts. The following diagram illustrates the solution architecture.

Only those OUs that are relevant to the ML and data platform have been shown. You can also add other OUs along with the recommended ones. The next sections discuss how these recommended OUs serve your ML and data workloads and the specific accounts you should consider creating within these OUs.
The following image illustrates, respectively, the architecture of the account structure for setting up a multi-account foundation and how it would look like in AWS Organizations once implemented .

Recommended OUs
The recommended OUs include Security, Infrastructure, Workloads, Deployments, and Sandbox. If you deploy AWS Control Tower, which is strongly recommended, it creates two default OUs: Security and Sandbox. You should use these default OUs and create the other three. For instructions, refer to Create a new OU.
Security OU
The Security OU stores the various accounts related to securing your AWS environment. This OU and the accounts therein are typically owned by your security team.
You should consider the following initial accounts for this OU:
- Security Tooling account – This account houses general security tools as well as those security tools related to your data and ML workloads. For instance, you can use Amazon Macie within this account to help protect your data across all of your organization’s member accounts.
- Log Archive account – If you deploy AWS Control Tower, this account is created by default and placed within your Security OU. This account is designed to centrally ingest and archive logs across your organization.
Infrastructure OU
Similar to other types of workloads that you can run on AWS, your data and ML workloads require infrastructure to operate correctly. The Infrastructure OU houses the accounts that maintain and distribute shared infrastructure services across your AWS environment. The accounts within this OU will be owned by the infrastructure, networking, or Cloud Center of Excellence (CCOE) teams.
The following are the initial accounts to consider for this OU:
- Network account – To facilitate a scalable network architecture for data and ML workloads, it’s recommended to create a transit gateway within this account and share this transit gateway across your organization. This will allow for a hub and spoke network architecture that privately connects your VPCs in your multi-account environment and facilitates communication with on-premises resources if needed.
- Shared Services account – This account hosts enterprise-level shared services such as AWS Managed Microsoft AD and AWS Service Catalog that you can use to facilitate the distribution of these shared services.
Workloads OU
The Workloads OU is intended to house the accounts that different teams within your platform use to create ML and data applications. In the case of an ML and data platform, you’ll use the following accounts:
- ML team dev/test/prod accounts – Each ML team may have their own set of three accounts for the development, testing, and production stages of the MLOps lifecycle.
- (Optional) ML central deployments – It’s also possible to have ML model deployments fully managed by an MLOps central team or ML CCOE. This team can handle the deployments for the entire organization or just for certain teams; either way, they get their own account for deployments.
- Data lake account – This account is managed by data engineering or platform teams. There can be several data lake accounts organized by business domains. This is hosted in the Workloads OU.
- Data governance account – This account is managed by data engineering or platform teams. This acts as the central governance layer for data access. This is hosted in the Workloads OU.
Deployments OU
The Deployments OU contains resources and workloads that support how you build, validate, promote, and release changes to your workloads. In the case of ML and data applications, this will be the OU where the accounts that host the pipelines and deployment mechanisms for your products will reside. These will include accounts like the following:
- DevOps account – This hosts the pipelines to deploy extract, transform, and load (ETL) jobs and other applications for your enterprise cloud platform
- ML shared services account – This is the main account for your platform ML engineers and the place where the portfolio of products related to model development and deployment are housed and maintained
If the same team managing the ML engineering resources is the one taking care of pipelines and deployments, then these two accounts may be combined into one. However, one team should be responsible for the resources in one account; the moment you have different independent teams taking care of these processes, the accounts should be different. This makes sure that a single team is accountable for the resources in its account, making it possible to have the right levels of billing, security, and compliance for each team.
Sandbox OU
The Sandbox OU typically contains accounts that map to an individual or teams within your organization and are used for proofs of concept. In the case of our ML platform, this can be cases of the platform and data scientist teams wanting to create proofs of concept with ML or data services. We recommend using synthetic data for proofs of concept and avoid using production data in Sandbox environments.
AWS Control Tower
AWS Control Tower enables you to quickly get started with the best practices for your ML platform. When you deploy AWS Control Tower, your multi-account AWS environment is initialized according to prescriptive best practices. AWS Control Tower configures and orchestrates additional AWS services, including Organizations, AWS Service Catalog, and AWS IAM Identity Center. AWS Control Tower helps you create a baseline landing zone, which is a well-architected multi-account environment based on security and compliance best practices. As a first step towards initializing your multi-account foundation, you should set up AWS Control Tower.
In the case of our ML platform, AWS Control Tower helps us with four basic tasks and configurations:
- Organization structure – From the accounts and OUs that we discussed in the previous section, AWS Control Tower provides you with the Security and Sandbox OUs and the Security Tooling and Logging accounts.
- Account vending – This enables you to effortlessly create new accounts that comply with your organization’s best practices at scale. It allows you to provide your own bootstrapping templates with AWS Service Catalog (as we discuss in the next sections).
- Access management – AWS Control Tower integrates with IAM Identity Center, providing initial permissions sets and groups for the basic actions in your landing zone.
- Controls – AWS Control Tower implements preventive, detective, and proactive controls that help you govern your resources and monitor compliance across groups of AWS accounts.
Access and identity with IAM Identity Center
After you establish your landing zone with AWS Control Tower and create the necessary additional accounts and OUs, the next step is to grant access to various users of your ML and data platform. Proactively determining which users will require access to specific accounts and outlining the reasons behind these decisions is recommended. Within IAM Identity Center, the concepts of groups, roles, and permission sets allows you to create fine-grained access for different personas within the platform.
Users can be organized into two primary groups: platform-wide and team-specific user groups. Platform-wide user groups encompass central teams such as ML engineering and landing zone security, and they are allocated access to the platform’s foundational accounts. Team-specific groups operate at the team level, denoted by roles such as team admins and data scientists. These groups are dynamic, and are established for new teams and subsequently assigned to their respective accounts upon provisioning.
The following table presents some example platform-wide groups.
| User Group | Description | Permission Set | Accounts |
AWSControlTowerAdmins | Responsible for managing AWS Control Tower in the landing zone | AWSControlTowerAdmins and AWSSecurityAuditors | Management account |
AWSNetworkAdmins | Manages the networking resources of the landing zone | NetworkAdministrator | Network account |
AWSMLEngineers | Responsible for managing the ML central resources | PowerUserAccess | ML shared services account |
AWSDataEngineers | Responsible for managing the data lake, ETLs and data processes of the platform | PowerUserAccess | Data lake account |
The following table presents examples of team-specific groups.
| User Group | Description | Permission Set | Accounts |
TeamLead | Group for the administrators of the team. | AdministratorAccess | Team account |
DataScientists | Group for data scientists. This group is added as an access for the team’s SageMaker domain. | DataScientist | Team account |
MLEngineers | The team may have other roles dedicated to certain specific tasks that have a relationship with the matching platform-wide teams. | MLEngineering | Team account |
DataEngineers | DataEngineering | Team account |
AWS Control Tower automatically generates IAM Identity Center groups with permission set relationships for the various landing zone accounts it creates. You can use these preconfigured groups for your platform’s central teams or create new custom ones. For further insights into these groups, refer to IAM Identity Center Groups for AWS Control Tower. The following screenshot shows an example of the AWS Control Tower console, where you can view the accounts and determine which groups have permission on each account.

IAM Identity Center also provides a login page where landing zone users can get access to the different resources, such as accounts or SageMaker domains, with the different levels of permissions that you have granted them.

AWS Security Reference Architecture
The AWS SRA is a holistic set of guidelines for deploying the full complement of AWS security services in a multi-account environment. It can help you design, implement, and manage AWS security services so they align with AWS recommended practices.
To help scale security operations and apply security tools holistically across the organization, it’s recommended to use the AWS SRA to configure your desired security services and tools. You can use the AWS SRA to set up key security tooling services, such as Amazon GuardDuty, Macie, and AWS Security Hub. The AWS SRA allows you to apply these services across your entire multi-account environment and centralize the visibility these tools provide. In addition, when accounts get created in the future, you can use the AWS SRA to configure the automation required to scope your security tools to these new accounts.
The following diagram depicts the centralized deployment of the AWS SRA.

Scale your ML workloads with AWS Service Catalog
Within your organization, there will likely be different teams corresponding to different business units. These teams will have similar infrastructure and service needs, which may change over time. With AWS Service Catalog, you can scale your ML workloads by allowing IT administrators to create, manage, and distribute portfolios of approved products to end-users, who then have access to the products they need in a personalized portal. AWS Service Catalog has direct integrations with AWS Control Tower and SageMaker.
It’s recommended that you use AWS Service Catalog portfolios and products to enhance and scale the following capabilities within your AWS environment:
- Account vending – The cloud infrastructure team should maintain a portfolio of account bootstrapping products within the shared infrastructure account. These products are templates that contain the basic infrastructure that should be deployed when an account is created, such as VPC configuration, standard IAM roles, and controls. This portfolio can be natively shared with AWS Control Tower and the management account, so that the products are directly used when creating a new account. For more details, refer to Provision accounts through AWS Service Catalog.
- Analytics infrastructure self-service – This portfolio should be created and maintained by a central analytics team or the ML shared services team. This portfolio is intended to host templates to deploy different sets of analytics products to be used by the platform ML and analytics teams. It is shared with the entire Workloads OU (for more information, see Sharing a Portfolio). Examples of the products include a SageMaker domain configured according to the organization’s best practices or an Amazon Redshift cluster for the team to perform advanced analytics.
- ML model building and deploying – This capability maps to two different portfolios, which are maintained by the platform ML shared services team:
- Model building portfolio – This contains the products to build, train, evaluate, and register your ML models across all ML teams. This portfolio is shared with the Workloads OU and is integrated with SageMaker project templates.
- Model deployment portfolio – This contains the products to deploy your ML models at scale in a reliable and consistent way. It will have products for different deployment types such as real-time inference, batch inference, and multi-model endpoints. This portfolio can be isolated within the ML shared services account by the central ML engineering team for a more centralized ML strategy, or shared with the Workloads OU accounts and integrated with SageMaker project templates to federate responsibility to the individual ML teams.
Let’s explore how we deal with AWS Service Catalog products and portfolios in our platform. Both of the following architectures show an implementation to govern the AWS Service Catalog products using the AWS Cloud Development Kit (AWS CDK) and AWS CodePipeline. Each of the aforementioned portfolios will have its own independent pipeline and code repository. The pipeline synthesizes the AWS CDK service catalog product constructs into actual AWS Service Catalog products and deploys them to the portfolios, which are later made available for its consumption and use. For more details about the implementation, refer to Govern CI/CD best practices via AWS Service Catalog.
The following diagram illustrates the architecture for the account vending portfolio.

The workflow includes the following steps:
- The shared infrastructure account is set up with the pipeline to create the AWS Service Catalog portfolio.
- The CCOE or central infrastructure team can work on these products and customize them so that company networking and security requirements are met.
- You can use the AWS Control Tower Account Factory Customization (AFC) to integrate the portfolio within the account vending process. For more details, see Customize accounts with Account Factory Customization (AFC).
- To create a new account from the AFC, we use a blueprint. A blueprint is an AWS CloudFormation template that will be deployed in the newly created AWS account. For more information, see Create a customized account from a blueprint.
The following screenshot shows an example of what account creation with a blueprint looks like.

For the analytics and ML portfolios, the architecture changes the way these portfolios are used downstream, as shown in the following diagram.

The following are the key steps involved in building this architecture:
- The ML shared services account is set up and bootstrapped with the pipelines to create the two AWS Service Catalog portfolios.
- The ML CCOE or ML engineering team can work on these products and customize them so they’re up to date and cover the main use cases from the different business units.
- These portfolios are shared with the OU where the ML dev accounts will be located. For more information about the different options to share AWS Service Catalog portfolios, see Sharing a Portfolio.
- Sharing these portfolios with the entire Workloads OU will result in these two portfolios being available for use by the account team as soon as the account is provisioned.
After the architecture has been set up, account admins will see the AWS Service Catalog portfolios and ML workload account after they log in. The portfolios are ready to use and can get the team up to speed quickly.

Network architecture
In our ML platform, we are considering two different major logical environments for our workloads: production and pre-production environments with corporate connectivity, and sandbox or development iteration accounts without corporate connectivity. These two environments will have different permissions and requirements when it comes to connectivity.
As your environment in AWS scales up, inter-VPC connectivity and on-premises VPC connectivity will need to scale in parallel. By using services such as Amazon Virtual Private Cloud (Amazon VPC) and AWS Transit Gateway, you can create a scalable network architecture that is highly available, secure, and compliant with your company’s best practices. You can attach each account to its corresponding network segment.
For simplicity, we create a transit gateway within the central network account for our production workloads; this will resemble a production network segment. This will create a hub and spoke VPC architecture that will allow our production accounts to do the following:
- Enable inter-VPC communication between the different accounts.
- Inspect traffic with centralized egress or ingress to the network segment.
- Provide the environments with connectivity to on-premises data stores.
- Create a centralized VPC endpoints architecture to reduce networking costs while maintaining private network compliance. For more details, see Centralized access to VPC private endpoints.
For more information about these type of architectures, refer to Building a Scalable and Secure Multi-VPC AWS Network Infrastructure.
The following diagram illustrates the recommended architecture for deploying your transit gateways and creating attachments to the VPCs within your accounts. Anything considered a production environment, whether it’s a workload or shared services account, is connected to the corporate network, while dev accounts have direct internet connectivity to speed up development and exploring of new features.

At a high level, this architecture allows you to create different transit gateways within your network account for your desired AWS Regions or environments. Scalability is provided through the account vending functionality of AWS Control Tower, which deploys a CloudFormation stack to the accounts containing a VPC and the required infrastructure to connect to the environment’s corresponding network segment. For more information about this approach, see the AWS Control Tower Guide for Extending Your Landing Zone.
With this approach, whenever a team needs a new account, the platform team just needs to know whether this will be an account with corporate network connectivity or not. Then the corresponding blueprint is selected to bootstrap the account with, and the account is created. If it’s a corporate network account, the VPC will come with an attachment to the production transit gateway.
Conclusion
In this post, we discussed best practices for creating a multi-account foundation to support your analytics and ML workloads and configuring controls to help you implement governance early in your ML lifecycle. We provided a baseline recommendation for OUs and accounts you should consider creating using AWS Control Tower and blueprints. In addition, we showed how you can deploy security tools at scale using the AWS SRA, how to configure IAM Identity Center for centralized and federated access management, how to use AWS Service Catalog to package and scale your analytics and ML resources, and a best practice approach for creating a hub and spoke network architecture.
Use this guidance to get started in the creation of your own multi-account environment for governing your analytics and ML workloads at scale, and make sure you subscribe to the AWS Machine Learning Blog to receive updates regarding additional blog posts within this series.
About the authors
 Alberto Menendez is a DevOps Consultant in Professional Services at AWS. He helps accelerate customers’ journeys to the cloud and achieve their digital transformation goals. In his free time, he enjoys playing sports, especially basketball and padel, spending time with family and friends, and learning about technology.
Alberto Menendez is a DevOps Consultant in Professional Services at AWS. He helps accelerate customers’ journeys to the cloud and achieve their digital transformation goals. In his free time, he enjoys playing sports, especially basketball and padel, spending time with family and friends, and learning about technology.
 Ram Vittal is a Principal ML Solutions Architect at AWS. He has over 3 decades of experience architecting and building distributed, hybrid, and cloud applications. He is passionate about building secure, scalable, reliable AI/ML and big data solutions to help enterprise customers with their cloud adoption and optimization journey to improve their business outcomes. In his spare time, he rides motorcycle and walks with his three-year old sheep-a-doodle!
Ram Vittal is a Principal ML Solutions Architect at AWS. He has over 3 decades of experience architecting and building distributed, hybrid, and cloud applications. He is passionate about building secure, scalable, reliable AI/ML and big data solutions to help enterprise customers with their cloud adoption and optimization journey to improve their business outcomes. In his spare time, he rides motorcycle and walks with his three-year old sheep-a-doodle!
 Liam Izar is Solutions Architect at AWS, where he helps customers work backward from business outcomes to develop innovative solutions on AWS. Liam has led multiple projects with customers migrating, transforming, and integrating data to solve business challenges. His core area of expertise includes technology strategy, data migrations, and machine learning. In his spare time, he enjoys boxing, hiking, and vacations with the family.
Liam Izar is Solutions Architect at AWS, where he helps customers work backward from business outcomes to develop innovative solutions on AWS. Liam has led multiple projects with customers migrating, transforming, and integrating data to solve business challenges. His core area of expertise includes technology strategy, data migrations, and machine learning. In his spare time, he enjoys boxing, hiking, and vacations with the family.
Author: Alberto Menendez