

Host ML models on Amazon SageMaker using Triton: Python backend
Amazon SageMaker provides a number of options for users who are looking for a solution to host their machine learning (ML) models… For example, your business may have a model that must meet the strictest SLAs for latency and throughput with very predictable performance… For that use case, SageMa…
Amazon SageMaker provides a number of options for users who are looking for a solution to host their machine learning (ML) models. Of these options, one of the key features that SageMaker provides is real-time inference. Real-time inference workloads can have varying levels of requirements and service level agreements (SLAs) in terms of latency and throughput. Regardless of the use case, SageMaker offers a number of options that allow you to find the right balance of cost and performance to meet your business objectives.
There are many factors to consider when choosing the right real-time inference option for your business. For example, your business may have a model that must meet the strictest SLAs for latency and throughput with very predictable performance. For that use case, SageMaker provides SageMaker single model endpoints (SMEs), which allow you to deploy a single ML model against a logical endpoint. For other use cases, you can choose to manage cost and performance using SageMaker multi-model endpoints (MMEs), which allow you to specify multiple models to host behind a logical endpoint. Regardless of the option you may choose, SageMaker endpoints provide a scalable mechanism for even the most demanding enterprise users while providing value in a plethora of features, including shadow variants, auto scaling, and native integration with Amazon CloudWatch (for more information, see CloudWatch Metrics for Multi-Model Endpoint Deployments).
One option supported by SageMaker single and multi-model endpoints is NVIDIA Triton Inference Server. Triton supports various backends as engines to support the running and serving of various ML models for inference. For any Triton deployment, it’s crucial to know how the backend behavior impacts your workloads and what to expect so that you can be successful. In this post, we help you understand the Python backend that is supported by Triton on SageMaker so that you can make an informed decision for your workloads and achieve great results.
SageMaker provides Triton via SMEs and MMEs
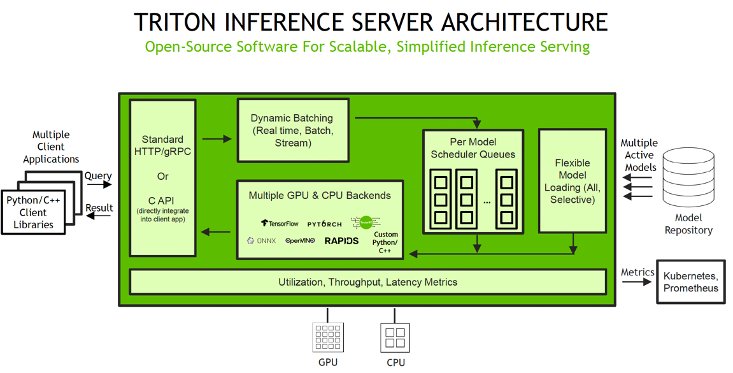
The Python backend is available through SageMaker, which enables you to deploy both single and multi-model endpoints with NVIDIA Triton Inference Server. Triton supports instance types that support GPUs, CPUs, and AWS Inferentia chips, which allow you to maximize the performance for your workloads. The following diagram illustrates the NVIDIA Triton Inference Server architecture.

Inference requests arrive at the server via either HTTP/REST or by the C API and are then routed to the appropriate per-model scheduler. Triton implements multiple scheduling and batching algorithms that can be configured on a model-by-model basis and can help tune performance. Each model’s scheduler optionally performs batching of inference requests and then passes the requests to the backend corresponding to the model type. The framework backend performs inference using the inputs provided in the batched requests to produce the requested outputs. The outputs are then formatted and returned in the response. The model repository is an object-based repository of the models powered by Amazon Simple Storage Service (Amazon S3) that Triton will make available for inferencing.
For MMEs, SageMaker takes care of traffic shaping to the endpoint and maintains optimal model copies on GPU instances for the best price performance. It continues to route traffic to the instance where the model is loaded. If the instance resources reach capacity due to high memory utilization, SageMaker unloads the least popular models from the container to free up resources to load more frequently used models. SageMaker MMEs offer capabilities for running multiple deep learning or ML models on the GPU at the same time with Triton Inference Server, which has been extended to implement the MME API contract. MMEs enable sharing GPU instances behind an endpoint across multiple models and dynamically load and unload models based on the incoming traffic. With this, you can easily achieve optimal price performance.
When a SageMaker MME receives an HTTP invocation request for a particular model using TargetModel in the request along with the payload, it routes traffic to the right instance behind the endpoint where the target model is loaded. SageMaker takes care of model management behind the endpoint. It dynamically downloads models from Amazon S3 to the instance’s storage volume if the invoked model isn’t available on the instance storage volume. Then SageMaker loads the model to the NVIDIA Triton container’s memory on a GPU accelerated instance and serves the inference request. The GPU core is shared by all the models in an instance. For more information about SageMaker MMEs on GPUs, see Run multiple deep learning models on GPU with Amazon SageMaker multi-model endpoints.
SageMaker MMEs can horizontally scale using an auto scaling policy and provision additional GPU compute instances based on specified metrics. When configuring your auto scaling groups for SageMaker endpoints, you may want to consider SageMakerVariantInvocationsPerInstance as the primary criteria to determine the scaling characteristics of your auto scaling group. In addition, based on whether your models are running on GPU or CPU, you may also consider using CPUUtilization or GPUUtilization as additional criteria. Note that for single model endpoints, because the models deployed are all the same, it’s fairly straightforward to set proper policies to meet your SLAs. For multi-model endpoints, we recommend deploying similar models behind a given endpoint to have more steady predictable performance. In use cases where models of varying sizes and requirements are used, you may want to separate those workloads across multiple multi-model endpoints or spend some time fine-tuning your auto scaling group policy to obtain the best cost and performance balance.
Python backend runtime architecture
As the name suggests, the Python backend is for running models that are written and run in the Python language. Various use cases fall into this category, such as preprocessing or postprocessing steps composing a model ensemble. In other cases, the Python backend may be used as a wrapper to call a Python-based model or framework. Later in this post, we show an example of how you can use the Python backend to call a PyTorch T5 model. This may not always be the most performant option, but it showcases the flexibility that the Python backend provides.
The Python backend creates a runtime environment that creates Python processes using the host’s CPU and memory. You can still attain GPU acceleration if it’s exposed by a Python front end of the framework running the inference. No additional GPU acceleration occurs by using the Python backend itself, but there should be no compatibility errors for any Python process.
On SageMaker, the default Triton Python backend allocates 16 MB, and grows only by 1 MB. However, you can change this by setting the SageMaker environment variables SAGEMAKER_TRITON_SHM_DEFAULT_BYTE_SIZE and SAGEMAKER_TRITON_SHM_GROWTH_BYTE_SIZE. These variables are important because it’s through shared memory that the Python backend will exchange tensors.
The following diagram shows the ensemble scheduler runtime architecture so that you can fine-tune the memory areas, including CPU addressable shared memory, that are used for inter-process communication between C++ and the Python process for exchanging tensors (input/output).

You can monitor resource utilization using CloudWatch, which has native integration with SageMaker.
To get started with the Python backend, you need to create a Python file that has a structure similar to the following code, which dictates the structure as well as how to interact with parameters and return values. Take note of the point in the lifecycle that the methods are called.
By utilizing the model.py methods, you can take on the responsibility to load models on a specific device (CPU or GPU) by writing the code in the model.py file explicitly. Although other backends that Triton provides allow you to specify a KIND attribute in the config.pbtxt file to determine if the backend runs on CPU or GPU, it’s not applicable for the Python backend because the model is loaded in the respective device depending on the code written in model.py, like .to(device) in torch. It’s important to note that if you explicitly load artifacts into memory or create temporary files, you reclaim your resources by cleaning up, which usually occurs in the finalize method. Otherwise, you may experience unwanted situations such as memory leaks.
SageMaker notebook walkthrough
With the NVIDIA Triton container image on SageMaker, you can now use Triton’s Python backend, which allows you to write your model logic in Python. For example, you can use this backend to run preprocessing and postprocessing code written in Python, or run a PyTorch Python script directly (instead of first converting it to TorchScript and then using the PyTorch backend). The python_backend GitHub repo contains the documentation and source for the backend.
In this section, we walk you through the example notebook, which demonstrates how to use NVIDIA Triton Inference Server on an Amazon SageMaker MME with the GPU feature to deploy an T5 NLP model for translation.
Set up the environment
We begin by setting up the required environment. We install the dependencies required to package our model pipeline and run inferences using Triton Inference Server. We also define the AWS Identity and Access Management (IAM) role that gives SageMaker access to the model artifacts and the NVIDIA Triton Amazon Elastic Container Registry (Amazon ECR) image. You can use the following code example to retrieve the prebuilt Triton ECR image:
Generate model artifacts
In this example, we host a pre-trained T5-small Hugging Face PyTorch model using Triton’s Python backend. Here we have the Python script model.py, which implements all the logic to initialize the T5 model and run inference for the translation task. There are three main functions in the script:
- initialize – The initialize function is called one time when the model is being loaded. Implementing
initializeis optional.initializeallows you to do any necessary initializations before running the model. This function allows the model to initialize any state associated with this model. - execute – The
executefunction is called whenever an inference request is made. Every Python model must implement theexecutefunction. In theexecutefunction, you’re given a list ofInferenceRequestobjects. There are two modes of implementing this function: default and decoupled mode. The default mode is the most generic way you would like to implement your model and requires the execute function to return exactly one response per request. The decoupled mode allows you to send multiple responses for a request or not send any responses for a request. The mode you choose should depend on your use case—that is, whether or not you want to return decoupled responses from this model. In this example notebook, we use the default mode. - finalize – Implementing
finalizeis optional. This function allows you to do any cleanup necessary before the model is unloaded from Triton Inference Server.
Build the model repository
Using Triton on SageMaker requires us to first set up a model repository folder containing the models we want to serve. For each model, we need to create a model directory consisting of the model artifact and define the config.pbtxt file to specify the model configuration that Triton uses to load and serve the model. To learn more about the config settings, refer to Model Configuration. The model repository structure for the T5 model is as follows:

Note that Triton has specific requirements for the model repository layout. Within the top-level model repository directory, each model has its own subdirectory containing the information for the corresponding model. Each model directory in Triton must have at least one numeric subdirectory representing a version of the model. Here, that is 1, representing version 1 of our T5 PyTorch model. Each model is run by a specific backend, so each version subdirectory must contain the model artifact required by that backend. Here, we are using the Python backend, and it requires the Python file that is used for serving (model.py). If we were using a PyTorch backend, a model.pt file would be required. For more details on naming conventions for model files, refer to Model Files.
Every Python Triton model must provide a config.pbtxt file describing the model configuration. To use this backend, you must set the backend field of your model config.pbtxt file to python. The following code shows how to define the config file for the T5 PyTorch model being served through Triton’s Python backend:
In this configuration, we have defined the parameters section to provide an environment path. This is because to serve the Hugging Face T5 PyTorch model using Triton’s Python backend, we have PyTorch and Hugging Face transformers as dependencies. You need to create a custom run environment in the Python backend to include all the dependencies in this example. The alternative is to install Python and all the dependencies in the local environment. The custom run environment is only needed if you want portability across different systems that might not have the Python environment to run the inference. If a custom run environment is required for SageMaker, then this should be pointed out clearly. Currently, the Python backend only supports conda-pack for this purpose. conda-pack ensures that your Conda environment is portable. We follow the instructions from the Triton documentation for packaging dependencies to be used in the Python backend as the Conda environment TAR file. Running the bash script create_hf_env.sh creates the Conda environment containing PyTorch and Hugging Face transformers and packages it as a TAR file, and then we move it into the t5-pytorch model directory:
After we create the TAR file from the Conda environment, we place it in the model folder. The following code in the model config.pbtxt file tells the Python backend to use this custom environment for your model:
parameters: {
key: "EXECUTION_ENV_PATH",
value: {string_value: "$$TRITON_MODEL_DIRECTORY/hf_env.tar.gz"}
}
Here, $$TRITON_MODEL_DIRECTORY helps provide the environment path relative to the model folder in the model repository, and is resolved to $pwd/model_repository/t5_pytorch. Finally, hf_env.tar.gz is the name we gave to our Conda environment file.
Next, we package our model as *.tar.gz files for uploading to Amazon S3:
Create a SageMaker endpoint
Now that we have uploaded the model artifacts to Amazon S3, we can create a SageMaker multi-model endpoint. To create a SageMaker endpoint, we need to first create the SageMaker model object and endpoint configuration.
Firstly, we need to define the serving container. In the container definition, define the ModelDataUrl to specify the S3 directory that contains all the models that the SageMaker multi-model endpoint will use to load and serve predictions. Set Mode to MultiModel to indicate SageMaker would create the endpoint with MME container specifications. See the following code:
Then we create the SageMaker model object using the create_model boto3 API by specifying the ModelName and container definition:
We use this model to create an endpoint configuration where we can specify the type and number of instances we want in the endpoint. Here we are deploying to a g5.2xlarge NVIDIA GPU instance:
We use this configuration to create a new SageMaker endpoint and wait for the deployment to finish:
The status will change to InService after the deployment is successful.
Invoke your model hosted on the SageMaker endpoint
After the endpoint is running, we can use some sample raw data to perform inference using JSON as the payload format. For the inference request format, Triton uses the KFServing community standard inference protocols. We can send inference requests to the multi-model endpoint using the invoke_enpoint API. We specify the TargetModel in the invocation call and pass in the payload for each model type. See the following code:
The notebook can be found in the GitHub repository.
Best practices
When using the Python backend, it can sometimes be complicated to optimize the workload for throughput and latency. You should consider the options available through the SageMaker and Triton environment variables that we discussed previously in regards to batch sizes, max delay, and other factors. In addition, you should be aware of the Python backend-specific configuration and the configuration of the underlying framework. The following are some best practices:
- If using PyTorch (or any other deep learning framework) module in the Python backend, consider experimenting with different values of intra/inter op thread pool size. Because each Python backend model instance runs in a separate process, limiting the number of threads per process prevents over-subscribing the system resources when scaling up the instance count.
- Even though the Python backend is highly flexible, it performs some extra data copies that can impact inference performance. For the best performance on GPU, consider using Triton’s TensorRT backend when possible.
- When using Python backend models in an ensemble, refer to Interoperability and GPU Support for a possible zero-copy transfer of Python backend tensors to other frameworks.
- You can also use the
instance_group_countvariable in theconfig.pbtxtfile to add a worker process and increase throughput. Be aware that increasing this variable will increase the amount of resource consumption, including CPU and GPU utilization.
You can explore these options and parameters to get the desired performance characteristics you seek. As always, be aware that resources such as processor or memory consumption can change and should be monitored so you can fine-tune and optimize inference performance.
Conclusion
In this post, we dove deep into the Python backend that Triton Inference Server supports on SageMaker. This backend provides for both CPU and GPU acceleration of your models that are written and run in the Python language. There are many options to consider to get the best performance for inference, such as batch sizes, data input formats, and other factors that can be tuned to meet your needs. SageMaker allows you to use single model endpoints for guaranteed performance and multi-model endpoints to get a better balance of performance and cost savings. To get started with MME support for GPU, see Supported algorithms, frameworks, and instances.
We invite you to try Triton Inference Server containers in SageMaker, and share your feedback and questions in the comments.
About the Authors
 James Park is a Solutions Architect at Amazon Web Services. He works with Amazon to design, build, and deploy technology solutions on AWS, and has a particular interest in AI and machine learning. In his spare time he enjoys seeking out new cultures, new experiences, and staying up to date with the latest technology trends.
James Park is a Solutions Architect at Amazon Web Services. He works with Amazon to design, build, and deploy technology solutions on AWS, and has a particular interest in AI and machine learning. In his spare time he enjoys seeking out new cultures, new experiences, and staying up to date with the latest technology trends.
 Dhawal Patel is a Principal Machine Learning Architect at AWS. He has worked with organizations ranging from large enterprises to mid-sized startups on problems related to distributed computing and artificial intelligence. He focuses on deep learning, including NLP and computer vision domains. He helps customers achieve high-performance model inference on Amazon SageMaker.
Dhawal Patel is a Principal Machine Learning Architect at AWS. He has worked with organizations ranging from large enterprises to mid-sized startups on problems related to distributed computing and artificial intelligence. He focuses on deep learning, including NLP and computer vision domains. He helps customers achieve high-performance model inference on Amazon SageMaker.
 Melanie Li is a Senior AI/ML Specialist TAM at AWS based in Sydney, Australia. She helps enterprise customers to build solutions leveraging the state-of-the-art AI/ML tools on AWS and provides guidance on architecting and implementing machine learning solutions with best practices. In her spare time, she loves to explore nature outdoors and spend time with family and friends.
Melanie Li is a Senior AI/ML Specialist TAM at AWS based in Sydney, Australia. She helps enterprise customers to build solutions leveraging the state-of-the-art AI/ML tools on AWS and provides guidance on architecting and implementing machine learning solutions with best practices. In her spare time, she loves to explore nature outdoors and spend time with family and friends.
 Jiahong Liu is a Solution Architect on the Cloud Service Provider team at NVIDIA. He assists clients in adopting machine learning and AI solutions that leverage NVIDIA accelerated computing to address their training and inference challenges. In his leisure time, he enjoys origami, DIY projects, and playing basketball.
Jiahong Liu is a Solution Architect on the Cloud Service Provider team at NVIDIA. He assists clients in adopting machine learning and AI solutions that leverage NVIDIA accelerated computing to address their training and inference challenges. In his leisure time, he enjoys origami, DIY projects, and playing basketball.
 Kshitiz Gupta is a Solutions Architect at NVIDIA. He enjoys educating cloud customers about the GPU AI technologies NVIDIA has to offer and assisting them with accelerating their machine learning and deep learning applications. Outside of work, he enjoys running, hiking and wildlife watching.
Kshitiz Gupta is a Solutions Architect at NVIDIA. He enjoys educating cloud customers about the GPU AI technologies NVIDIA has to offer and assisting them with accelerating their machine learning and deep learning applications. Outside of work, he enjoys running, hiking and wildlife watching.
Author: James Park