

Host ML models on Amazon SageMaker using Triton: TensorRT models
Sometimes it can be very beneficial to use tools such as compilers that can modify and compile your models for optimal inference performance… We explore how TensorRT works and how to host and optimize these models for performance and cost efficiency on SageMaker… SageMaker provides single model …
Sometimes it can be very beneficial to use tools such as compilers that can modify and compile your models for optimal inference performance. In this post, we explore TensorRT and how to use it with Amazon SageMaker inference using NVIDIA Triton Inference Server. We explore how TensorRT works and how to host and optimize these models for performance and cost efficiency on SageMaker. SageMaker provides single model endpoints (SMEs), which allow you to deploy a single ML model, or multi-model endpoints (MMEs), which allow you to specify multiple models to host behind a logical endpoint for higher resource utilization.
To serve models, Triton supports various backends as engines to support the running and serving of various ML models for inference. For any Triton deployment, it’s crucial to know how the backend behavior impacts your workloads and what to expect so that you can be successful. In this post, we help you understand the TensorRT backend that is supported by Triton on SageMaker so that you can make an informed decision for your workloads and get great results.
Deep dive into the TensorRT backend
TensorRT enables you to optimize inference using techniques such as quantization, layer and tensor fusion, kernel tuning, and others on NVIDIA GPUs. By adopting and compiling models to use TensorRT, you can optimize performance and utilization for your inference workloads. In some cases, there are trade-offs, which is typical of techniques such as quantization, but the results can be dramatic in benefiting performance, addressing latency and the number of transactions that can be processed.
The TensorRT backend is used to run TensorRT models. TensorRT is an SDK developed by NVIDIA that provides a high-performance deep learning inference library. It’s optimized for NVIDIA GPUs and provides a way to accelerate deep learning inference in production environments. TensorRT supports major deep learning frameworks and includes a high-performance deep learning inference optimizer and runtime that delivers low latency, high-throughput inference for AI applications.
TensorRT is able to accelerate model performance by using a technique called graph optimization to optimize the computation graph generated by a deep learning model. It optimizes the graph to minimize the memory footprint by freeing unnecessary memory and efficiently reusing it. TensorRT compilation fuses the sparse operations inside the model graph to form a larger kernel to avoid the overhead of multiple small kernel launches. With kernel auto-tuning, the engine selects the best algorithm for the target GPU, maximizing hardware utilization. Additionally, TensorRT employs CUDA streams to enable parallel processing of models, further improving GPU utilization and performance. Finally, through quantization, TensorRT can use mixed-precision acceleration of Tensor cores, enabling the model to run in FP32, TF32, FP16, and INT8 precision for the best inference performance. However, although the reduced precision can generally improve the latency performance, it might come with possible instability and degradation in model accuracy. Overall, TensorRT’s combination of techniques results in faster inference and lower latency compared to other inference engines.
The TensorRT backend for Triton Inference Server is designed to take advantage of the powerful inference capabilities of NVIDIA GPUs. To use TensorRT as a backend for Triton Inference Server, you need to create a TensorRT engine from your trained model using the TensorRT API. This engine is then loaded into Triton Inference Server and used to perform inference on incoming requests. The following are the basic steps to use TensorRT as a backend for Triton Inference Server:
- Convert your trained model to the ONNX format. Triton Inference Server supports ONNX as a model format. ONNX is a standard for representing deep learning models, enabling them to be transferred between frameworks. If your model isn’t already in the ONNX format, you need to convert it using the appropriate framework-specific tool. For example, in PyTorch, this can be done using the
torch.onnx.exportmethod. - Import the ONNX model into TensorRT and generate the TensorRT engine. For TensorRT, there are several ways to build a TensorRT from your ONNX model. For this post, we use the
trtexecCLI tool.trtexecis a tool to quickly utilize TensorRT without having to develop your own application. Thetrtexectool has three main purposes:- Benchmarking networks on random or user-provided input data.
- Generating serialized engines from models.
- Generating a serialized timing cache from the builder.
- Load the TensorRT engine in Triton Inference Server. After the TensorRT engine is generated, it can be loaded into Triton Inference Server by creating a model configuration file. The model configuration (
config.pbtxt) file should include the path to the TensorRT engine file and the input and output shapes of the model.
Each model in a model repository must include a model configuration that provides required and optional information about the model. Typically, this configuration is provided in a config.pbtxt file specified as ModelConfig protobuf. There are several key points to note in this configuration file:
- name – This field defines the model’s name and must be unique within the model repository.
- platform – This field defines the type of the model: TensorRT engine, PyTorch, or something else.
- max_batch_size – This specifies the maximum batch size that can be passed to this model. If the model’s batch dimension is the first dimension, and all inputs and outputs to the model have this batch dimension, then Triton can use its dynamic batcher or sequence batcher to automatically use batching with the model. In this case,
max_batch_sizeshould be set to a value greater than or equal to 1, which indicates the maximum batch size that Triton should use with the model. For models that don’t support batching, or don’t support batching in the specific ways we’ve described,max_batch_sizemust be set to 0. - Input and output – These fields are required because NVIDIA Triton needs metadata about the model. Essentially, it requires the names of your network’s input and output layers and the shape of said inputs and outputs.
- instance_group – This determines how many instances of this model will be created and whether they will use the GPU or CPU.
- dynamic_batching – Dynamic batching is a feature of Triton that allows inference requests to be combined by the server, so that a batch is created dynamically. The
preferred_batch_sizeproperty indicates the batch sizes that the dynamic batcher should attempt to create. For most models,preferred_batch_sizeshould not be specified, as described in Recommended Configuration Process. An exception is TensorRT models that specify multiple optimization profiles for different batch sizes. In this case, because some optimization profiles may give significant performance improvement compared to others, it may make sense to usepreferred_batch_sizefor the batch sizes supported by those higher-performance optimization profiles. You can also reference the batch size that was previously used when runningtrtexec. You can also configure the delay time to allow requests to be delayed for a limited time in the scheduler to allow other requests to join the dynamic batch.
The TensorRT backend is improved to have significantly better performance. Improvements include reducing thread contention, using pinned memory for faster transfers between CPU and GPU, and increasing compute and memory copy overlap on GPUs. It also reduces memory usage of TensorRT models in many cases by sharing weights across multiple model instances. Overall, the TensorRT backend for Triton Inference Server provides a powerful and flexible way to serve deep learning models with optimized TensorRT inference. By adjusting the configuration options, you can optimize performance and control behavior to suit your specific use case.
SageMaker provides Triton via SMEs and MMEs
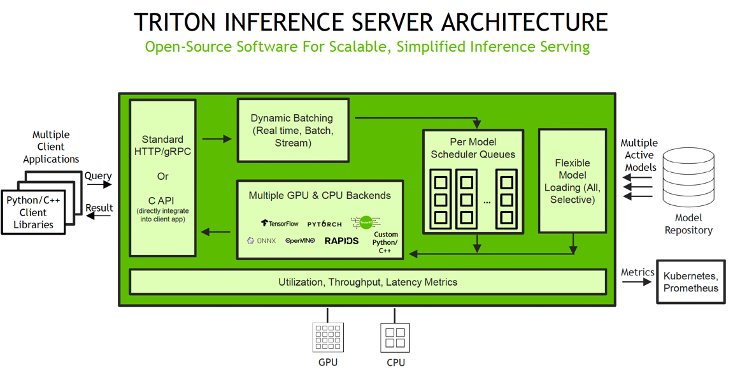
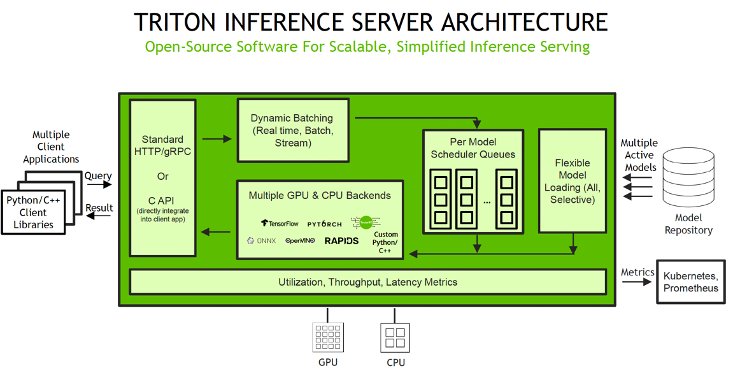
SageMaker enables you to deploy both single and multi-model endpoints with Triton Inference Server. Triton supports a heterogeneous cluster with both GPUs and CPUs, which helps standardize inference across platforms and dynamically scales out to any CPU or GPU to handle peak loads. The following diagram illustrates the Triton Inference Server architecture. Inference requests arrive at the server via either HTTP/REST or by the C API, and are then routed to the appropriate per-model scheduler. Triton implements multiple scheduling and batching algorithms that can be configured on a model-by-model basis. Each model’s scheduler optionally performs batching of inference requests and then passes the requests to the backend corresponding to the model type. The framework backend performs inferencing using the inputs provided in the batched requests to produce the requested outputs. The outputs are then formatted and returned in the response. The model repository is a file system-based repository of the models that Triton will make available for inferencing.
SageMaker takes care of traffic shaping to the MME endpoint and maintains optimal model copies on GPU instances for best price performance. It continues to route traffic to the instance where the model is loaded. If the instance resources reach capacity due to high utilization, SageMaker unloads the least-used models from the container to free up resources to load more frequently used models. SageMaker MMEs offer capabilities for running multiple deep learning or ML models on the GPU, at the same time, with Triton Inference Server, which has been extended to implement the MME API contract. MMEs enable sharing GPU instances behind an endpoint across multiple models, and dynamically load and unload models based on the incoming traffic. With this, you can easily achieve optimal price performance.
When a SageMaker MME receives an HTTP invocation request for a particular model using TargetModel in the request along with the payload, it routes traffic to the right instance behind the endpoint where the target model is loaded. SageMaker takes care of model management behind the endpoint. It dynamically downloads models from Amazon Simple Storage Service (Amazon S3) to the instance’s storage volume if the invoked model isn’t available on the instance storage volume. Then SageMaker loads the model to the NVIDIA Triton container’s memory on a GPU-accelerated instance and serves the inference request. The GPU core is shared by all the models in an instance. For more information about SageMaker MMEs on GPU, see Run multiple deep learning models on GPU with Amazon SageMaker multi-model endpoints.
SageMaker MMEs can horizontally scale using an auto scaling policy and provision additional GPU compute instances based on specified metrics. When configuring your auto scaling groups for SageMaker endpoints, you may want to consider SageMakerVariantInvocationsPerInstance as the primary criteria to determine the scaling characteristics of your auto scaling groups. In addition, based on whether your models are running on GPU or CPU, you may also consider using CPUUtilization or GPUUtilization as additional criteria. For single model endpoints, because the models deployed are all the same, it’s fairly straightforward to set proper policies to meet your SLAs. For multi-model endpoints, we recommend deploying similar models behind a given endpoint to have more steady, predictable performance. In use cases where models of varying sizes and requirements are used, you might want to separate those workloads across multiple multi-model endpoints or spend some time fine-tuning your auto scaling group policy to obtain the best cost and performance balance.
Solution overview
With the NVIDIA Triton container image on SageMaker, you can now use Triton’s TensorRT backend, which allows you to deploy TensorRT models. The TensorRT_backend repo contains the documentation and source for the backend. In the following sections, we walk you through the example notebook that demonstrates how to use NVIDIA Triton Inference Server on SageMaker MMEs with the GPU feature to deploy a BERT natural language processing (NLP) model.
Set up the environment
We begin by setting up the required environment. We install the dependencies required to package our model pipeline and run inferences using Triton Inference Server. We also define the AWS Identity and Access Management (IAM) role that gives SageMaker access to the model artifacts and the NVIDIA Triton Amazon Elastic Container Registry (Amazon ECR) image. You can use the following code example to retrieve the pre-built Triton ECR image:
Add utility methods for preparing the request payload
We create the functions to transform the sample text we’re using for inference into the payload that can be sent for inference to Triton Inference Server. The tritonclient package, which was installed at the beginning, provides utility methods to generate the payload without having to know the details of the specification. We use the created methods to convert our inference request into a binary format, which provides lower latencies for inference. These functions are used during the inference step.
Prepare the TensorRT model
In this step, we load the pre-trained BERT model and convert to ONNX representation using the torch ONNX exporter and the onnx_exporter.py script. After the ONNX model is created, we use the TensorRT trtexec command to create the model plan to be hosted with Triton. This is run as part of the generate_model.sh script from the following cell. Note that the cell takes around 30 minutes to complete.
While waiting for the command to finish running, you can check the scripts used in this step. In the onnx_exporter.py script, we use the torch.onnx.export function for ONNX model creation:
The command line in the generate_model.sh file creates the TensorRT model plan. For more information, refer to the trtexec command-line tool.
Build a TensorRT NLP BERT model repository
Using Triton on SageMaker requires us to first set up a model repository folder containing the models we want to serve. For each model, we need to create a model directory consisting of the model artifact and define the config.pbtxt file to specify the model configuration that Triton uses to load and serve the model. To learn more about the config settings, refer to Model Configuration. The model repository structure for the BERT model is as follows:
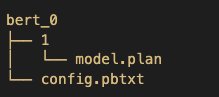
Note that Triton has specific requirements for model repository layout. Within the top-level model repository directory, each model has its own subdirectory containing the information for the corresponding model. Each model directory in Triton must have at least one numeric subdirectory representing a version of the model. Here, the folder 1 represents version 1 of the BERT model. Each model is run by a specific backend, so within each version subdirectory there must be the model artifacts required by that backend. Here, we are using the TensorRT backend, which requires the TensorRT plan file that is used for serving (for this example, model.plan). If we were using a PyTorch backend, a model.pt file would be required. For more details on naming conventions for model files, refer to Model Files.
Every TensorRT model must provide a config.pbtxt file describing the model configuration. In order to use this backend, you must set the backend field of your model config.pbtxt file to tensorrt_plan. The following section of code shows an example of how to define the configuration file for the BERT model being served through Triton’s TensorRT backend:
SageMaker expects a .tar.gz file containing each Triton model repository to be hosted on the multi-model endpoint. To simulate several similar models being hosted, you might think all it takes is to tar the model repository we have already built, and then copy it with different file names. However, Triton requires unique model names. Therefore, we first copy the model repo N times, changing the model directory names and their corresponding config.pbtxt files. You can change the number of N to have more copies of the model that can be dynamically loaded to the hosting endpoint to simulate the model load/unload action managed by SageMaker. See the following code:
Create a SageMaker endpoint
Now that we have uploaded the model artifacts to Amazon S3, we can create the SageMaker model object, endpoint configuration, and endpoint.
Firstly, we need to define the serving container. In the container definition, define the ModelDataUrl to specify the S3 directory that contains all the models that the SageMaker multi-model endpoint will use to load and serve predictions. Set Mode to MultiModel to indicate SageMaker will create the endpoint with MME container specifications. See the following code:
Then we create the SageMaker model object using the create_model boto3 API by specifying the ModelName and container definition:
We use this model to create an endpoint configuration where we can specify the type and number of instances we want in the endpoint. Here we are deploying to a g5.xlarge NVIDIA GPU instance:
With this endpoint configuration, we create a new SageMaker endpoint and wait for the deployment to finish. The status will change to InService when the deployment is successful.
Invoke your model hosted on the SageMaker endpoint
When the endpoint is running, we can use some sample raw data to perform inference using either JSON or binary+JSON as the payload format. For the inference request format, Triton uses the KFServing community standard inference protocols. We can send the inference request to the multi-model endpoint using the invoke_enpoint API. We specify the TargetModel in the invocation call and pass in the payload for each model type. Here we invoke the endpoint in a for loop to request the endpoint to dynamically load or unload models based on the requests:
You can monitor the model loading and unloading status using Amazon CloudWatch metrics and logs. SageMaker multi-model endpoints provide instance-level metrics to monitor; for more details, refer to Monitor Amazon SageMaker with Amazon CloudWatch. The LoadedModelCount metric shows the number of models loaded in the containers. The ModelCacheHit metric shows the number of invocations to model that are already loaded onto the container to help you get model invitation-level insights. To check if models are unloaded from the memory, you can look for the successful unloaded log entries in the endpoint’s CloudWatch logs.
The notebook can be found in the GitHub repository.
Best practices
Before starting any optimization effort with TensorRT, it’s essential to determine what should be measured. Without measurements, it’s impossible to make reliable progress or measure whether success has been achieved. Here are some best practices to consider when using the TensorRT backend for Triton Inference Server:
- Optimize your TensorRT model – Before deploying a model on Triton with the TensorRT backend, make sure to optimize the model following the TensorRT best practices guide. This will help you achieve better performance by reducing inference time and memory consumption.
- Use TensorRT instead of other Triton backends when possible – TensorRT is designed to optimize deep learning models for deployment on NVIDIA GPUs, so using it can significantly improve inference performance compared to using other supported Triton backends.
- Use the right precision – TensorRT supports multiple precisions (FP32, FP16, INT8), and selecting the right precision for your model can have a significant impact on performance. Consider using lower precision when possible.
- Use batch sizes that fit your hardware – Make sure to choose batch sizes that fit your GPU’s memory and compute capabilities. Using batch sizes that are too large or too small can negatively impact performance.
Conclusion
In this post, we dove deep into the TensorRT backend that Triton Inference Server supports on SageMaker. This backend provides for both CPU and GPU acceleration of your TensorRT models. There are many options to consider to get the best performance for inference, such as batch sizes, data input formats, and other factors that can be tuned to meet your needs. SageMaker allows you to take advantage of this capability using single model endpoints for guaranteed performance and multi-model endpoints to get a better balance of performance and cost savings. To get started with MME support for GPU, see Supported algorithms, frameworks, and instances.
We invite you to try Triton Inference Server containers in SageMaker, and share your feedback and questions in the comments.
About the Authors
 Melanie Li is a Senior AI/ML Specialist TAM at AWS based in Sydney, Australia. She helps enterprise customers to build solutions leveraging the state-of-the-art AI/ML tools on AWS and provides guidance on architecting and implementing machine learning solutions with best practices. In her spare time, she loves to explore nature outdoors and spend time with family and friends.
Melanie Li is a Senior AI/ML Specialist TAM at AWS based in Sydney, Australia. She helps enterprise customers to build solutions leveraging the state-of-the-art AI/ML tools on AWS and provides guidance on architecting and implementing machine learning solutions with best practices. In her spare time, she loves to explore nature outdoors and spend time with family and friends.
 James Park is a Solutions Architect at Amazon Web Services. He works with Amazon to design, build, and deploy technology solutions on AWS, and has a particular interest in AI and machine learning. In his spare time he enjoys seeking out new cultures, new experiences, and staying up to date with the latest technology trends.
James Park is a Solutions Architect at Amazon Web Services. He works with Amazon to design, build, and deploy technology solutions on AWS, and has a particular interest in AI and machine learning. In his spare time he enjoys seeking out new cultures, new experiences, and staying up to date with the latest technology trends.
 Jiahong Liu is a Solution Architect on the Cloud Service Provider team at NVIDIA. He assists clients in adopting machine learning and AI solutions that leverage NVIDIA accelerated computing to address their training and inference challenges. In his leisure time, he enjoys origami, DIY projects, and playing basketball.
Jiahong Liu is a Solution Architect on the Cloud Service Provider team at NVIDIA. He assists clients in adopting machine learning and AI solutions that leverage NVIDIA accelerated computing to address their training and inference challenges. In his leisure time, he enjoys origami, DIY projects, and playing basketball.
 Kshitiz Gupta is a Solutions Architect at NVIDIA. He enjoys educating cloud customers about the GPU AI technologies NVIDIA has to offer and assisting them with accelerating their machine learning and deep learning applications. Outside of work, he enjoys running, hiking and wildlife watching.
Kshitiz Gupta is a Solutions Architect at NVIDIA. He enjoys educating cloud customers about the GPU AI technologies NVIDIA has to offer and assisting them with accelerating their machine learning and deep learning applications. Outside of work, he enjoys running, hiking and wildlife watching.
Author: Melanie Li