

How an insurance company implements disaster recovery of 3-tier applications
AWS recommends a multi-AZ strategy for high availability and a multi-Region strategy for disaster recovery… The solution Amazon Route53 Application Recovery Controller (Route53 ARC) helps manage and orchestrate application failover and recovery across multiple AWS Regions or on-premises environ…
A good strategy for resilience will include operating with high availability and planning for business continuity. It also accounts for the incidence of natural disasters, such as earthquakes or floods and technical failures, such as power failure or network connectivity. AWS recommends a multi-AZ strategy for high availability and a multi-Region strategy for disaster recovery. In this post, we explore how one of our customers, a US-based insurance company, uses cloud-native services to implement the disaster recovery of 3-tier applications.
At this insurance company, a relevant number of critical applications are 3-tier Java or .Net applications. These applications require access to IBM DB2, Oracle, or Microsoft SQLServer databases that run on Amazon EC2 instances. The requirement was to create a disaster recovery strategy that implements a Pilot Light or Warm/Standby scenario. This design needs to keep costs at a minimum, and it needs to allow for failure detection and manual failover of resources. Furthermore, it needs to keep the Recovery Time Objective (RTO) and the Recovery Point Objective (RPO) under 15 minutes. Finally, the solution could not use any public resources.
The solution
Amazon Route53 Application Recovery Controller (Route53 ARC) helps manage and orchestrate application failover and recovery across multiple AWS Regions or on-premises environments. It is specifically focused on managing DNS routing and traffic management during failover and recovery operation; however, some customers decide to implement their own strategies for application recovery. In this blog, we are going to focus on how one of our financial services customer implements it.
The Well-Architected framework explains that a good disaster recovery plan needs to manage configuration drift. A good practice is to use the delivery pipeline to deploy to both Regions and to regularly test the recovery pattern. There are customers that go a step further and even choose to operate in the secondary Region for a period of time.
The solution chosen by one of our leading insurance customers encompasses two distinct scenarios: a failover and a failback scenario. The failover scenario covers a list of steps to failover applications from the primary Region to the secondary Region. The failback process is the return of the operations to the primary Region.
Failover
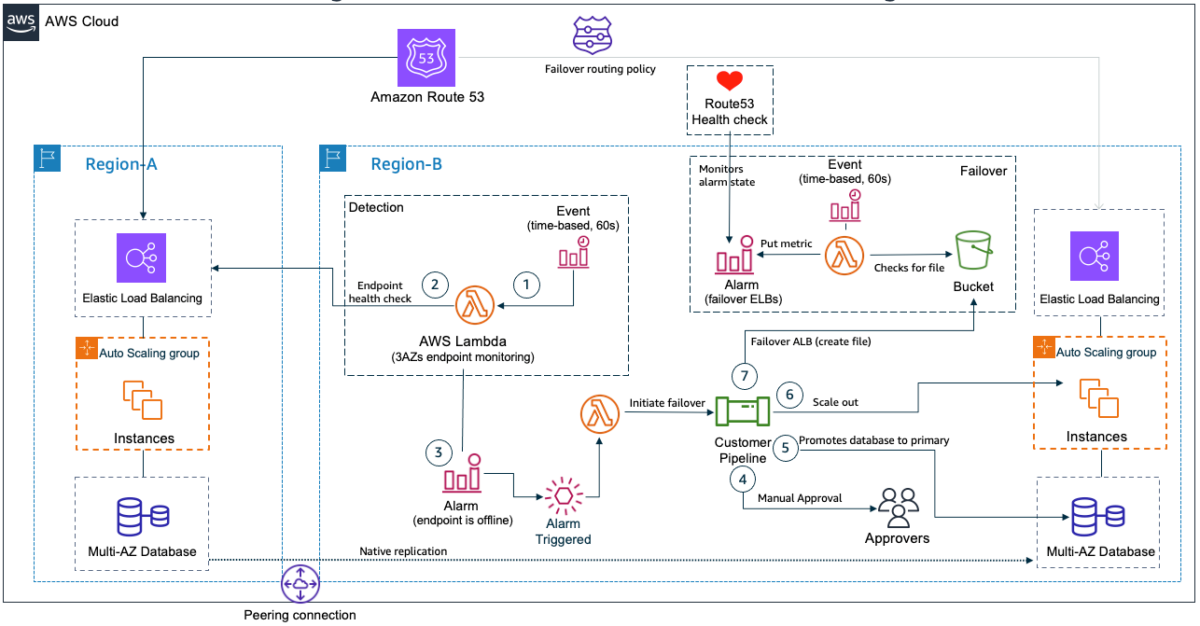
Our customer decided to test the Pilot Light scenario. This scenario considers an application and a database deployed both in the primary and secondary Regions. As a requirement to achieve the 15-minute RPO, an application deployed in the primary Region needs to replicate data to the secondary Region. This async replication is implemented for each of the company’s database engines (DB2, SQLServer, Oracle) using native tooling. Leveraging native tooling was an existing practice and going with it would help minimize any operational impact.
It is important to notice that the detection and failover mechanisms is created in the secondary Region. This ensures these components will remain available when the primary Region becomes unavailable. Another important aspect is to establish connectivity between the two networks. This is needed to allow for the database replication.

Figure 1. The Pilot Light scenario for a 3-tier application that has application servers and a database deployed in two Regions
The failover procedure uses the following steps for detection and failover:
- An Amazon EventBridge scheduler runs the AWS Lambda function every 60 seconds.
- The Lambda function tests the application endpoint and adds a custom metric to Amazon CloudWatch. If the application is unavailable, a CloudWatch Alarm will start the Lambda Function that initiates the failover.
- A Lambda function initiates the failover by starting a Jenkins pipeline. The pipeline will failover the application and the database to the secondary Region. The Jenkins pipeline starts with a manual approval step, ensuring that the failover process does not start automatically.
- Once approvers validate the necessity of the failover, they approve the workflow, and the pipeline moves to the next stage.
- The pipeline failovers the database, promoting the database in the secondary Region to the primary state and enables write operations.
- Next, start or scale out application servers that run on EC2 instances or containers. This is important to assure they will support the increased load in the secondary Region once failover is complete.
- At this point, database and application servers are ready to receive load. Next, the Application Load Balancer (ALB) needs to failover to the secondary Region. Route53 failover routing policy automatically failovers between Regions, but this customer wanted to manually control this step using a health check. To implement a manual failover of the ALB, the pipeline creates a file in a designated S3 bucket. A Lambda function regularly checks if this file exists in the expected location. If so, it triggers a CloudWatch Alarm and the Route53 health check will fail. At this point, Route 53 will redirect traffic to the ALB in the secondary Region, becoming the new active endpoint.
Failback
The failback scenario starts when all the required services become online in the primary Region. AWS recommends using AWS Personal Health Dashboard to check for service health. Figure 2 illustrates the failback process in detail. It shows the step-by-step flow from initiating the failback procedure to the final DNS switchover, highlighting the key components and interactions involved in each stage. This visual representation helps to clarify the complex process of returning operations to the primary Region.

Figure 2. Diagram of the failback process
The failback procedure is implemented in six steps:
- A cloud operator or Site Reliability Engineer (SRE) initiates the failback procedure by submitting a form on an HTML page. A Lambda function starts a Jenkins pipeline.
- The pipeline initiates the delta sync replication of the database. This ensures that data changes made in the secondary Region are replicated to the primary Region.
- The next stage is a manual approval to recover back to the primary Region, where the SRE verifies that the databases are in sync and all services needed are online in the primary Region.
- Upon approval, the pipeline starts the application servers in the primary Region.
- Next, the database in the primary Region is promoted for write operations. The database endpoint in the secondary Region is updated to point to the primary Region’s database.
- As explained in the failover section, the DNS switchover depends on a file existing in S3. Since this file was created for our failover event, the pipeline will now remove this file. The Lambda function identifies the change and updates the state of the CloudWatch Alarm, then the Route53 Healthcheck will change the state. At this point, the ALB in the primary Region becomes active and failback completes successfully.
Benefits
This customer identified the following benefits in implementing this design:
- Customizable solution that aligns with the company’s internal processes, operating model, and technologies in use
- Standardized pattern applicable across the organization for applications with different technologies, including databases, Windows and Linux applications running on EC2
- Recovery Point Objective (RPO) and Recovery Time Objective (RTO) of less than 15 minutes
- A cost optimized solution that uses cloud native services to implement the detection and failover scenarios
Conclusion
The solution for the disaster recovery of 3-tier applications demonstrates this financial services customer’s commitment to ensuring business continuity and resilience. This design showcases the company’s ability to tailor their architecture to their specific requirements. Achieving an RPO and RTO of less than 15 minutes for critical applications is a remarkable feat. It ensures minimal disruption to business operations during regional outages.
Furthermore, this solution leverages existing technologies and processes within the company, allowing for seamless integration and adoption across the organization. The ability to standardize this pattern for applications with different technologies helps simplifying the operating model.
If you’re an enterprise seeking to enhance the resilience of your critical applications, this disaster recovery solution from one of our enterprise customers serves as an inspiring example. To further explore the disaster recovery strategies and best practices on AWS, we recommend the following resources:
- Disaster Recovery of Workloads on AWS: Recovery in the Cloud: Provides a comprehensive overview of disaster recovery concepts and strategies on AWS.
- Creating a Multi-Region Application with AWS Services: A three-part blog post offers insights into designing applications that span multiple AWS Regions for improved resilience.
- AWS Well-Architected Framework – Reliability Pillar: Discusses best practices for building reliable and resilient systems on AWS.
- Disaster Recovery Architectures on AWS: A four-part blog post with a collection of reference architectures for various disaster recovery scenarios.
Author: Amit Narang