

How Meesho built a generalized feed ranker using Amazon SageMaker inference
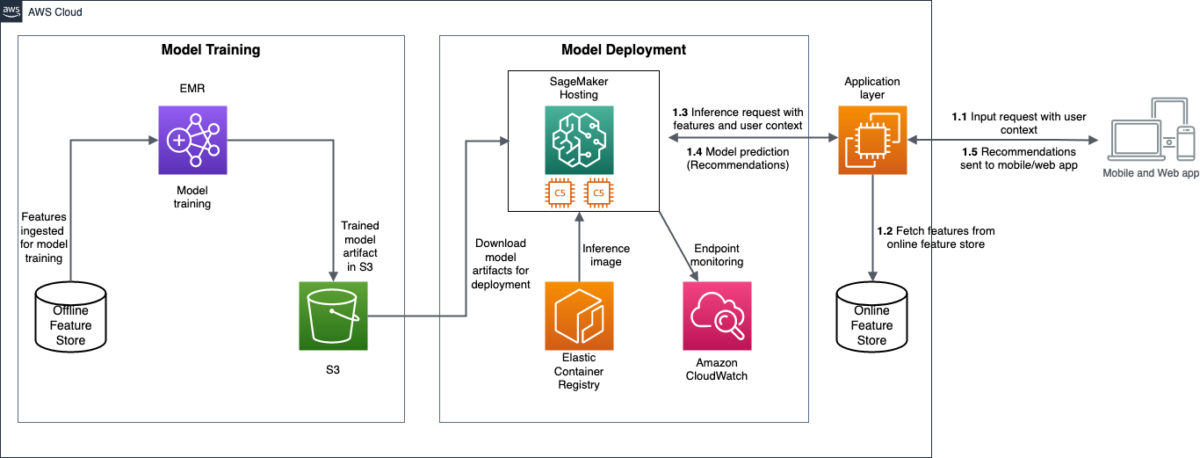
These valuable features are used to construct ranking models… All these features go as input to the Learning to Rank (LTR) model that tries to emit the Probability of Click (PCTR) and Probability of Purchase (PCVR)… The architecture can be divided into two different components: model trainin…
This is a guest post co-written by Rama Badrinath, Divay Jindal and Utkarsh Agrawal at Meesho.
Meesho is India’s fastest growing ecommerce company with a mission to democratize internet commerce for everyone and make it accessible to the next billion users of India. Meesho was founded in 2015 and today focuses on buyers and sellers across India. The Meesho marketplace provides micro, small, and medium businesses and individual entrepreneurs access to millions of customers, a selection from over 30 categories and more than 900 sub-categories, pan-India logistics, payment services, and customer support capabilities to efficiently run their businesses on the Meesho ecosystem.
As an ecommerce platform, Meesho aims to improve the user experience by offering personalized and relevant product recommendations. We wanted to create a generalized feed ranker that considers individual preferences and historical behavior to effectively display products in each user’s feed. Through this, we wanted to boost user engagement, conversion rates, and overall business growth by tailoring the shopping experience to each customer’s unique requirements and providing the best value for their money.
We used AWS machine learning (ML) services like Amazon SageMaker to develop a powerful generalized feed ranker (GFR). In this post, we discuss the key components of the GFR and how this ML-driven solution streamlined the ML lifecycle, ensuring efficient infra management, scalability, and reliability within the ecosystem.
Solution overview
To personalize users’ feeds, we analyzed extensive historical data, extracting insights into features that include browsing patterns and interests. These valuable features are used to construct ranking models. The GFR personalizes each user’s feed in real time, considering various factors like geography, prior shopping pattern, acquisition channels, and more. Several interaction-based features are also used to capture the affinity of the user towards an item, item category, or item properties like price, rating, or discount.
Several user-agnostic features and scores at item level are used as well. These include an item popularity score and item propensity to buy score. All these features go as input to the Learning to Rank (LTR) model that tries to emit the Probability of Click (PCTR) and Probability of Purchase (PCVR).
For diverse and relevant recommendations, the GFR sources candidate products from multiple channels, including exploit (known user preferences), explore (novel and potentially interesting products), popularity (trending items), and recent (latest additions).
The following diagram illustrates the GFR architecture.

The architecture can be divided into two different components: model training and model deployment. In the following sections, we discuss each component and the AWS services used in more detail.
Model training
Meesho used Amazon EMR with Apache Spark to process hundreds of millions of data points, depending on the model’s complexity. One of the major challenges was to run distributed training at scale. We used Dask—a distributed data science computing framework that natively integrates with Python libraries—on Amazon EMR to scale out the training jobs across the cluster. The distributed training of the model helped cut down training time from days to hours and allowed us to schedule Spark jobs efficiently and cost-effectively. We used an offline feature store to maintain a historical record of all feature values that will be used for model training. Model artifacts from training are stored in Amazon Simple Storage Service (Amazon S3), providing convenient access and version management.
We used a time sampling strategy to create training, validation, and test datasets for model training. We kept track of various metrics to evaluate the performance of the model—the most important ones being area under the ROC curve and area under the precision recall curve. We also tracked calibration of the model to prevent overconfidence and underconfidence issues while predicting the probability scores.
Model deployment
Meesho used SageMaker inference endpoints with auto scaling enabled for deploying the trained model. SageMaker offered ease of deployment with support for various ML frameworks, allowing models to be served with low latency. Although AWS offers standard inference images suitable for most use cases, we built a custom inference image that caters specifically to our needs and pushed it to Amazon Elastic Container Registry (Amazon ECR).
We built an in-house A/B testing platform that facilitated live monitoring of A/B metrics, enabling us to make data-driven decisions promptly. We also used the A/B testing feature of SageMaker to deploy multiple production variants on an endpoint. Through A/B experiments, we observed an approximate 3.5% enhancement in the platform’s conversion rate and an increase in app open frequency of the users, highlighting the effectiveness of this approach.
We kept track of various drifts such as feature drift and prior drift multiple times a day after model deployment to prevent the model performance from deteriorating.
We used AWS Lambda to set up various automations and triggers that are required during model retraining, endpoint updates, and monitoring processes.
The recommendation workflow after model deployment works as follows (as noted in the solution architecture diagram):
- The input requests with user context and interaction features are received at the application layer from Meesho’s mobile and web app.
- The application layer fetches additional features like historical data of the user from the online feature store and appends these to the input requests.
- The appended features are sent to the real-time endpoints for generating recommendations.
- The model predictions are sent back to the application layer.
- The application layer uses these predictions to personalize the user feeds on the mobile or web application.
Conclusion
Meesho successfully implemented a generalized feed ranker using SageMaker, which resulted in highly personalized product recommendations for each customer based on their preferences and historical behavior. This approach significantly improved user engagement and led to higher conversion rates, contributing to the company’s overall business growth. As a result of utilizing AWS services, our ML lifecycle runtime reduced significantly, from taking months to just weeks, leading to increased efficiency and productivity for our team.
With this advanced feed ranker, Meesho continues to deliver tailored shopping experiences, adding more value to its customers and fulfilling its mission to democratize ecommerce for everyone.
The team is grateful for the continuous support and guidance from Ravindra Yadav, Director of Data Science at Meesho, and Debdoot Mukherjee, Head of AI at Meesho, who played a key role in enabling this success.
To learn more about SageMaker, refer to the Amazon SageMaker Developer Guide.
About the Authors
 Utkarsh Agrawal is currently working as a Senior Data Scientist at Meesho. He previously worked with Fractal Analytics and Trell on various domains, including recommender systems, time series, NLP, and more. He holds a master’s degree in Mathematics and Computing from Indian Institute of Technology Kharagpur (IIT), India.
Utkarsh Agrawal is currently working as a Senior Data Scientist at Meesho. He previously worked with Fractal Analytics and Trell on various domains, including recommender systems, time series, NLP, and more. He holds a master’s degree in Mathematics and Computing from Indian Institute of Technology Kharagpur (IIT), India.
 Rama Badrinath is currently working as a Principal Data Scientist at Meesho. He previously worked with Microsoft and ShareChat on various domains, including recommender systems, image AI, NLP, and more. He holds a master’s degree in Machine Learning from Indian Institute of Science (IISc), India. He has also published papers in renowned conferences such as KDD and ECIR.
Rama Badrinath is currently working as a Principal Data Scientist at Meesho. He previously worked with Microsoft and ShareChat on various domains, including recommender systems, image AI, NLP, and more. He holds a master’s degree in Machine Learning from Indian Institute of Science (IISc), India. He has also published papers in renowned conferences such as KDD and ECIR.
 Divay Jindal is currently working as a Lead Data Scientist at Meesho. He previously worked with Bookmyshow on various domains, including recommender systems and dynamic pricing.
Divay Jindal is currently working as a Lead Data Scientist at Meesho. He previously worked with Bookmyshow on various domains, including recommender systems and dynamic pricing.
 Venugopal Pai is a Solutions Architect at AWS. He lives in Bengaluru, India, and helps digital-native customers scale and optimize their applications on AWS.
Venugopal Pai is a Solutions Architect at AWS. He lives in Bengaluru, India, and helps digital-native customers scale and optimize their applications on AWS.
Author: Utkarsh Agrawal