

How Smartsheet boosts developer productivity with Amazon Bedrock and Roo Code
With this feature, organizations can cache frequently used prompts across multiple API calls, reducing costs by up to 90% and lowing latency by up to 85%… The cached context remains available for up to 5 minutes after each access, with each cache hit resetting this countdown… When a developer m…
This post was co-written with JB Brown from Smartsheet.
Organizations are often seeking ways to enhance developer productivity while maintaining cost-efficiency. AI-powered coding assistants are effective solutions to accelerate development cycles, but implementing these solutions at scale while managing costs presents unique challenges. Roo Code, an AI-powered autonomous coding agent located directly in developers’ editors, represents the latest evolution in AI-assisted development. It helps developers code faster and smarter by offering capabilities ranging from code generation and refactoring to documentation writing and code base analysis through natural language interaction. This post explores how Smartsheet successfully deployed Roo Code with Amazon Bedrock and Anthropic’s Claude, achieving significant improvements in developer efficiency while optimizing costs through innovative caching strategies.
The Amazon Bedrock prompt caching capability, which became generally available in April 2025, represents a significant advancement in optimizing AI model interactions. With this feature, organizations can cache frequently used prompts across multiple API calls, reducing costs by up to 90% and lowing latency by up to 85%. The technology is particularly valuable for applications that repeatedly use similar context, such as coding assistants that need to maintain context about code files. Prompt caching supports multiple foundation models (FMs), including Anthropic’s Claude 3.5 Haiku and Anthropic’s Claude 3.7 Sonnet, as well as the Amazon Nova family of models. The cached context remains available for up to 5 minutes after each access, with each cache hit resetting this countdown. For organizations implementing AI-assisted development workflows, they can use this capability to balance performance with cost-efficiency.
Benefits of Amazon Bedrock prompt caching
Smartsheet is a leading cloud-based enterprise work management service, enabling millions of users worldwide to plan, manage, track, automate, and report on work at scale. Their engineering team identified an opportunity to enhance developer productivity by implementing AI-assisted coding capabilities across their organization. The solution needed to scale efficiently while maintaining reasonable costs, leading them to choose Roo Code with Amazon Bedrock with Anthropic’s Claude as their FM provider.
“Our engineering team has achieved a 60% reduction in operational costs and 20% improvement in response latency when using Roo Code with Amazon Bedrock prompt caching. These improvements directly translate to enhanced developer productivity across our organization,” says JB Brown, VP of Engineering at Smartsheet.
This fact is underscored by the team’s ability to rapidly generate comprehensive code documentation and architecture diagrams in a mere four hours, a task that previously consumed 2 weeks of manual effort. This newfound efficiency extends to critical areas like AWS cost management, where a vital analysis tool was built in just 30 minutes, and is projected to save Smartsheet $450,000 annually. Furthermore, the speed and accessibility of information have been significantly amplified, as evidenced by the 6–8 hours of senior engineer time saved by quickly explaining complex Terraform/Terragrunt infrastructure. These examples highlight how Amazon Bedrock prompt caching is not just about incremental gains, but about unlocking substantial time and resource savings, empowering our developers to focus on innovation rather than time-consuming manual processes.
Solution overview
When implementing AI-assisted coding at scale, Smartsheet faced several key challenges around managing costs associated with large language model (LLM) API calls, reducing latency for developer interactions and handling repetitive elements in prompts efficiently. The development team recognized that a significant portion of the prompts sent to Amazon Bedrock were repeated elements: the system prompt and the continuously building message history, presenting an opportunity for optimization.
To address these challenges, Smartsheet implemented a comprehensive solution centered around Roo Code integration with Amazon Bedrock and prompt caching. Smartsheet deployed Roo Code, powered by Amazon Bedrock and Anthropic’s Claude 3.7, across the organization and integrated seamlessly into existing development workflows. This provided developers with immediate access to AI assistance for code writing, reviewing, and debugging tasks.
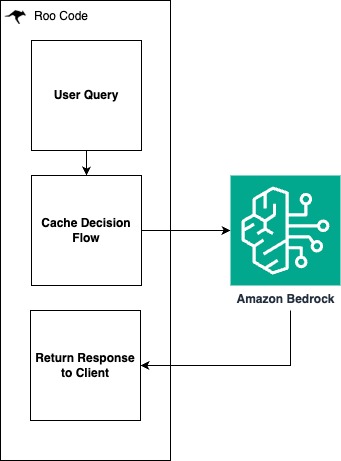
The team then contributed a sophisticated Amazon Bedrock prompt caching system to Roo Code that identifies and stores common prompt elements, significantly reducing redundant data transmission to Bedrock. This caching layer proved crucial in optimizing both cost and performance metrics. The caching decision flow incorporates two key checks: first, it verifies if the selected model supports prompt caching, then it makes sure the system prompt meets a minimum token threshold to make caching worthwhile.
The solution integrates Roo Code directly into developers’ integrated development environments (IDE), using the Amazon Bedrock prompt caching capabilities. The architecture separates content into static elements (like system instructions and code context) and dynamic elements (like user queries). When a developer makes a request, static content is automatically marked with cache checkpoints and stored for 5 minutes, with each access refreshing this window.
For subsequent queries, the system checks for matching cached content before processing. When matches are found, it bypasses recomputation of these sections, significantly reducing both response time and costs.
The following diagram shows the integration points between Roo Code and Amazon Bedrock.

The following screenshot highlights the model provider settings and connection parameters required for implementation.

Optimizing performance with prompt caching
When analyzing code files, much of the context—such as file contents and environment details—remains consistent across multiple queries. By caching this content, subsequent requests can reuse it from the cache, significantly reducing cost and latency.
In our example, we first asked Roo Code to analyze a Python file. We then sent multiple follow-up queries about different aspects of the code. The first query explained the overall structure, followed by questions about specific classes, unused modules, and potential improvements.
The usage section of the responses showed significant improvements through caching. During the first query, the model processed the input and wrote the cached content. For subsequent queries, 90% of the input was served from the cache. Because cache reads are 90% cheaper than processing new input tokens, this resulted in an 83% cost reduction for follow-up queries.
Here’s how the caching worked across queries:
- First query – The model processed the entire file content and environment details, writing them to cache
- Subsequent queries – The model loaded the cached content, only processing the new question text
To illustrate this, let’s look at the usage statistics from a series of queries:
Query 1: "Explain my @/src/models/product.py code"
{
"inputTokens": 1051,
"outputTokens": 902,
"totalTokens": 19374,
"cacheReadInputTokenCount": 0,
"cacheWriteInputTokenCount": 12421
}
Query 2: "Describe what is ProductUpdate class used for"
{
"inputTokens": 1078,
"outputTokens": 694,
"totalTokens": 21664,
"cacheReadInputTokenCount": 19892,
"cacheWriteInputTokenCount": 0
}
Query 3: "Which module is not in use?"
{
"inputTokens": 4,
"outputTokens": 774,
"totalTokens": 22753,
"cacheReadInputTokenCount": 19892,
"cacheWriteInputTokenCount": 2083
}
Query 4: "Any improvement to implement to my code making it more efficient?"
{
"inputTokens": 1097,
"outputTokens": 1270,
"totalTokens": 24342,
"cacheReadInputTokenCount": 21975,
"cacheWriteInputTokenCount": 0
}
We can see from the results that the first query didn’t return cacheReadInputTokenCount but wrote to the cache the whole input. For subsequent queries, most of the input was read from the cache, except for the specific question.
The results clearly demonstrate the benefits of prompt caching:
- 70% of total input was served from cache across queries
- 90% of input for follow-up queries came from cache
- Overall input costs reduced by 60%
- Follow-up query costs reduced by 83%
This approach is particularly effective for development workflows where developers frequently query the same code base with different questions. The cached content provides necessary context for each query while significantly reducing processing overhead.
The following screenshot displays Roo Code’s interface, showing detailed metrics including token usage, cache hit rates, and associated API costs. The interface presents the cost savings achieved through caching and provides comprehensive usage analytics.

Results and future innovation
The following line graph demonstrates the cost reduction trend over multiple queries runs, having the first query uncached, and the subsequent input using significant query responses from the cache. The y-axis shows costs in dollars, and the x-axis shows the cost per query. The graph shows a clear downward trend, with costs decreasing by 60% from the baseline.

The implementation delivered remarkable improvements across key metrics. The prompt caching system achieved a 60% reduction in operational costs while simultaneously improving response latency by 20%.
The choice of Amazon Bedrock prompt caching proved particularly effective for Smartsheet’s coding assistance workflows. The 5-minute cache Time to Live (TTL) aligns perfectly with the natural rhythm of developer interactions with Roo Code, where multiple related queries typically occur within short timeframes. During active coding sessions, developers engage in rapid back-and-forth exchanges with the AI assistant—reviewing code, asking follow-up questions, and requesting modifications—while maintaining context through the cache. This agentic workflow, where each interaction builds upon previous context, takes full advantage of the prompt caching mechanism—each query refreshes the cache timer while preserving valuable context about the code being discussed.
Best practices and lessons learned
Through their implementation journey, Smartsheet developed several key best practices for organizations looking to implement similar solutions. Early implementation of prompt caching proved crucial, allowing the team to analyze prompt patterns and design efficient caching strategies from the start. The team found that focusing on developer experience through response time optimization and seamless tool integration was essential for successful adoption.
Continuous monitoring and analysis of usage patterns became a cornerstone of their optimization strategy. By tracking key metrics like response times and costs, the team could identify opportunities for further optimization and regularly adjust their caching strategies to maintain optimal performance.
Looking ahead
Smartsheet continues to innovate with Amazon Bedrock and Roo Code, exploring new ways to enhance developer productivity. Their engineering team is investigating advanced caching strategies and evaluating new FMs as they become available on Amazon Bedrock. The success of this implementation has established a strong foundation for future AI-assisted development initiatives.
Conclusion
Smartsheet’s implementation of Roo Code with Amazon Bedrock and prompt caching demonstrates how organizations can successfully deploy AI-assisted coding solutions while maintaining cost-efficiency. Their approach provides a blueprint for others looking to enhance developer productivity through AI while optimizing operational costs. The combination of strategic implementation, innovative caching solutions, and continuous optimization has enabled Smartsheet to achieve significant improvements in performance and cost metrics.
To learn more about implementing AI solutions at scale, refer to the Amazon Bedrock documentation and explore the AWS Machine Learning Blog. The frameworks and strategies outlined in this post can help organizations of varying size implement efficient, cost-effective AI-assisted development workflows.
About the Authors
Author: Rony Blum