

How Smartsheet reduced latency and optimized costs in their serverless architecture
“To reduce customer request latency while keeping costs low, our engineering team utilized Lambda provisioned concurrency with auto scaling and Graviton, which resulted in an 83% reduction in P95 latency while providing a high quality of service as we continue to scale our platform and its limit…
Cloud software as a service (SaaS) companies are often looking for ways to enhance their architectures for performance and cost-efficiency. Serverless technologies offload infrastructure management, allowing development teams to focus on innovation and delivering business value. As application architectures grow and face more demanding requirements, continued optimization helps maximize both the technical and financial advantages of the serverless approach.
In this post, we discuss Smartsheet’s journey optimizing its serverless architecture. We explore the solution, the stringent requirements Smartsheet faced, and how they’ve achieved an over 80% latency reduction. This technical journey offers valuable insights for organizations looking to enhance their serverless architectures with proven enterprise-grade optimization techniques.
Solution overview
Smartsheet is a leading cloud-based enterprise work management platform, enabling millions of users worldwide to plan, manage, track, automate, and report on work at scale. At the core of the platform lies an event-driven architecture that processes real-time user activity across various document types. Given the collaborative nature of the platform, multiple users can work on these documents concurrently. Every document interaction triggers a series of events that must be processed with minimal latency to maintain data consistency and provide immediate feedback. Processing delays can impact user experience and productivity, making consistently low latency a fundamental business requirement.
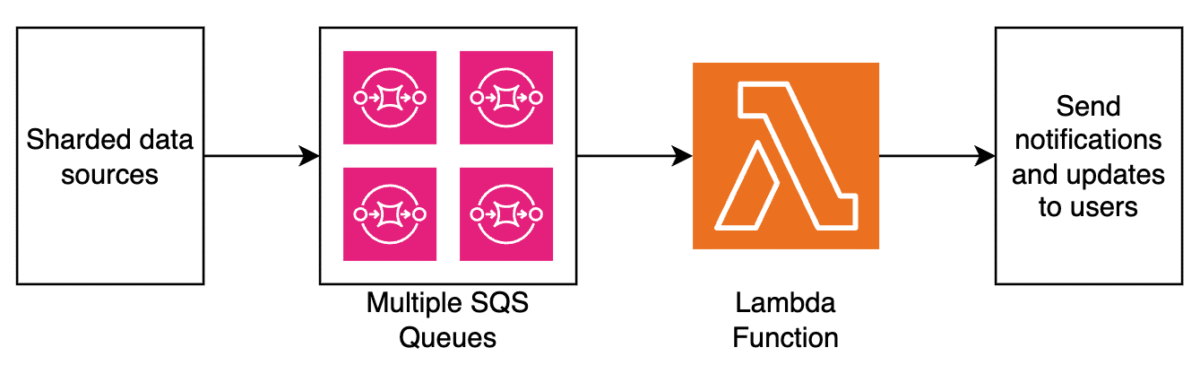
Smartsheet’s traffic pattern is spiky during business hours and mostly dormant during nights and weekends. Within peak periods, traffic can fluctuate as users collaborate in real time. To efficiently manage dynamic workloads, which can surge from hundreds to tens of thousands of events per second within minutes, Smartsheet implements a serverless event processing architecture using services such as Amazon Simple Queue Service (Amazon SQS) and AWS Lambda. This architecture uses the elasticity of serverless services and the ability to automatically scale dynamically based on the traffic volume. It makes sure Smartsheet can efficiently handle sudden traffic surges while automatically scaling down during off-peak hours, optimizing for both performance and cost-efficiency.
The following diagram illustrates the high-level architecture of the Smartsheet event processing pipeline.

Optimization opportunity
Smartsheet uses Lambda functions to serve both batch jobs and API requests. The primary runtime used for building those functions is Java. Lambda automatically scales the number of execution environments allocated to your function on demand to accommodate traffic volume. When Lambda receives an incoming request, it attempts to serve it with an existing execution environment first. If no execution environments are available, the service initializes a new one. During initialization, the Smartsheet’s function code commonly sends several requests to external dependencies, such as databases and REST APIs, which might take time to reply.
The following diagram illustrates how Lambda functions reach out to external dependencies during initialization.

These tasks introduced execution environment initialization latency, commonly referred to as a cold start. Although cold starts typically affect less than 1% of requests, Smartsheet had stringent low latency requirements for their architecture to further prioritize the best possible end-user experience.
“To reduce customer request latency while keeping costs low, our engineering team utilized Lambda provisioned concurrency with auto scaling and Graviton, which resulted in an 83% reduction in P95 latency while providing a high quality of service as we continue to scale our platform and its limits,” says Abhishek Gurunathan, Sr Director of Engineering at Smartsheet.
Addressing the cold start with provisioned concurrency
To reduce cold start latency, the Smartsheet team adopted provisioned concurrency in their architecture, a capability that allows developers to specify the number of execution environments that Lambda should keep warm to instantly handle invocations. The following diagram illustrates the difference. Without provisioned concurrency, execution environments are created on demand, which means some invocations (typically less than 1%) need to wait for the execution environment to be created and initialization code to be run. With provisioned concurrency, Lambda creates execution environments and runs initialization code preemptively, making sure invocations are served by warm execution environments.

Provisioned concurrency includes a dynamic spillover mechanism, making your serverless architecture highly resilient to traffic spikes. When incoming traffic exceeds the preconfigured provisioned concurrency, additional requests are automatically served by on-demand concurrency rather than being throttled. This provides seamless scalability and maintains service availability even during traffic surges, while still providing the performance benefits of pre-warmed execution environments for the majority of requests.
The Smartsheet team configured provisioned concurrency to match their historical P95 concurrency needs. This resulted in immediate improvements—the number of cold starts dropped dramatically and P95 invocation latency dropped by 83%. As the team monitored system performance, they quickly identified another architecture optimization opportunity—the Lambda functions were heavily used during work hours but had significantly fewer invocations at night and on weekends, as illustrated in the following graph.

Setting a static provisioned concurrency configuration worked great for busy periods, but was underutilized during off-times. The Smartsheet team wanted to further fine-tune their architecture and increase provisioned concurrency utilization rates to achieve higher cost-efficiency. This led them to look into provisioned concurrency auto scaling to match traffic patterns as well as adopting an AWS Graviton architecture.
Auto scaling provisioned concurrency and Graviton architecture
Two common approaches to enable provisioned concurrency are setting a static value and using auto scaling. With static configuration, you specify a fixed number of pre-initialized execution environments that remain continuously warm to serve invocations. This approach is highly effective for architectures that handle predictable traffic patterns. Unpredictable traffic patterns, however, can lead to under-provisioning during peak periods (with spillover to on-demand concurrency resulting in more cold starts) or underutilization during low-usage periods. To address that, provisioned concurrency with auto scaling dynamically adjusts the configuration based on utilization metrics, automatically scaling the number of execution environments up or down to match the actual demand. This dynamic approach optimizes for cost-efficiency and is particularly recommended for architectures with fluctuating traffic patterns.
The following figure compares static and dynamic provisioned concurrency.

To further optimize the architecture for cost-efficiency, the Smartsheet team has implemented provisioned concurrency auto scaling based on utilization metrics. Smartsheet used an infrastructure as code (IaC) approach with Terraform to define auto scaling policies for maximum reusability across hundreds of functions. The policies track the LambdaProvisionedConcurrencyUtilization metric and define the scaling threshold according to the function purpose. For functions implementing interactive APIs, the auto scale threshold is 60% utilization to pre-provision execution environments early, keeping latency extra-low, and making functions more resilient towards traffic surges. For functions that implement asynchronous data processing, Smartsheet’s goal was to achieve the highest utilization rate and cost-efficiency, so they’ve defined the auto scale threshold at 90%.
The following diagram illustrates the architecture of auto scaling policies based on provisioned concurrency utilization rate and workload type.
Another optimization technique Smartsheet employed was switching the CPU architecture used by their Lambda functions from x86_64 to arm64 Graviton. To achieve this, Smartsheet adopted the ARM versions of Lambda layers they’ve used, such as Datadog and Lambda Insights extensions. This was required because binaries built using one architecture might be incompatible with a different one. Because Smartsheet functions were implemented with Java and packaged as JAR files, they didn’t have any compatibility issues when moving to Graviton. With Terraform used for codifying the infrastructure, this architecture switch was a simple property change in aws_lambda_function resources, as illustrated in the following code:

By switching to a Graviton architecture, Smartsheet saved 20% on function GB-second costs. See AWS Lambda pricing for details.
Best practices
Use the following techniques and best practices to optimize your serverless architectures, reduce cold starts, and increase cost-efficiency:
- Fine-tune your Lambda functions to find the optimal balance between cost and performance. Increasing memory allocation also adds CPU capacity, which often means faster execution and can lead to reduced overall costs.
- Use a Graviton2 architecture for compatible workloads to benefit from a better price-performance ratio. Depending on the workload type, switching to Graviton can yield up to 34% improvement.
- Use provisioned concurrency and Lambda SnapStart to reduce cold starts in your serverless architectures. Start with static provisioned concurrency based on your historical concurrency requirements, monitor utilization, and introduce auto scaling into your architecture to achieve the optimal cost-performance profile.
Conclusion
Serverless architectures using services like Lambda and Amazon SQS offload the infrastructure management and scaling concerns to AWS, allowing teams to focus on innovation and delivering business value. As Smartsheet’s journey demonstrates, using provisioned concurrency and Graviton in your architectures can help significantly improve user experience by reducing latencies while also achieving better cost-efficiency, providing a practical blueprint for optimization across the organization. Whether you’re running large-scale enterprise applications or building new cloud solutions, these proven techniques can help you unlock similar performance gains and cost-efficiencies in your serverless architectures.
To learn more about serverless architectures, see Serverless Land.
About the authors
Author: Anton Aleksandrov