

How to use chaos engineering in incident response
Why chaos engineering? Chaos engineering is a formalized approach that uses fault injection experiments to create real-world conditions needed to understand how your system will react to unknowns and build confidence in the system’s resiliency and security… To respond to potential security e…
Simulations, tests, and game days are critical parts of preparing and verifying incident response processes. Customers often face challenges getting started and building their incident response function as the applications they build become increasingly complex. In this post, we will introduce the concept of chaos engineering and how you can use it to accelerate your incident response preparation and testing processes.
Why chaos engineering?
Chaos engineering is a formalized approach that uses fault injection experiments to create real-world conditions needed to understand how your system will react to unknowns and build confidence in the system’s resiliency and security.
Modern applications can have multiple components, including web, API, application, and data persistence layers. To respond to potential security events, you must understand the failure scenarios across each component and their downstream impacts. One challenge is that creating incident response processes and playbooks for components in a silo doesn’t consider known unknowns—how these components interact with each other—and can’t reveal unknown unknowns such as second-order effects during a security event.
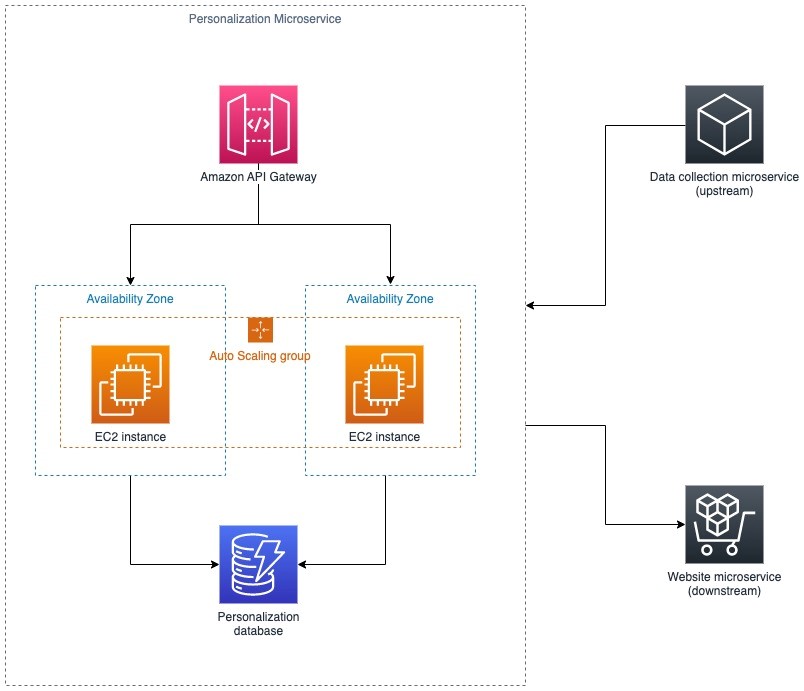
As an example, consider the personalization microservice shown in Figure 1.
The microservice relies on two Amazon Elastic Compute Cloud (Amazon EC2) instances that are deployed in an auto scaling group across two Availability Zones. An upstream data collection microservice sends data for the personalization microservice to process. In addition, a downstream website microservice takes the personalized data and displays it to customers.

Figure 1: Architecture of the personalization microservice
Now imagine that unexpected activity occurred on an EC2 instance. The instance started to query a domain name that’s associated with cryptocurrency-related activity. A first set of unknowns already emerges:
- Can your detective controls detect the activity on the instance?
- How long do they take to do so?
- How long does it take your security team to be notified?
- Does the security team know what to do?
- Does the notification have all the information that the team needs to respond?
- Is there an existing automated response to other stakeholders?
Security professionals may not consider all of these questions when building and designing their threat detection and incident response capabilities.
In our example, Amazon GuardDuty is able to detect the unexpected activity and generates the CryptoCurrency:EC2/BitcoinTool.B!DNS finding within 15 minutes. The security team takes a snapshot for further forensics before the instance is isolated, as shown in Figure 2.

Figure 2: Architecture after GuardDuty detects unexpected activity and the security team isolates the EC2 instance
Although this might seem like an adequate response in isolation, it leads to more questions.
From a security perspective:
- What other logs do we need for further investigation?
- Do we know if the credentials need to be rotated and what impact that will have on the workload?
- Should other parts of the system be replaced or restarted?
From an operational perspective:
- Do any of the (manual or automated) incident response processes impact the performance of the workload?
- Can the remaining instance handle the traffic before the auto scaling group creates another instance?
- If there is increased latency or failure of the microservice, how will the data collection and website microservices react to it?
Creating detection and incident response plans in isolation doesn’t consider the second order effects that could have an impact on the integrity and availability of the system.
How can chaos engineering help?
Chaos engineering is a formalized process that can help solve this problem. It creates failure in a controlled environment with well-defined experiments to generate data on system behavior during a simulated event. You can use this data to improve incident response processes and make proactive changes that improve the security of your workloads. By using chaos engineering, developer and security teams can reveal additional unknowns and understand areas of opportunity to improve incident response processes and workload availability.
Chaos engineering has five phases—steady state, hypothesis, run experiment, verify, and improve—which we’ll discuss in more detail next.
Steady state
The first phase involves an understanding of the behavior and configuration of the system under normal conditions. Instead of focusing on the internal attributes of the system, you should focus on an output metric or indicator that ties operational metrics and customer experience together. Including these output metrics in your hypothesis helps you collect data on security events and understand how these events and your response to them impact business outcomes.
Returning to our earlier example, this could be the latency when a user attempts to retrieve personalized information. This output is critical to the customer experience and relies on multiple operational metrics.
In addition, two key metrics in incident response are time to detect (TTD) and time to remediate (TTR). These metrics help capture how effectively your team has responded to the security event.
By defining your steady state, you can detect deviations from that state and determine if your system has fully returned to the known good state. You should identify the relevant metrics to measure your system and make these metrics simple for engineers to consume.
Using AWS, you can collect logs from the different services that you use in a workload, such as Amazon VPC Flow Logs, Amazon CloudWatch log groups, and AWS CloudTrail. For more details about the different log sources, see Logging strategies for security incident response.
Hypothesis
After you understand the steady state behavior, you can write a hypothesis about it. Security hypotheses can take the following form:
When _________ happens, ________ system will notify the team within _______ and the application’s metric _________ will remain at ________.
It can be challenging to decide what should happen. Chaos engineering recommends that you choose real-world events that are likely to occur and that will impact the user experience. Get your team to brainstorm. For security issues, this is an ideal time to use your threat model as the starting point for discussions. Starting with one of your identified threats and then running experiments based on that threat can help you test both your processes and automation.
After you’ve chosen your component, decide which variable to influence or what could happen in your complex system. For example, a misconfigured Amazon Simple Storage Service (Amazon S3) bucket or an open database port could lead to unintended exposure of customer data. A software flaw in your application could lead to the misuse of resources by an unauthorized user.
Here are a few examples of hypotheses:
- If port 22 permits unrestricted access on a security group, AWS Config will detect it, run an automation to remove the security group rule, and notify the security team through Slack within 5 minutes, and the application’s latency will remain at 0.005 seconds.
- If malware is run on an EC2 instance, Amazon GuardDuty will detect it within 15 minutes and notify the security team. Remediation playbooks will not affect the application’s error rate of 1 error for every thousand requests.
Design and run the experiment
The next phase is to run the experiment. You don’t need to run experiments in production right away. A great place to get started with chaos engineering is the staging environment. One benefit of the AWS Cloud is that you can configure your staging environment to be identical to production. This increases the value of using an approach like chaos engineering before you get to production. By running experiments in staging, you can see how your system will likely react in production while earning trust within your organization.
As you gain confidence, you can begin running experiments in production. Because you configured staging to be identical to production, the risk of this transition is mitigated.
You can use AWS Fault Injection Simulator (FIS), our fully managed service for running fault injection experiments. FIS supports multiple fault injection actions, such as injecting API errors, restarting instances, running scripts on instances, disrupting network connectivity, and more. For the full list, see the FIS actions reference.
Although FIS doesn’t support security-related actions out of the box, you can use FIS to run AWS Systems Manager Automation documents that can run AWS APIs and scripts to simulate security events. To learn how to set up FIS to run a Systems Manager document that turns off bucket-level block public access for a randomly-selected S3 bucket, see the workshop Chaos Kitty – Gamifying Incident Response with Chaos Engineering. To learn how to set up FIS to run experiments that simulate events such as an RDP brute force event, lateral movement, cryptocurrency mining, and DNS data exfiltration, see the workshop Validating security guardrails with Chaos Engineering.
During this phase, you must understand the scope of impact of your experiment and work to minimize it. If an Amazon CloudWatch alarm goes into an alarm state, FIS can automatically stop the experiment. You should have a plan to return the environment to the steady state if the experiment has an unintended impact.
As you run your experiment, remember to document the key metrics and human responses, such as whether incident responders were confident, knew where to find the correct resources, or were aware of the escalation points.
Learn and verify
The next step is to analyze and document the data to understand what happened. Lessons learned during the experiment are critical and should promote a culture of support instead of blame.
Here are some questions that you should address:
- What happened?
- What was the impact on our customers?
- What did we learn? Did we have enough information in the notification to investigate?
- What could have reduced our time to detect or time to remediate by 50 percent?
- Can we apply this to other similar systems?
- How can we improve our incident response processes?
- What human steps in the process can we automate?
Here are a few examples of things you might learn from your chaos engineering experiments:
- After port 22 was opened, AWS Config detected the misconfigured security group within 2 minutes. However, the notification system was misconfigured, and the security team wasn’t notified. During the five minutes that port 22 was opened, the EC2 instance received 22 attempts to connect to it from unknown IP addresses.
- After a cryptocurrency mining script was run on an EC2 instance, GuardDuty detected the activity, generated a finding within 10 minutes, and notified the security team.
- The security team’s remediation actions—terminating the instance—led to increased application latency beyond the SLA of 0.05 seconds.
Improve and fix it
Use your learnings to improve the workload. It’s vital that you get leadership alignment and support to prioritize the remediation of findings from chaos experiments or other testing scenarios. Examples include improving incident response playbooks, creating new forms of automation, or creating preventative controls to prevent the event from happening. For more guidance on playbooks, see these sample incident response playbooks and the workshop Building an AWS incident response runbook using Jupyter notebooks and CloudTrail Lake.
Preparation is important in incident response. As you improve your processes, run more experiments to collect additional data and continue to iteratively improve. Automate chaos experiments on new environments or applications with minimal user traffic before directing the majority of traffic to it. As you use chaos engineering approaches to prepare incident response processes, your detection and incident response capabilities should improve.
Conclusion
It’s vital to be prepared when a security event happens. In this blog post, you learned about the five phases of chaos engineering—steady state, hypothesis, design and run the experiment, learn and verify, and improve and fix—and how you can use them to accelerate your incident response preparation and testing processes. For more information on chaos engineering, see the following resources. Choose a workload and run an experiment on it to verify and improve your incident response processes today.
Additional resources
- Chaos Engineering: System Resiliency in Practice
- Security Chaos Engineering: Sustaining Resilience in Software and Systems
- Chaos Engineering – Part 1: The art of breaking things purposefully
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.
Want more AWS Security news? Follow us on Twitter.
Author: Kevin Low