

Implement event-driven invoice processing for resilient financial monitoring at scale
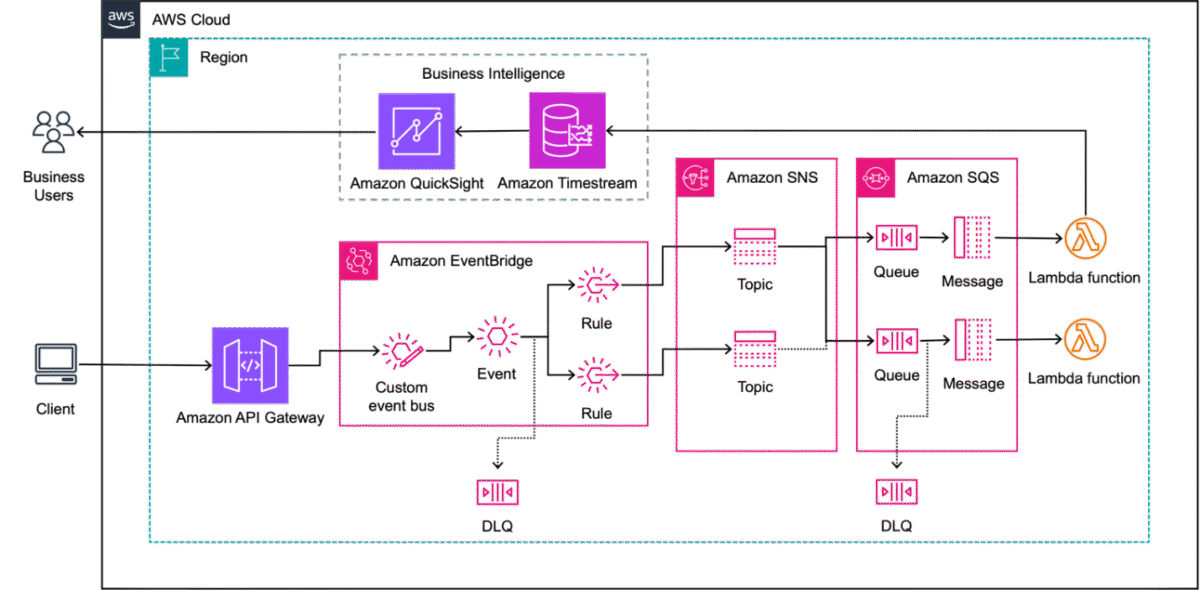
A customer recently consulted us on how they could implement a monitoring system to help them process and visualize large volumes of invoice status events… This post demonstrates how to build a Business Event Monitoring System (BEMS) on AWS that handles over 86 million daily events with near rea…
Processing high volumes of invoices efficiently while maintaining low latency, high availability, and business visibility is a challenge for many organizations. A customer recently consulted us on how they could implement a monitoring system to help them process and visualize large volumes of invoice status events.
This post demonstrates how to build a Business Event Monitoring System (BEMS) on AWS that handles over 86 million daily events with near real-time visibility, cross-Region controls, and automated alerts for stuck events. You might deploy this system for business-level insights into how events are flowing through your organization or to visualize the flow of transactions in real time. Downstream services also will have the option to process and respond to events originating within the system or not.
Business challenge
For our use case, a global enterprise wants to deploy a monitoring system for their invoice event pipeline. The pipeline processes millions of events per period, projected to surge 40% within 18 months. Each invoice must navigate a four-stage journey while making sure every event is visible within 2 minutes. End-of-month invoice surges reach 60,000 events per minute or up to 86 million per day. With payment terms spanning from standard 30-day windows to year-long arrangements, the architecture demands zero tolerance for missing events. Finance executives require near real-time visibility through dashboards, and auditors demand comprehensive historical retrieval.
Solution overview
The architecture implements a serverless event-driven system broken into independently deployable Regional cells, as illustrated in the following diagram.

The solution uses the following key services:
- Amazon API Gateway – Clients want to send events into our solution using HTTPS calls to a REST API. API Gateway was selected due to its support for REST, event-based integrations with other AWS services, and its support for throttling to prevent individual callers from creating a system overload.
- Amazon EventBridge – Events created by API Gateway need to be routed to downstream consumers and archived where events can be replayed later. EventBridge provides a custom event bus that defines rules to intelligently route events based on their contents.
- Amazon Simple Notification Service (Amazon SNS) – To keep EventBridge rules simple, events are routed by type to one or more destinations for fanout. SNS topics are used as routing targets to activate fanout to a variety of downstream consumers with optional subscription filters to control which events are received by consumers.
- Amazon Simple Queue Service (Amazon SQS) – Each SNS topic fans out by sending a copy of each message to each consumer subscribed to the topic. Consumers receive messages through Amazon SQS, which decouples event processing compute and provides dead-letter queues (DLQs) for storing messages that fail to process. EventBridge custom event buses and SNS FIFO (First-In-First-Out) topics can also use DLQs powered by Amazon SQS.
- AWS Lambda – The Lambda architecture aligns with short-lived processing tasks, spinning up when needed and disappearing afterward without incurring idle resource costs. This integration between Lambda and Amazon SQS delivers an economical processing system that automatically scales with demand, allowing developers to focus on business logic rather than infrastructure orchestration, and the pay-per-execution model provides financial efficiency.
- Amazon Timestream – Timestream offers a purpose-built architecture that addresses the unique challenges of time series data, auto scaling to ingest millions of events while maintaining fast query performance for responsive dashboard visualizations. Its intelligent tiered storage system automatically transitions data between memory and cost-effective long-term storage without sacrificing analytics capabilities, enabling organizations to maintain both real-time operational visibility and historical trending insights through a single, unified platform that integrates with QuickSight.
- Amazon QuickSight – QuickSight transforms event streams into visual narratives through its intuitive interface, empowering business users to discover actionable insights without specialized data science expertise. Its serverless architecture scales to accommodate millions of users while offering machine learning (ML)-powered anomaly detection and forecasting capabilities, all within a pay-per-session pricing model that activates sophisticated analytics that would otherwise require significant resources. QuickSight dashboards can either directly query from a Timestream table or cache records in-memory with SPICE periodically.
Events flow through the layers of this architecture in four stages:
- Event producers – API Gateway for receiving client events through a REST API
- Event routing – EventBridge routes events to SNS topics for fanout
- Event consumers – SQS queues with Lambda or Fargate consumers
- Business intelligence – Timestream and QuickSight for dashboards
Design tenets
The solution adheres to three key architectural principles:
- Cellular architecture – In a cellular architecture, your workload scales through independent deployment units like the one depicted in the previous section. Each unit operates as a self-contained cell, and more cells can be deployed to different AWS Regions or AWS accounts to further increase throughput. Cellular design activates independent scaling of resources based on local load and limits the area of effect of failures.
- Serverless architecture – In a serverless architecture, operational overhead of scaling is minimized by using managed services. We use Lambda for compute-intensive tasks like fanning out messages to thousands of micro-consumers or employing container-based services (AWS Fargate) for longer-running processes.
- Highly available design – We maintain the availability of our overall financial system through Multi-AZ resilience at every layer. Automatic failover and disaster recovery procedures can be implemented without altering the architecture. We also use replication, archival, and backup strategies to prevent data loss in the event of cell failure.
Scaling constraints
Our solution will experience the following scaling bottlenecks with quotas sampled from the us-east-1 Region:
- API Gateway quota: Throttling at 10,000 requests per second (RPS); can be increased
- EventBridge service quotas:
PutEventsthrottle limit at 10,000 transactions per second (TPS); can be increased- Invocations throttle limit at 18,750 TPS; can be increased
- Amazon SNS service quotas: Publish API throttling at 30,000 messages per second (MPS); can be increased
- Amazon SQS service quotas: Messages per queue (in flight) throttled at 120,000; can be increased
- Lambda service quotas: 1,000 concurrent executions or up to 10,000 RPS; can be increased
We can safely scale a single account to 10,000 requests per second (600,000 per minute, 864 million per day) without increasing service quotas in the us-east-1 Region. Default quotas will vary per Region and the values can be increased by raising a support ticket. The architecture scales even further by deploying independent cells into multiple Regions or AWS accounts.
Scaling of QuickSight and Timestream depends on the computational complexity of analysis, the window of time being analyzed, and the number of users concurrently analyzing the data, which was not a scaling bottleneck in our use case.
Prerequisites
Before implementing this solution, make sure you have the following:
- An AWS account with administrator access
- The AWS Command Line Interface (AWS CLI) version 2.0 or later installed and configured
- Appropriate AWS service quotas confirmed for high-volume processing
In the following sections, we walk through the steps for our implementation strategy.
Decide on partitioning strategies
First, you must decide how your solution will partition requests between cells. In our use case, dividing cells by Region allows us to offer low-latency local processing for events while keeping each cell fully independent from one another.
Inside of each cell, traffic flow is roughly evenly divided between the four stages of invoice processing. Our solution breaks each cell into four logical partitions or flows by invoice status (authorization, reconciliation, and so on). Partitioning offers the ability to fan out and scale resources independently based on traffic patterns specific to each partition.
To partition your cellular architecture, consider the volume, distribution, and access pattern of the events that will flow through each cell. You must allow independent scaling within your cells without encountering global service limits. Choose a strategy that allows each cell to be broken into 1–99 roughly equivalent partitions based on predictable attributes.
Implement the event routing layer
The event routing layer combines EventBridge for intelligent routing with Amazon SNS for efficient fanout.
EventBridge custom event bus configuration
Create a custom event bus with rules to route events based on your partitioning strategy:
- Use content-based filtering to direct events to appropriate SNS topics
- Implement an archive to replay events from history if processing fails
Define a standard event schema for common metadata, including:
- Invoice ID, amount, currency, status, timestamp
- Vendor information and payment terms
- Processing metadata (Region, account ID, and so on)
SNS topic structure
Create SNS topics for each logical partition:
invoice-ingestioninvoice-reconciliationinvoice-authorizationinvoice-posting
Implement message filtering at the subscription level for granular control of which messages subscribing consumers see. Each topic can fan out to a large variety of downstream consumers that are also waiting for events that match the EventBridge custom event bus rules. Delivery failures will be retried automatically up to a configurable limit.

Implement event producers
Configure API Gateway to receive events from existing systems with built-in throttling and error handling.
API design
Create a RESTful API with resources and a path for each logical partition inside your cell:
/invoices/ingestion(POST)/invoices/reconciliation(POST)/invoices/authorization(POST)/invoices/posting(POST)
Implement request validation using a JSON schema for each endpoint. Use API Gateway request transformations to standardize incoming data and provide well-formatted error messages and response codes to clients in the event of failures.
Security and throttling
Implement API keys and usage plans for client authentication and rate limiting to prevent a talkative upstream from bringing down the system. Configure AWS WAF rules to protect against common attacks against API endpoints. Set up throttling to handle burst traffic (60,000 events/minute) at the account level and the method level.
Monitoring and logging
Our partitioned event producer strategy allows your solution to independently monitor each event type by:
- Enabling Amazon CloudWatch Logs for API Gateway with log retention policies
- Setting up AWS X-Ray tracing for end-to-end request analysis
- Implementing custom metrics for monitoring API performance and usage patterns

Implement event consumers
Implement durable processing using SQS queues with DLQs attached and serverless Lambda consumers.
SQS queue structure
Create SQS queues in front of each consumer to decouple message delivery and processing, in our case one per partition:
invoice-ingestion.fifoinvoice-reconciliation.fifoinvoice-authorization.fifoinvoice-posting.fifo
Set up DLQs for each main queue:
- Configure maximum receives before moving to the DLQ
- Implement alerting for stuck messages in the DLQ

Lambda consumers
Attach Lambda functions to each queue for custom processing of events:
InvoiceIngestionProcessorInvoiceReconciliationProcessorInvoiceAuthorizationProcessorInvoicePostingProcessor
Functions handle necessary transformations, call downstream services, and load events into Timestream. Double-check concurrency limits and provisioned concurrency to cover peak and sustained load, respectively.
Error handling and retry logic
Develop a custom retry mechanism for business logic failures and exponential backoff for transient errors. Create an operations dashboard with alerts and metrics for monitoring stuck events to redrive.
Build the business intelligence dashboard
Use Timestream and QuickSight to create real-time financial event dashboards.
Timestream data model
When modeling real-time invoice events in Timestream, using multi-measure records provides optimal efficiency by designating invoice ID as a dimension while storing processing timestamps, amounts, and status as measures within single records. This approach creates a cohesive time series view of each invoice’s lifecycle while minimizing data fragmentation.
Multi-measure modeling is preferable because it significantly reduces storage requirements and query complexity, enabling more efficient time-based analytics. The resulting performance improvements are particularly valuable for dashboards that need to visualize invoice processing metrics in real time, because they can retrieve complete invoice histories with fewer operations and lower latency, ultimately delivering a more responsive monitoring solution.
Real-time data ingestion
Create a Lambda function to push metrics to Timestream:
- Trigger on every status change in the invoice lifecycle
- Batch writes for improved performance during high-volume periods
QuickSight dashboard design
Develop interactive QuickSight dashboards for different user personas:
- Executive overview – High-level KPIs and trends
- Operations dashboard – Detailed processing metrics and bottlenecks
- Finance dashboard – Cash flow projections and payment analytics

Don’t forget to implement ML-powered anomaly detection for identifying unusual patterns in your events.
Monitoring and alerting
Set up CloudWatch alarms for key metrics:
- Processing latency exceeding Service-Level Agreements (SLAs)
- Error rates above expected percentage for any processing stage
- Queue depth exceeding predefined thresholds
Configure SNS topics for alerting finance teams and operations:
- Use different topics for varying alert severities
- Implement automated escalation for critical issues
Develop custom CloudWatch dashboards for system-wide monitoring:
- End-to-end processing visibility
- Regional performance comparisons
Security
Add permissions in a least privilege manner for each required service listed in the architecture:
- Create separate execution roles for each Lambda function
- Implement role assumption for cross-account operations
Encrypt data at rest and in transit:
- Use AWS Key Management Service (AWS KMS) for managing encryption keys
- Implement field-level encryption for sensitive data
Set up AWS Config rules to maintain compliance with internal policies:
- Monitor for unapproved resource configurations
- Automate remediation for common violations
Use AWS CloudTrail for comprehensive auditing:
- Enable organization-wide trails
- Implement log analysis for detecting suspicious activities
Conclusion
The serverless event-driven architecture presented in this post enables processing of over 86 million daily invoices while maintaining near real-time visibility, strict compliance with internal policies, cellular scaling capabilities, and minimal operational overhead. This solution provides a robust foundation for modernizing financial operations, enabling organizations to handle the complexities of high-volume invoice processing with confidence and agility.
For further enhancements, consider exploring:
- Machine learning for predictive analytics on event patterns
- Implementing AWS Step Functions for complex, multi-stage workflows
- Integrating with AWS Lake Formation for centralized data governance and analytics
About the author
Author: Grey Newell