

Implement serverless semantic search of image and live video with Amazon Titan Multimodal Embeddings
In today’s data-driven world, industries across various sectors are accumulating massive amounts of video data through cameras installed in their warehouses, clinics, roads, metro stations, stores, factories, or even private facilities… This video data holds immense potential for analysis and mo…
In today’s data-driven world, industries across various sectors are accumulating massive amounts of video data through cameras installed in their warehouses, clinics, roads, metro stations, stores, factories, or even private facilities. This video data holds immense potential for analysis and monitoring of incidents that may occur in these locations. From fire hazards to broken equipment, theft, or accidents, the ability to analyze and understand this video data can lead to significant improvements in safety, efficiency, and profitability for businesses and individuals.
This data allows for the derivation of valuable insights when combined with a searchable index. However,traditional video analysis methods often rely on manual, labor-intensive processes, making it challenging to scale and efficient. In this post, we introduce semantic search, a technique to find incidents in videos based on natural language descriptions of events that occurred in the video. For example, you could search for “fire in the warehouse” or “broken glass on the floor.” This is where multi-modal embeddings come into play. We introduce the use of the Amazon Titan Multimodal Embeddings model, which can map visual as well as textual data into the same semantic space, allowing you to use textual description and find images containing that semantic meaning. This semantic search technique allows you to analyze and understand frames from video data more effectively.
We walk you through constructing a scalable, serverless, end-to-end semantic search pipeline for surveillance footage with Amazon Kinesis Video Streams, Amazon Titan Multimodal Embeddings on Amazon Bedrock, and Amazon OpenSearch Service. Kinesis Video Streams makes it straightforward to securely stream video from connected devices to AWS for analytics, machine learning (ML), playback, and other processing. It enables real-time video ingestion, storage, encoding, and streaming across devices. Amazon Bedrock is a fully managed service that provides access to a range of high-performing foundation models from leading AI companies through a single API. It offers the capabilities needed to build generative AI applications with security, privacy, and responsible AI. Amazon Titan Multimodal Embeddings, available through Amazon Bedrock, enables more accurate and contextually relevant multimodal search. It processes and generates information from distinct data types like text and images. You can submit text, images, or a combination of both as input to use the model’s understanding of multimodal content. OpenSearch Service is a fully managed service that makes it straightforward to deploy, scale, and operate OpenSearch. OpenSearch Service allows you to store vectors and other data types in an index, and offers sub second query latency even when searching billions of vectors and measuring the semantical relatedness, which we use in this post.
We discuss how to balance functionality, accuracy, and budget. We include sample code snippets and a GitHub repo so you can start experimenting with building your own prototype semantic search solution.
Overview of solution
The solution consists of three components:
- First, you extract frames of a live stream with the help of Kinesis Video Streams (you can optionally extract frames of an uploaded video file as well using an AWS Lambda function). These frames can be stored in an Amazon Simple Storage Service (Amazon S3) bucket as files for later processing, retrieval, and analysis.
- In the second component, you generate an embedding of the frame using Amazon Titan Multimodal Embeddings. You store the reference (an S3 URI) to the actual frame and video file, and the vector embedding of the frame in OpenSearch Service.
- Third, you accept a textual input from the user to create an embedding using the same model and use the API provided to query your OpenSearch Service index for images using OpenSearch’s intelligent vector search capabilities to find images that are semantically similar to your text based on the embeddings generated by the Amazon Titan Multimodal Embeddings model.
This solution uses Kinesis Video Streams to handle any volume of streaming video data without consumers provisioning or managing any servers. Kinesis Video Streams automatically extracts images from video data in real time and delivers the images to a specified S3 bucket. Alternatively, you can use a serverless Lambda function to extract frames of a stored video file with the Python OpenCV library.
The second component converts these extracted frames into vector embeddings directly by calling the Amazon Bedrock API with Amazon Titan Multimodal Embeddings.
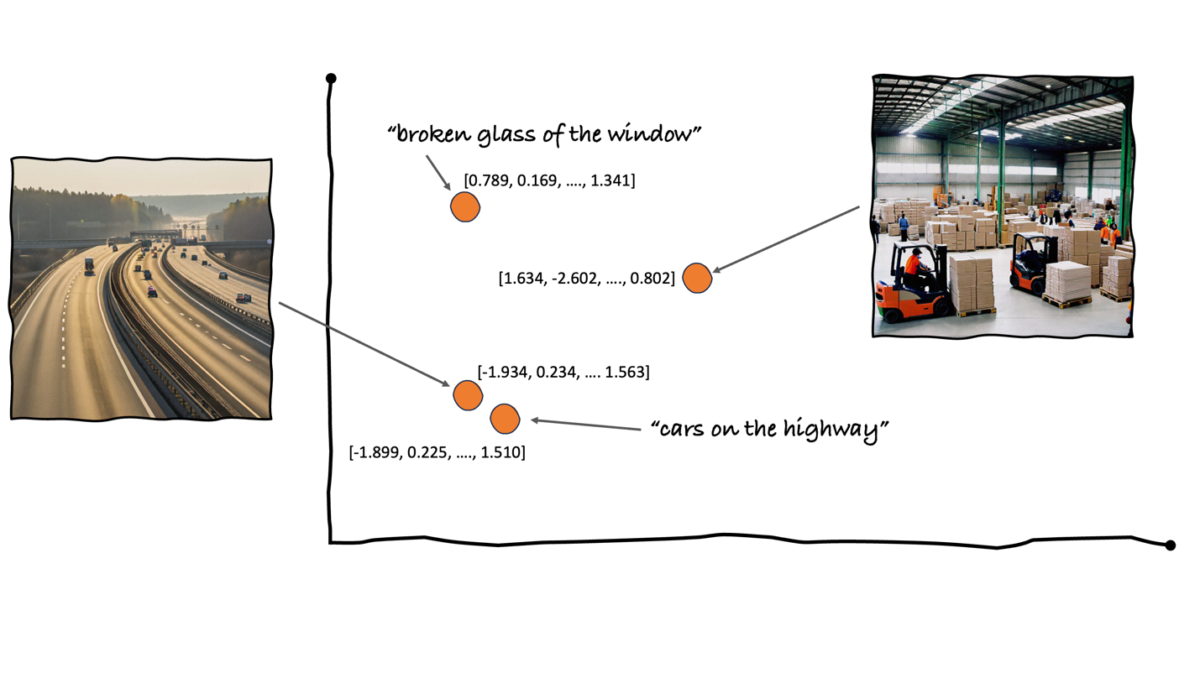
Embeddings are a vector representation of your data that capture semantic meaning. Generating embeddings of text and images using the same model helps you measure the distance between vectors to find semantic similarities. For example, you can embed all image metadata and additional text descriptions into the same vector space. Close vectors indicate that the images and text are semantically related. This allows for semantic image search—given a text description, you can find relevant images by retrieving those with the most similar embeddings, as represented in the following visualization.

Starting December 2023, you can use the Amazon Titan Multimodal Embeddings model for use cases like searching images by text, image, or a combination of text and image. It produces 1,024-dimension vectors (by default), enabling highly accurate and fast search capabilities. You can also configure smaller vector sizes to optimize for cost vs. accuracy. For more information, refer to Amazon Titan Multimodal Embeddings G1 model.
The following diagram visualizes the conversion of a picture to a vector representation. You split the video files into frames and save them in a S3 bucket (Step 1). The Amazon Titan Multimodal Embeddings model converts these frames into vector embeddings (Step 2). You store the embeddings of the video frame as a k-nearest neighbors (k-NN) vector in your OpenSearch Service index with the reference to the video clip and the frame in the S3 bucket itself (Step 3). You can add additional descriptions in an additional field.

The following diagram visualizes the semantic search with natural language processing (NLP). The third component allows you to submit a query in natural language (Step 1) for specific moments or actions in a video, returning a list of references to frames that are semantically similar to the query. The Amazon Titan MultimodalEmbeddings model (Step 2) converts the submitted text query into a vector embedding (Step 3). You use this embedding to look up the most similar embeddings (Step 4). The stored references in the returned results are used to retrieve the frames and video clip to the UI for replay (Step 5).

The following diagram shows our solution architecture.

The workflow consists of the following steps:
- You stream live video to Kinesis Video Streams. Alternatively, upload existing video clips to an S3 bucket.
- Kinesis Video Streams extracts frames from the live video to an S3 bucket. Alternatively, a Lambda function extracts frames of the uploaded video clips.
- Another Lambda function collects the frames and generates an embedding with Amazon Bedrock.
- The Lambda function inserts the reference to the image and video clip together with the embedding as a k-NN vector into an OpenSearch Service index.
- You submit a query prompt to the UI.
- A new Lambda function converts the query to a vector embedding with Amazon Bedrock.
- The Lambda function searches the OpenSearch Service image index for any frames matching the query and the k-NN for the vector using cosine similarity and returns a list of frames.
- The UI displays the frames and video clips by retrieving the assets from Kinesis Video Streams using the saved references of the returned results. Alternatively, the video clips are retrieved from the S3 bucket.
This solution was created with AWS Amplify. Amplify is a development framework and hosting service that assists frontend web and mobile developers in building secure and scalable applications with AWS tools quickly and efficiently.
Optimize for functionality, accuracy, and cost
Let’s conduct an analysis of this proposed solution architecture to determine opportunities for enhancing functionality, improving accuracy, and reducing costs.
Starting with the ingestion layer, refer to Design considerations for cost-effective video surveillance platforms with AWS IoT for Smart Homes to learn more about cost-effective ingestion into Kinesis Video Streams.
The extraction of video frames in this solution is configured using Amazon S3 delivery with Kinesis Video Streams. A key trade-off to evaluate is determining the optimal frame rate and resolution to meet the use case requirements balanced with overall system resource utilization. The frame extraction rate can range from as high as five frames per second to as low as one frame every 20 seconds. The choice of frame rate can be driven by the business use case, which directly impacts embedding generation and storage in downstream services like Amazon Bedrock, Lambda, Amazon S3, and the Amazon S3 delivery feature, as well as searching within the vector database. Even when uploading pre-recorded videos to Amazon S3, thoughtful consideration should still be given to selecting an appropriate frame extraction rate and resolution. Tuning these parameters allows you to balance your use case accuracy needs with consumption of the mentioned AWS services.
The Amazon Titan Multimodal Embeddings model outputs a vector representation with an default embedding length of 1,024 from the input data. This representation carries the semantic meaning of the input and is best to compare with other vectors for optimal similarity. For best performance, it’s recommended to use the default embedding length, but it can have direct impact on performance and storage costs. To increase performance and reduce costs in your production environment, alternate embedding lengths can be explored, such as 256 and 384. Reducing the embedding length also means losing some of the semantic context, which has a direct impact on accuracy, but improves the overall speed and optimizes the storage costs.
OpenSearch Service offers on-demand, reserved, and serverless pricing options with general purpose or storage optimized machine types to fit different workloads. To optimize costs, you should select reserved instances to cover your production workload base, and use on-demand, serverless, and convertible reservations to handle spikes and non-production loads. For lower-demand production workloads, a cost-friendly alternate option is using pgvector with Amazon Aurora PostgreSQL Serverless, which offers lower base consumption units as compared to Amazon OpenSearch Serverless, thereby lowering the cost.
Determining the optimal value of K in the k-NN algorithm for vector similarity search is significant for balancing accuracy, performance, and cost. A larger K value generally increases accuracy by considering more neighboring vectors, but comes at the expense of higher computational complexity and cost. Conversely, a smaller K leads to faster search times and lower costs, but may lower result quality. When using the k-NN algorithm with OpenSearch Service, it’s essential to carefully evaluate the K parameter based on your application’s priorities—starting with smaller values like K=5 or 10, then iteratively increasing K if higher accuracy is needed.
As part of the solution, we recommend Lambda as the serverless compute option to process frames. With Lambda, you can run code for virtually any type of application or backend service—all with zero administration. Lambda takes care of everything required to run and scale your code with high availability.
With high amounts of video data, you should consider binpacking your frame processing tasks and running a batch computing job to access a large amount of compute resources. The combination of AWS Batch and Amazon Elastic Container Service (Amazon ECS) can efficiently provision resources in response to jobs submitted in order to eliminate capacity constraints, reduce compute costs, and deliver results quickly.
You will incur costs when deploying the GitHub repo in your account. When you are finished examining the example, follow the steps in the Clean up section later in this post to delete the infrastructure and stop incurring charges.
Refer to the README file in the repository to understand the building blocks of the solution in detail.
Prerequisites
For this walkthrough, you should have the following prerequisites:
- An AWS account with sufficient AWS Identity and Access Management (IAM) permissions
- Model access enabled for Amazon Bedrock Titan Multimodal Embeddings G1
- The AWS Command Line Interface (AWS CLI) installed
- The AWS Amplify CLI set up
Deploy the Amplify application
Complete the following steps to deploy the Amplify application:
- Clone the repository to your local disk with the following command:
- Change the directory to the cloned repository.
- Initialize the Amplify application:
- Clean install the dependencies of the web application:
- Create the infrastructure in your AWS account:
- Run the web application in your local environment:
Create an application account
Complete the following steps to create an account in the application:
- Open the web application with the stated URL in your terminal.
- Enter a user name, password, and email address.
- Confirm your email address with the code sent to it.
Upload files from your computer
Complete the following steps to upload image and video files stored locally:
- Choose File Upload in the navigation pane.
- Choose Choose files.
- Select the images or videos from your local drive.
- Choose Upload Files.
Upload files from a webcam
Complete the following steps to upload images and videos from a webcam:
- Choose Webcam Upload in the navigation pane.
- Choose Allow when asked for permissions to access your webcam.
- Choose to either upload a single captured image or a captured video:
- Choose Capture Image and Upload Image to upload a single image from your webcam.
- Choose Start Video Capture, Stop Video Capture, and finally
Upload Video to upload a video from your webcam.
Search videos
Complete the following steps to search the files and videos you uploaded.
- Choose Search in the navigation pane.
- Enter your prompt in the Search Videos text field. For example, we ask “Show me a person with a golden ring.”
- Lower the confidence parameter closer to 0 if you see fewer results than you were originally expecting.
The following screenshot shows an example of our results.

Clean up
Complete the following steps to clean up your resources:
- Open a terminal in the directory of your locally cloned repository.
- Run the following command to delete the cloud and local resources:
Conclusion
A multi-modal embeddings model has the potential to revolutionize the way industries analyze incidents captured with videos. AWS services and tools can help industries unlock the full potential of their video data and improve their safety, efficiency, and profitability. As the amount of video data continues to grow, the use of multi-modal embeddings will become increasingly important for industries looking to stay ahead of the curve. As innovations like Amazon Titan foundation models continue maturing, they will reduce the barriers to use advanced ML and simplify the process of understanding data in context. To stay updated with state-of-the-art functionality and use cases, refer to the following resources:
- Build an active learning pipeline for automatic annotation of images with AWS services
- Moderate Stable Diffusion model-generated content in near-real time
- Cost-effective document classification using the Amazon Titan Multimodal Embeddings Model
About the Authors
 Thorben Sanktjohanser is a Solutions Architect at Amazon Web Services supporting media and entertainment companies on their cloud journey with his expertise. He is passionate about IoT, AI/ML and building smart home devices. Almost every part of his home is automated, from light bulbs and blinds to vacuum cleaning and mopping.
Thorben Sanktjohanser is a Solutions Architect at Amazon Web Services supporting media and entertainment companies on their cloud journey with his expertise. He is passionate about IoT, AI/ML and building smart home devices. Almost every part of his home is automated, from light bulbs and blinds to vacuum cleaning and mopping.
 Talha Chattha is an AI/ML Specialist Solutions Architect at Amazon Web Services, based in Stockholm, serving key customers across EMEA. Talha holds a deep passion for generative AI technologies. He works tirelessly to deliver innovative, scalable, and valuable ML solutions in the space of large language models and foundation models for his customers. When not shaping the future of AI, he explores scenic European landscapes and delicious cuisines.
Talha Chattha is an AI/ML Specialist Solutions Architect at Amazon Web Services, based in Stockholm, serving key customers across EMEA. Talha holds a deep passion for generative AI technologies. He works tirelessly to deliver innovative, scalable, and valuable ML solutions in the space of large language models and foundation models for his customers. When not shaping the future of AI, he explores scenic European landscapes and delicious cuisines.
 Victor Wang is a Sr. Solutions Architect at Amazon Web Services, based in San Francisco, CA, supporting innovative healthcare startups. Victor has spent 6 years at Amazon; previous roles include software developer for AWS Site-to-Site VPN, AWS ProServe Consultant for Public Sector Partners, and Technical Program Manager for Amazon RDS for MySQL. His passion is learning new technologies and traveling the world. Victor has flown over a million miles and plans to continue his eternal journey of exploration.
Victor Wang is a Sr. Solutions Architect at Amazon Web Services, based in San Francisco, CA, supporting innovative healthcare startups. Victor has spent 6 years at Amazon; previous roles include software developer for AWS Site-to-Site VPN, AWS ProServe Consultant for Public Sector Partners, and Technical Program Manager for Amazon RDS for MySQL. His passion is learning new technologies and traveling the world. Victor has flown over a million miles and plans to continue his eternal journey of exploration.
 Akshay Singhal is a Sr. Technical Account Manager at Amazon Web Services, based in San Francisco Bay Area, supporting enterprise support customers focusing on the security ISV segment. He provides technical guidance for customers to implement AWS solutions, with expertise spanning serverless architectures and cost-optimization. Outside of work, Akshay enjoys traveling, Formula 1, making short movies, and exploring new cuisines.
Akshay Singhal is a Sr. Technical Account Manager at Amazon Web Services, based in San Francisco Bay Area, supporting enterprise support customers focusing on the security ISV segment. He provides technical guidance for customers to implement AWS solutions, with expertise spanning serverless architectures and cost-optimization. Outside of work, Akshay enjoys traveling, Formula 1, making short movies, and exploring new cuisines.
Author: Thorben Sanktjohanser