

Import a fine-tuned Meta Llama 3 model for SQL query generation on Amazon Bedrock
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading artificial intelligence (AI) companies like AI21 Labs, Anthropic, Cohere, Meta, Mistral AI, Stability AI, and Amazon through a single API… Hosting large models involves complexity…
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading artificial intelligence (AI) companies like AI21 Labs, Anthropic, Cohere, Meta, Mistral AI, Stability AI, and Amazon through a single API. Amazon Bedrock also provides a broad set of capabilities needed to build generative AI applications with security, privacy, and responsible AI practices.
Some FMs are publicly available, which allows for customization tailored to specific use cases and domains. However, deploying customized FMs to support generative AI applications in a secure and scalable manner isn’t a trivial task. Hosting large models involves complexity around the selection of instance type and deployment parameters. To address this challenge, AWS recently announced the preview of Amazon Bedrock Custom Model Import, a feature that you can use to import customized models created in other environments—such as Amazon SageMaker, Amazon Elastic Compute Cloud (Amazon EC2) instances, and on premises—into Amazon Bedrock. This feature abstracts the complexity of the deployment process through simple APIs for model deployment and invocation. Currently, Custom Model Import supports importing custom weights for selected model architectures (Meta Llama 2 and Llama 3, Flan, and Mistral) and precisions (FP32, FP16, and BF16), and serving the models on demand and with provisioned throughput.
Customizing FMs can unlock significant value by tailoring their capabilities to specific domains or tasks. This is the first in a series of posts about model customization scenarios that can be imported into Amazon Bedrock to simplify the process of building scalable and secure generative AI applications. By demonstrating the process of deploying fine-tuned models, we aim to empower data scientists, ML engineers, and application developers to harness the full potential of FMs while addressing unique application requirements.
In this post, we demonstrate the process of fine-tuning Meta Llama 3 8B on SageMaker to specialize it in the generation of SQL queries (text-to-SQL). Meta Llama 3 8B is a relatively small model that offers a balance between performance and resource efficiency. AWS customers have explored fine-tuning Meta Llama 3 8B for the generation of SQL queries—especially when using non-standard SQL dialects—and have requested methods to import their customized models into Amazon Bedrock to benefit from the managed infrastructure and security that Amazon Bedrock provides when serving those models.
Solution overview
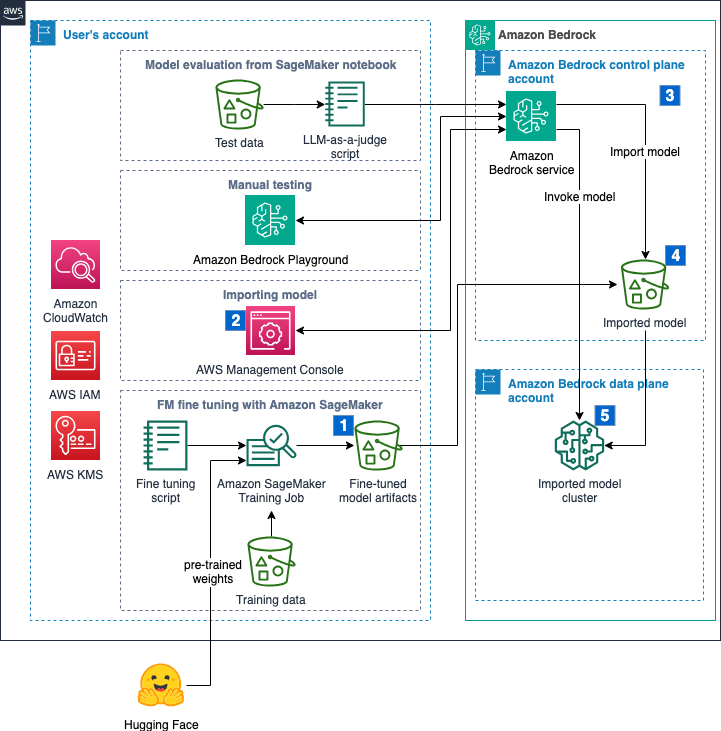
We walk through the steps of fine-tuning an FM with using SageMaker, and importing and evaluating the fine-tuned FM for SQL query generation using Amazon Bedrock. The complete flow is shown in the following figure and it covers the following steps:
- The user invokes a SageMaker training job to fine-tune the model using QLoRA and store the weights in an Amazon Simple Storage Service (Amazon S3) bucket in the user’s account.
- When the fine-tuning job is complete, the user runs the model import job using the Amazon Bedrock console. This step will run Steps 3–5 automatically.
- Amazon Bedrock service starts an import job in an AWS operated deployment account.
- Model artifacts are copied from the user’s account into an AWS managed S3 bucket.
- When the import job is complete, the fine-tuned model will be made available to be invoked.

All data remains within the selected AWS Region, the model artifacts are imported into the AWS operated deployment account using a VPC endpoint, and you can encrypt your model data with your own Amazon Key Management Service (AWS KMS) keys. The scripts for fine-tuning and evaluation are available on the GitHub repository.
A copy of your model artifacts is stored in an AWS operated deployment account. This copy will remain until the custom model is deleted. Deleting artifacts in the user’s account won’t delete the model or the artifacts in the AWS operated account. If different versions of a model are imported into Amazon Bedrock, each version will be managed as an independent project with its own set of artifacts. You can apply tags to models and import jobs to keep track of different projects and versions.
Meta Llama3 8B is a gated model on Hugging Face, which means that users must be granted access before they’re allowed to download and customize the model. Sign in to your Hugging Face account, read the Meta Llama 3 Acceptable Use Policy, and submit your contact information to be granted access. This process might take a couple of hours.
We use the sql-create-context dataset available on Hugging Face for fine-tuning. The dataset contains 78,577 tuples of context (table schema), question (query expressed in natural language), and answer (SQL query). Refer to the licensing information regarding this dataset before proceeding further.
We use Amazon SageMaker Studio to create a remote fine-tuning job, which will run as a SageMaker training job. SageMaker Studio is a single web-based interface for end-to-end machine learning (ML) development. If you need help configuring your SageMaker Studio domain and your JupyterLab environment, see Launch Amazon SageMaker Studio. The training job will use QLoRA and the PyTorch FullyShardedDataParallel API (FSDP) to fine-tune the Meta Llama 3 model. QLoRA quantizes a pretrained language model to 4 bits and attaches smaller low-rank adapters (LoRA), which are fine-tuned with our training data. PyTorch FSDP is a parallelism technique that shards the model across GPUs for efficient training. See the following notebook for the complete code sample.
Data preparation
In the data preparation stage, we use the following prompt template to insert specific instructions for interpreting the context and fulfilling the request, and store the modified training dataset as JSON files that are uploaded to Amazon S3:
Fine-tune Meta Llama 3 8B model
Refer to the run_fsdp_qlora.py file defined in the notebook for a full description of the fine-tuning script. The following snippets describe the configuration of the QLoRA job:
The trainer class is based on Supervised Fine-tuning Trainer (SFT Trainer) from Hugging Face, which is an API to create your SFT models and train them with a few lines of code:
Once the adapter is trained, it is merged with the original model before persisting the weights. Custom Model Import does not support LoRA adapters at the moment.
For this use case, we use an ml.g5.12xlarge instance, which has four NVIDIA A10 accelerators. The key configurations are as follows:
In our testing, the training job completed two epochs in approximately 2.5 hours on a single ml.g5.12xlarge instance, which incurred approximately $18 for training cost. After training is complete, model weights in the Hugging Face safetensors format, the tokenizer, and the configuration file will be uploaded to the S3 bucket defined in the training script. This path should be stored to be used as the base directory for the import job in the next section.
The configuration file config.json will inform Amazon Bedrock how to load the weights from the safetensors files. Some parameters to keep in mind are the model_type, which must be one of the types currently supported by Amazon Bedrock, max_position_embeddings, which sets the maximum length of input sequence that the model can handle, the model dimensions (hidden_size, intermediate_size, num_hidden_layers, and num_attention_heads), and rotary position embedding (RoPE) parameters, which describe the encoding of position information. See the following configuration:
Import the fine-tuned model into Amazon Bedrock
To import the fine-tuned Meta Llama 3 model into Amazon Bedrock, compete the following steps:
- On the Amazon Bedrock console, choose Imported models on the navigation pane.

- Choose Import model.


- For Model name, enter
llama-3-8b-text-to-sql. - For Model import settings, enter the Amazon S3 location from the previous steps.
- Choose Import model.
 The model import job should take 15–18 minutes to complete.
The model import job should take 15–18 minutes to complete. - When it’s done, choose Models to see your model.
- Copy the model Amazon Resource Name (ARN) so you can invoke the model with the AWS SDK in the next section.

 The model import job should take 15–18 minutes to complete.
The model import job should take 15–18 minutes to complete.
Evaluate SQL queries generated by the fine-tuned model
In this section, we provide two examples to evaluate the SQL queries generated by the fine-tuned model: one using the Amazon Bedrock Text Playground and one using a large language model (LLM) as a judge.
Using the Amazon Bedrock Text Playground
You can test the model using the Amazon Bedrock Text Playground. For optimal results, use the same prompt template used to preprocess your training data:
The following animation shows the results.

Using LLM as a judge
On the same example notebook, we used the Amazon Bedrock InvokeModel API to call our imported model on demand to generate SQL queries for records in our test dataset. We use the same prompt template used with the training data in the fine-tuning step. The imported model will only support parameters that were supported by the base model (max_tokens, top_p, and temperature). Imported models don’t support penalty terms (repetition_penalty or length_penalty) or the use of token sampling instead of greedy decoding (do_sample). See the following code:
After we generate model predictions, we use a different (more powerful) model to act as a judge and evaluate our fine-tuned model responses. For this example, we use the Anthropic Claude 3 Sonnet LLM on Amazon Bedrock to measure the similarity between the desired answer and the predicted answer using the following prompt:
The predicted score based on our holdout split of the dataset was 96.65%, which is excellent for a small model tuned to a specific task.
Clean up
The model will spin down to zero after a period of no activity and your cost will stop accruing. However, we recommend deleting the imported model using the Amazon Bedrock console. Remember to also delete model artifacts from your S3 bucket when the fine-tuned model is no longer needed to prevent incurring costs.
Conclusion
This post presented an overview of the process of fine-tuning a small model using SageMaker to help generate more accurate SQL queries based on questions asked in natural language and then importing the fine-tuned model into Amazon Bedrock using the Custom Model Import feature. After we imported the model, it was made available on demand through the Amazon Bedrock Playground and the InvokeModel API, which was used to evaluate the performance of the fine-tuned model against a holdout dataset using an LLM as a judge.
The following are recommended best practices that may be helpful when using fine-tuned FMs for code generation tasks:
- Select a dataset that is relevant and diverse enough for your code generation task
- Monitor the training job and PEFT parameters to prevent overfitting and catastrophic forgetting
- Preprocess training data with a consistent instruction template
- Store model weights using safetensors for fast loading
- Invoke the model using the same instruction template used in fine-tuning, using only inference parameters that are supported by the base model and the Custom Model Import feature in Amazon Bedrock
Explore the Amazon Bedrock Custom Model Import feature as a way to deploy FMs fine-tuned for code generation tasks in a secure and scalable manner. Visit our GitHub repository to explore samples prepared for fine-tuning and importing models from various families.
About the Authors
 Evandro Franco is a Sr. AI/ML Specialist Solutions Architect working on Amazon Web Services. He helps AWS customers overcome business challenges related to AI/ML on top of AWS. He has more than 18 years working with technology, from software development, infrastructure, serverless, to machine learning.
Evandro Franco is a Sr. AI/ML Specialist Solutions Architect working on Amazon Web Services. He helps AWS customers overcome business challenges related to AI/ML on top of AWS. He has more than 18 years working with technology, from software development, infrastructure, serverless, to machine learning.
 Felipe Lopez is a Senior AI/ML Specialist Solutions Architect at AWS. Prior to joining AWS, Felipe worked with GE Digital and SLB, where he focused on modeling and optimization products for industrial applications.
Felipe Lopez is a Senior AI/ML Specialist Solutions Architect at AWS. Prior to joining AWS, Felipe worked with GE Digital and SLB, where he focused on modeling and optimization products for industrial applications.
 Jay Pillai is a Principal Solution Architect at Amazon Web Services. In this role, he functions as the Global Generative AI Lead Architect and also the Lead Architect for Supply Chain Solutions with AABG. As an Information Technology Leader, Jay specializes in artificial intelligence, data integration, business intelligence, and user interface domains. He has 23 years of extensive experience working with several clients across supply chain, legal technologies, real estate, financial services, insurance, payments, and market research business domains.
Jay Pillai is a Principal Solution Architect at Amazon Web Services. In this role, he functions as the Global Generative AI Lead Architect and also the Lead Architect for Supply Chain Solutions with AABG. As an Information Technology Leader, Jay specializes in artificial intelligence, data integration, business intelligence, and user interface domains. He has 23 years of extensive experience working with several clients across supply chain, legal technologies, real estate, financial services, insurance, payments, and market research business domains.
 Rupinder Grewal is a Senior AI/ML Specialist Solutions Architect with AWS. He currently focuses on the serving of models and MLOps on Amazon SageMaker. Prior to this role, he worked as a Machine Learning Engineer building and hosting models. Outside of work, he enjoys playing tennis and biking on mountain trails.
Rupinder Grewal is a Senior AI/ML Specialist Solutions Architect with AWS. He currently focuses on the serving of models and MLOps on Amazon SageMaker. Prior to this role, he worked as a Machine Learning Engineer building and hosting models. Outside of work, he enjoys playing tennis and biking on mountain trails.
 Sandeep Singh is a Senior Generative AI Data Scientist at Amazon Web Services, helping businesses innovate with generative AI. He specializes in Generative AI, Artificial Intelligence, Machine Learning, and System Design. He is passionate about developing state-of-the-art AI/ML-powered solutions to solve complex business problems for diverse industries, optimizing efficiency and scalability.
Sandeep Singh is a Senior Generative AI Data Scientist at Amazon Web Services, helping businesses innovate with generative AI. He specializes in Generative AI, Artificial Intelligence, Machine Learning, and System Design. He is passionate about developing state-of-the-art AI/ML-powered solutions to solve complex business problems for diverse industries, optimizing efficiency and scalability.
 Ragha Prasad is a Principal Engineer and a founding member of Amazon Bedrock, where he has had the privilege to listen to customer needs first-hand and understands what it takes to build and launch scalable and secure Gen AI products. Prior to Bedrock, he worked on numerous products in Amazon, ranging from devices to Ads to Robotics.
Ragha Prasad is a Principal Engineer and a founding member of Amazon Bedrock, where he has had the privilege to listen to customer needs first-hand and understands what it takes to build and launch scalable and secure Gen AI products. Prior to Bedrock, he worked on numerous products in Amazon, ranging from devices to Ads to Robotics.
Author: Evandro Franco