

Improve RAG accuracy with fine-tuned embedding models on Amazon SageMaker
Retrieval Augmented Generation (RAG) is a popular paradigm that provides additional knowledge to large language models (LLMs) from an external source of data that wasn’t present in their training corpus… Challenges in RAG accuracy Pre-trained embedding models are typically trained on large,…
Retrieval Augmented Generation (RAG) is a popular paradigm that provides additional knowledge to large language models (LLMs) from an external source of data that wasn’t present in their training corpus.
RAG provides additional knowledge to the LLM through its input prompt space and its architecture typically consists of the following components:
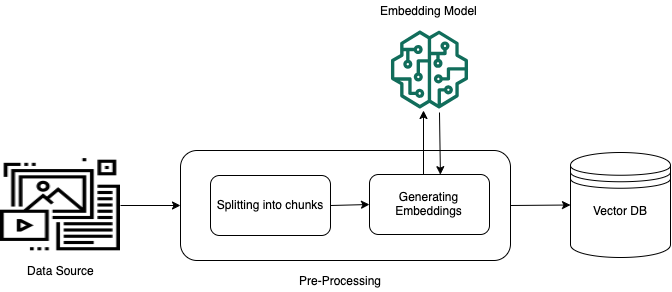
- Indexing: Prepare a corpus of unstructured text, parse and chunk it, and then, embed each chunk and store it in a vector database.

- Retrieval: Retrieve context relevant to answering a question from the vector database using vector similarity. Use prompt engineering to provide this additional context to the LLM along with the original question. The LLM will then use the original question and the context from the vector database to generate an answer based on data that wasn’t part of its training corpus.



Challenges in RAG accuracy
Pre-trained embedding models are typically trained on large, general-purpose datasets like Wikipedia or web-crawl data. While these models capture a broad range of semantic relationships and can generalize well across various tasks, they might struggle to accurately represent domain-specific concepts and nuances. This limitation can lead to suboptimal performance when using these pre-trained embeddings for specialized tasks or domains, such as legal, medical, or technical domains. Furthermore, pre-trained embeddings might not effectively capture the contextual relationships and nuances that are specific to a particular task or domain. For example, in the legal domain, the same term can have different meanings or implications depending on the context, and these nuances might not be adequately represented in a general-purpose embedding model.
To address the limitations of pre-trained embeddings and improve the accuracy of RAG systems for specific domains or tasks, it’s essential to fine tune the embedding model on domain-specific data. By fine tuning the model on data that is representative of the target domain or task, the model can learn to capture the relevant semantics, jargon, and contextual relationships that are crucial for that domain.
Domain-specific embeddings can significantly improve the quality of vector representations, leading to more accurate retrieval of relevant context from the vector database. This, in turn, enhances the performance of the RAG system in terms of generating more accurate and relevant responses.
This post demonstrates how to use Amazon SageMaker to fine tune a Sentence Transformer embedding model and deploy it with an Amazon SageMaker Endpoint. The code from this post and more examples are available in the GitHub repo. For more information about fine tuning Sentence Transformer, see Sentence Transformer training overview.
Fine tuning embedding models using SageMaker
SageMaker is a fully managed machine learning service that simplifies the entire machine learning workflow, from data preparation and model training to deployment and monitoring. It provides a seamless and integrated environment that abstracts away the complexities of infrastructure management, allowing developers and data scientists to focus solely on building and iterating their machine learning models.
One of the key strengths of SageMaker is its native support for popular open source frameworks such as TensorFlow, PyTorch, and Hugging Face transformers. This integration enables seamless model training and deployment using these frameworks, their powerful capabilities and extensive ecosystem of libraries and tools.
SageMaker also offers a range of built-in algorithms for common use cases like computer vision, natural language processing, and tabular data, making it easy to get started with pre-built models for various tasks. SageMaker also supports distributed training and hyperparameter tuning, allowing for efficient and scalable model training.
Prerequisites
For this walkthrough, you should have the following prerequisites:
- An AWS account set up.
- An Amazon SageMaker JupyterLab configured with the
python3kernel
To quickly set up SageMaker Studio, you can create a domain for a single user and launch your JupyterLab. - An AWS Identity and Access Management (IAM) role for the Sagemaker notebook with sufficient permissions to write into an Amazon Simple Storage Service (Amazon S3) bucket, and create a Sagemaker endpoint. If you have administrator access to the account, no additional action is required.
Steps to fine tune embedding models on Amazon SageMaker
In the following sections, we use a SageMaker JupyterLab to walk through the steps of data preparation, creating a training script, training the model, and deploying it as a SageMaker endpoint.
We will fine tune the embedding model sentence-transformers, all-MiniLM-L6-v2, which is an open source Sentence Transformers model fine tuned on a 1B sentence pairs dataset. It maps sentences and paragraphs to a 384-dimensional dense vector space and can be used for tasks like clustering or semantic search. To fine tune it, we will use the Amazon Bedrock FAQs, a dataset of question and answer pairs, using the MultipleNegativesRankingLoss function.
In Losses, you can find the different loss functions that can be used to fine-tune embedding models on training data. The choice of loss function plays a critical role when fine tuning the model. It determines how well our embedding model will work for the specific downstream task.
The MultipleNegativesRankingLoss function is recommended when you only have positive pairs in your training data, for example, only pairs of similar texts like pairs of paraphrases, pairs of duplicate questions, pairs of query and response, or pairs of (source_language and target_language).
In our case, considering that we’re using Amazon Bedrock FAQs as training data, which consists of pairs of questions and answers, the MultipleNegativesRankingLoss function could be a good fit.
The following code snippet demonstrates how to load a training dataset from a JSON file, prepares the data for training, and then fine tunes the pre-trained model. After fine tuning, the updated model is saved.
The EPOCHS variable determines the number of times the model will iterate over the entire training dataset during the fine-tuning process. A higher number of epochs typically leads to better convergence and potentially improved performance but might also increase the risk of overfitting if not properly regularized.
In this example, we have a small training set consisting of only 100 records. As a result, we’re using a high value for the EPOCHS parameter. Typically, in real-world scenarios, you would have a much larger training set. In such cases, the EPOCHS value should be a single- or two-digit number to avoid overfitting the model to the training data.
To deploy and serve the fine-tuned embedding model for inference, we create an inference.py Python script that serves as the entry point. This script implements two essential functions: model_fn and predict_fn, as required by SageMaker for deploying and using machine learning models.
The model_fn function is responsible for loading the fine-tuned embedding model and the associated tokenizer. The predict_fn function takes input sentences, tokenizes them using the loaded tokenizer, and computes their sentence embeddings using the fine-tuned model. To obtain a single vector representation for each sentence, it performs mean pooling over the token embeddings followed by normalization of the resulting embedding. Finally, predict_fn returns the normalized embeddings as a list, which can be further processed or stored as required.
After creating the inference.py script, we package it together with the fine-tuned embedding model into a single model.tar.gz file. This compressed file can then be uploaded to an S3 bucket, making it accessible for deployment as a SageMaker endpoint.
Finally, we can deploy our fine-tuned model in a SageMaker endpoint.
After the deployment is completed, you can find the deployed SageMaker endpoint in the AWS Management Console for SageMaker by choosing the Inference from the navigation pane, and then choosing Endpoints.

You have multiple options to invoke you endpoint. For example, in your SageMaker JupyterLab, you can invoke it with the following code snippet:
It returns the vector containing the embedding of the inputs key:
To illustrate the impact of fine tuning, we can compare the cosine similarity scores between two semantically related sentences using both the original pre-trained model and the fine-tuned model. A higher cosine similarity score indicates that the two sentences are more semantically similar, because their embeddings are closer in the vector space.
Let’s consider the following pair of sentences:
- What are agents, and how can they be used?
- Agents for Amazon Bedrock are fully managed capabilities that automatically break down tasks, create an orchestration plan, securely connect to company data through APIs, and generate accurate responses for complex tasks like automating inventory management or processing insurance claims.
These sentences are related to the concept of agents in the context of Amazon Bedrock, although with different levels of detail. By generating embeddings for these sentences using both models and calculating their cosine similarity, we can evaluate how well each model captures the semantic relationship between them.
The original pre-trained model returns a similarity score of only 0.54.

The fine-tuned model returns a similarity score of 0.87.

We can observe how the fine-tuned model was able to identify a much higher semantic similarity between the concepts of agents and Agents for Amazon Bedrock when compared to the pre-trained model. This improvement is attributed to the fine-tuning process, which exposed the model to the domain-specific language and concepts present in the Amazon Bedrock FAQs data, enabling it to better capture the relationship between these terms.
Clean up
To avoid future charges in your account, delete the resources you created in this walkthrough. The SageMaker endpoint and the SageMaker JupyterLab instance will incur charges as long as the instances are active, so when you’re done delete the endpoint and resources that you created while running the walkthrough.
Conclusion
In this blog post, we have explored the importance of fine tuning embedding models to improve the accuracy of RAG systems in specific domains or tasks. We discussed the limitations of pre-trained embeddings, which are trained on general-purpose datasets and might not capture the nuances and domain-specific semantics required for specialized domains or tasks.
We highlighted the need for domain-specific embeddings, which can be obtained by fine tuning the embedding model on data representative of the target domain or task. This process allows the model to capture the relevant semantics, jargon, and contextual relationships that are crucial for accurate vector representations and, consequently, better retrieval performance in RAG systems.
We then demonstrated how to fine tune embedding models on Amazon SageMaker using the popular Sentence Transformers library.
By fine tuning embeddings on domain-specific data using SageMaker, you can unlock the full potential of RAG systems, enabling more accurate and relevant responses tailored to your specific domain or task. This approach can be particularly valuable in domains like legal, medical, or technical fields where capturing domain-specific nuances is crucial for generating high-quality and trustworthy outputs.
This and more examples are available in the GitHub repo. Try it out today using the Set up for single users (Quick setup) on Amazon SageMaker and let us know what you think in the comments.
About the Authors
 Ennio Emanuele Pastore is a Senior Architect on the AWS GenAI Labs team. He is an enthusiast of everything related to new technologies that have a positive impact on businesses and general livelihood. He helps organizations in achieving specific business outcomes by using data and AI and accelerating their AWS Cloud adoption journey.
Ennio Emanuele Pastore is a Senior Architect on the AWS GenAI Labs team. He is an enthusiast of everything related to new technologies that have a positive impact on businesses and general livelihood. He helps organizations in achieving specific business outcomes by using data and AI and accelerating their AWS Cloud adoption journey.
Author: Ennio Pastore