

Improved ML model deployment using Amazon SageMaker Inference Recommender
Amazon SageMaker Inference Recommender is a capability of Amazon SageMaker that reduces the time required to get ML models in production by automating load testing and model tuning across SageMaker ML instances… In this post, we highlight some of the recent updates to Inference Recommender: …
Each machine learning (ML) system has a unique service level agreement (SLA) requirement with respect to latency, throughput, and cost metrics. With advancements in hardware design, a wide range of CPU- and GPU-based infrastructures are available to help you speed up inference performance. Also, you can build these ML systems with a combination of ML models, tasks, frameworks, libraries, tools, and inference engines, making it important to evaluate the ML system performance for the best possible deployment configurations. You need recommendations on finding the most cost-effective ML serving infrastructure and the right combination of software configuration to achieve the best price-performance to scale these applications.
Amazon SageMaker Inference Recommender is a capability of Amazon SageMaker that reduces the time required to get ML models in production by automating load testing and model tuning across SageMaker ML instances. In this post, we highlight some of the recent updates to Inference Recommender:
- SageMaker Python SDK support for running Inference Recommender
- Inference Recommender usability improvements
- New APIs that provide flexibility in running Inference Recommender
- Deeper integration with Amazon CloudWatch for logging and metrics
Credit card fraud detection use case
Any fraudulent activity that is not detected and mitigated immediately can cause significant financial loss. Particularly, credit card payment fraud transactions need to be identified right away to protect the individual’s and company’s financial health. In this post, we discuss a credit card fraud detection use case, and learn how to use Inference Recommender to find the optimal inference instance type and ML system configurations that can detect fraudulent credit card transactions in milliseconds.
We demonstrate how to set up Inference Recommender jobs for a credit card fraud detection use case. We train an XGBoost model for a classification task on a credit card fraud dataset. We use Inference Recommender with a custom load to meet inference SLA requirements to satisfy peak concurrency of 30,000 transactions per minute while serving predictions results in less than 100 milliseconds. Based on Inference Recommender’s instance type recommendations, we can find the right real-time serving ML instances that yield the right price-performance for this use case. Finally, we deploy the model to a SageMaker real-time endpoint to get prediction results.
The following table summarizes the details of our use case.
| Model Framework | XGBoost |
| Model Size | 10 MB |
| End-to-End Latency | 100 milliseconds |
| Invocations per Second | 500 (30,000 per minute) |
| ML Task | Binary Classification |
| Input Payload | 10 KB |
We use a synthetically created credit card fraud dataset. The dataset contains 28 numerical features, time of the transaction, transaction amount, and class target variables. The class column corresponds to whether or not a transaction is fraudulent. The majority of data is non-fraudulent (284,315 samples), with only 492 samples corresponding to fraudulent examples. In the data, Class is the target classification variable (fraudulent vs. non-fraudulent) in the first column, followed by other variables.
In the following sections, we show how to use Inference Recommender to get ML hosting instance type recommendations and find optimal model configurations to achieve better price-performance for your inference application.
Which ML instance type and configurations should you select?
With Inference Recommender, you can run two types of jobs: default and advanced.
The default Instance Recommender job runs a set of load tests to recommended the right ML instance types for any ML use case. SageMaker real-time deployment supports a wide range of ML instances to host and serve the credit card fraud detection XGBoost model. The default job can run a load test on a selection of instances that you provide in the job configuration. If you have an existing endpoint for this use case, you can run this job to find the cost-optimized performant instance type. Inference Recommender will compile and optimize the model for a specific hardware of inference endpoint instance type using Amazon SageMaker Neo. It’s important to note that not all compilation results in improved performance. Inference Recommender will report compilation details when the following conditions are met:
- Successful compilation of the model using Neo. There could be issues in the compilation process such as invalid payload, data type, or more. In this case, compilation information is not available.
- Successful inference using the compiled model that shows performance improvement, which appears in the inference job response.
An advanced job is a custom load test job that allows you to perform extensive benchmarks based on your ML application SLA requirements, such as latency, concurrency, and traffic pattern. You can configure a custom traffic pattern to simulate credit card transactions. Additionally, you can define the end-to-end model latency to predict if a transaction is fraudulent and define the maximum concurrent transactions to the model for prediction. Inference Recommender uses this information to run a performance benchmark load test. The latency, concurrency, and cost metrics from the advanced job help you make informed decisions about the ML serving infrastructure for mission-critical applications.
Solution overview
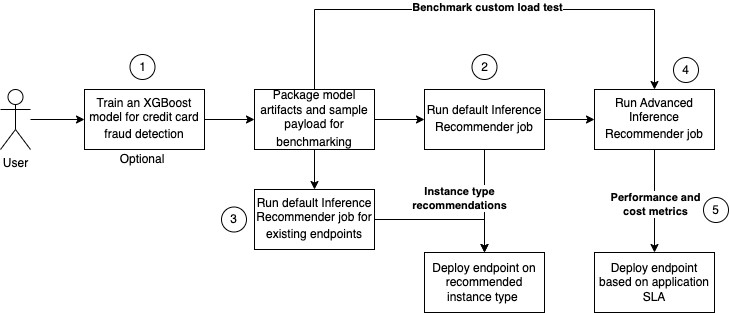
The following diagram shows the solution architecture for training an XGBoost model on the credit card fraud dataset, running a default job for instance type recommendation, and performing load testing to decide the optimal inference configuration for the best price-performance.

The diagram shows the following steps:
- Train an XGBoost model to classify credit card transactions as fraudulent or legit. Deploy the trained model to a SageMaker real-time endpoint. Package the model artifacts and sample payload (.tar.gz format), and upload them to Amazon Simple Storage Service (Amazon S3) so Inference Recommender can use these when the job is run. Note that the training step in this post is optional.
- Configure and run a default Inference Recommender job on a list of supported instance types to find the right ML instance type that gives the best price-performance for this use case.
- Optionally, run a default Inference Recommender job on an existing endpoint.
- Configure and run an advanced Inference Recommender job to perform a custom load test to simulate user interactions with the credit card fraud detection application. This helps you find the right configurations to satisfy latency, concurrency, and cost for this use case.
- Analyze the default and advanced Inference Recommender job results, which include ML instance type recommendation latency, performance, and cost metrics.
A complete example is available in our GitHub notebook.
Prerequisites
To use Inference Recommender, make sure to meet the prerequisites.
Python SDK support for Inference Recommender
We recently released Python SDK support for Inference Recommender. You can now run default and advanced jobs using a single function: right_size. Based on the parameters of the function call, Inference Recommender infers if it should run default or advanced jobs. This greatly simplifies the use of Inference Recommender using the Python SDK. To run the Inference Recommender job, complete the following steps:
- Create a SageMaker model by specifying the framework, version, and image scope:
- Optionally, register the model in the SageMaker model registry. Note that parameters such as domain and task during model package creation are also optional parameters in the recent release.
- Run the
right_sizefunction on the supported ML inference instance types using the following configuration. Because XGBoost is a memory-intensive algorithm, we provide ml.m5 type instances to get instance type recommendations. You can call theright_sizefunction on the model registry object as well. - Define additional parameters to the
right_sizefunction to run an advanced job and custom load test on the model:- Configure the traffic pattern using the
phasesparameter. In the first phase, we start the load test with two initial users and create two new users for every minute for 2 minutes. In the following phase, we start the load test with six initial users and create two new users for every minute for 2 minutes. Stopping conditions for the load tests are p95 end-to-end latency of 100 milliseconds and concurrency to support 30,000 transactions per minute or 500 transactions per second. - We tune the endpoint against the environment variable
OMP_NUM_THREADSwith values[3,4,5]and we aim to limit the latency requirement to 100 milliseconds and achieve max concurrency of 30,000 invocations per minute. The goal is to find which value forOMP_NUM_THREADSprovides the best performance.
- Configure the traffic pattern using the
Run Inference Recommender jobs using the Boto3 API
You can use the Boto3 API to launch Inference Recommender default and advanced jobs. You need to use the Boto3 API (create_inference_recommendations_job) to run Inference Recommender jobs on an existing endpoint. Inference Recommender infers the framework and version from the existing SageMaker real-time endpoint. The Python SDK doesn’t support running Inference Recommender jobs on existing endpoints.
The following code snippet shows how to create a default job:
Later in this post, we discuss the parameters needed to configure an advanced job.
Configure a traffic pattern using the TrafficPattern parameter. In the first phase, we start a load test with two initial users (InitialNumberOfUsers) and create two new users (SpawnRate) for every minute for 2 minutes (DurationInSeconds). In the following phase, we start the load test with six initial users and create two new users for every minute for 2 minutes. Stopping conditions (StoppingConditions) for the load tests are p95 end-to-end latency (ModelLatencyThresholds) of 100 milliseconds (ValueInMilliseconds) and concurrency to support 30,000 transactions per minute or 500 transactions per second (MaxInvocations). See the following code:
Inference Recommender job results and metrics
The results of the default Inference Recommender job contain a list of endpoint configuration recommendations, including instance type, instance count, and environment variables. The results contain configurations for SAGEMAKER_MODEL_SERVER_WORKERS and OMP_NUM_THREADS associated with the latency, concurrency, and throughput metrics. OMP_NUM_THREADS is the model server tunable environment parameter. As shown in the details in the following table, with an ml.m5.4xlarge instance with SAGEMAKER_MODEL_SERVER_WORKERS=3 and OMP_NUM_THREADS=3, we got a throughput of 32,628 invocations per minute and model latency under 10 milliseconds. ml.m5.4xlarge had 100% improvement in latency, an approximate 115% increase in concurrency compared to the ml.m5.xlarge instance configuration. Also, it was 66% more cost-effective compared to the ml.m5.12xlarge instance configurations while achieving comparable latency and throughput.
| Instance Type | Initial Instance Count | OMP_NUM_THREADS | Cost Per Hour | Max Invocations | Model Latency | CPU Utilization | Memory Utilization | SageMaker Model Server Workers |
| ml.m5.xlarge | 1 | 2 | 0.23 | 15189 | 18 | 108.864 | 1.62012 | 1 |
| ml.m5.4xlarge | 1 | 3 | 0.922 | 32628 | 9 | 220.57001 | 0.69791 | 3 |
| ml.m5.large | 1 | 2 | 0.115 | 13793 | 19 | 106.34 | 3.24398 | 1 |
| ml.m5.12xlarge | 1 | 4 | 2.765 | 32016 | 4 | 215.32401 | 0.44658 | 7 |
| ml.m5.2xlarge | 1 | 2 | 0.461 | 32427 | 13 | 248.673 | 1.43109 | 3 |
We have included CloudWatch helper functions in the notebook. You can use the functions to get detailed charts of your endpoints during the load test. The charts have details on invocation metrics like invocations, model latency, overhead latency, and more, and instance metrics such as CPUUtilization and MemoryUtilization. The following example shows the CloudWatch metrics for our ml.m5.4xlarge model configuration.

You can visualize Inference Recommender job results in Amazon SageMaker Studio by choosing Inference Recommender under Deployments in the navigation pane. With a deployment goal for this use case (high latency, high throughput, default cost), the default Inference Recommender job recommended an ml.m5.4xlarge instance because it provided the best latency performance and throughput to support a maximum 34,600 invocations per minute (576 TPS). You can use these metrics to analyze and find the best configurations that satisfy latency, concurrency, and cost requirements of your ML application.

We recently introduced ListInferenceRecommendationsJobSteps, which allows you to analyze subtasks in an Inference Recommender job. The following code snippet shows how to use the list_inference_recommendations_job_steps Boto3 API to get the list of subtasks. This can help with debugging Inference Recommender job failures at the step level. This functionality is not supported in the Python SDK yet.
The following code shows the response:
Run an advanced Inference Recommender job
Next, we run an advanced Inference Recommender job to find optimal configurations such as SAGEMAKER_MODEL_SERVER_WORKERS and OMP_NUM_THREADS on an ml.m5.4xlarge instance type. We set the hyperparameters of the advanced job to run a load test on different combinations:
You can view the advanced Inference Recommender job results on the Studio console, as shown in the following screenshot.

Using the Boto3 API or CLI commands, you can access all the metrics from the advanced Inference Recommender job results. InitialInstanceCount is the number of instances that you should provision in the endpoint to meet ModelLatencyThresholds and MaxInvocations mentioned in StoppingConditions. The following table summarizes our results.
| Instance Type | Initial Instance Count | OMP_NUM_THREADS | Cost Per Hour | Max Invocations | Model Latency | CPU Utilization | Memory Utilization |
| ml.m5.2xlarge | 2 | 3 | 0.922 | 39688 | 6 | 86.732803 | 3.04769 |
| ml.m5.2xlarge | 2 | 4 | 0.922 | 42604 | 6 | 177.164993 | 3.05089 |
| ml.m5.2xlarge | 2 | 5 | 0.922 | 39268 | 6 | 125.402 | 3.08665 |
| ml.m5.4xlarge | 2 | 3 | 1.844 | 38174 | 4 | 102.546997 | 2.68003 |
| ml.m5.4xlarge | 2 | 4 | 1.844 | 39452 | 4 | 141.826004 | 2.68136 |
| ml.m5.4xlarge | 2 | 5 | 1.844 | 40472 | 4 | 107.825996 | 2.70936 |
Clean up
Follow the instructions in the notebook to delete all the resources created as part of this post to avoid incurring additional charges.
Summary
Finding the right ML serving infrastructure, including instance type, model configurations, and auto scaling polices, can be tedious. This post showed how you can use the Inference Recommender Python SDK and Boto3 APIs to launch default and advanced jobs to find the optimal inference infrastructure and configurations. We also discussed the new improvements to Inference Recommender, including Python SDK support and usability improvements. Check out our GitHub repository to get started.
About the Authors
 Shiva Raaj Kotini works as a Principal Product Manager in the AWS SageMaker inference product portfolio. He focuses on model deployment, performance tuning, and optimization in SageMaker for inference.
Shiva Raaj Kotini works as a Principal Product Manager in the AWS SageMaker inference product portfolio. He focuses on model deployment, performance tuning, and optimization in SageMaker for inference.
 John Barboza is a Software Engineer at AWS. He has extensive experience working on distributed systems. His current focus is on improving the SageMaker inference experience. In his spare time, he enjoys cooking and biking.
John Barboza is a Software Engineer at AWS. He has extensive experience working on distributed systems. His current focus is on improving the SageMaker inference experience. In his spare time, he enjoys cooking and biking.
 Mohan Gandhi is a Senior Software Engineer at AWS. He has been with AWS for the last 10 years and has worked on various AWS services like Amazon EMR, Amazon EFA, and Amazon RDS. Currently, he is focused on improving the SageMaker inference experience. In his spare time, he enjoys hiking and marathons.
Mohan Gandhi is a Senior Software Engineer at AWS. He has been with AWS for the last 10 years and has worked on various AWS services like Amazon EMR, Amazon EFA, and Amazon RDS. Currently, he is focused on improving the SageMaker inference experience. In his spare time, he enjoys hiking and marathons.
 Ram Vegiraju is an ML Architect with the SageMaker service team. He focuses on helping customers build and optimize their AI/ML solutions on Amazon SageMaker. In his spare time, he loves traveling and writing.
Ram Vegiraju is an ML Architect with the SageMaker service team. He focuses on helping customers build and optimize their AI/ML solutions on Amazon SageMaker. In his spare time, he loves traveling and writing.
 Vikram Elango is an Sr. AIML Specialist Solutions Architect at AWS, based in Virginia USA. He is currently focused on Generative AI, LLMs, prompt engineering, large model inference optimization and scaling ML across enterprises. Vikram helps financial and insurance industry customers with design, thought leadership to build and deploy machine learning applications at scale. In his spare time, he enjoys traveling, hiking, cooking and camping with his family.
Vikram Elango is an Sr. AIML Specialist Solutions Architect at AWS, based in Virginia USA. He is currently focused on Generative AI, LLMs, prompt engineering, large model inference optimization and scaling ML across enterprises. Vikram helps financial and insurance industry customers with design, thought leadership to build and deploy machine learning applications at scale. In his spare time, he enjoys traveling, hiking, cooking and camping with his family.
Author: Shiva Raaj Kotini