

Instruction fine-tuning for FLAN T5 XL with Amazon SageMaker Jumpstart

Increasingly capable foundation models are being released continuously, with large language models (LLMs) being one of the most visible model classes… LLMs are models composed of billions of parameters trained on extensive corpora of text, up to hundreds of billions or even a trillion tokens… T…
Generative AI is in the midst of a period of stunning growth. Increasingly capable foundation models are being released continuously, with large language models (LLMs) being one of the most visible model classes. LLMs are models composed of billions of parameters trained on extensive corpora of text, up to hundreds of billions or even a trillion tokens. These models have proven extremely effective for a wide range of text-based tasks, from question answering to sentiment analysis.
The power of LLMs comes from their capacity to learn and generalize from extensive and diverse training data. The initial training of these models is performed with a variety of objectives, supervised, unsupervised, or hybrid. Text completion or imputation is one of the most common unsupervised objectives: given a chunk of text, the model learns to accurately predict what comes next (for example, predict the next sentence). Models can also be trained in a supervised fashion using labeled data to accomplish a set of tasks (for example, is this movie review positive, negative, or neutral). Whether the model is trained for text completion or some other task, it is frequently not the task customers want to use the model for.
To improve the performance of a pre-trained LLM on a specific task, we can tune the model using examples of the target task in a process known as instruction fine-tuning. Instruction fine-tuning uses a set of labeled examples in the form of {prompt, response} pairs to further train the pre-trained model in adequately predicting the response given the prompt. This process modifies the weights of the model.
This post describes how to perform instruction fine-tuning of an LLM, namely FLAN T5 XL, using Amazon SageMaker Jumpstart. We demonstrate how to accomplish this using both the Jumpstart UI and a notebook in Amazon SageMaker Studio. You can find the accompanying notebook in the amazon-sagemaker-examples GitHub repository.
Solution overview
The target task in this post is to, given a chunk of text in the prompt, return questions that are related to the text but can’t be answered based on the information it contains. This is a useful task to identify missing information in a description or identify whether a query needs more information to be answered.
FLAN T5 models are instruction fine-tuned on a wide range of tasks to increase the zero-shot performance of these models on many common tasks[1]. Additional instruction fine-tuning for a particular customer task can further increase the accuracy of these models, especially if the target task wasn’t previously used to train a FLAN T5 model, as is the case for our task.
In our example task, we’re interested in generating relevant but unanswered questions. To this end, we use a subset of the version 2 of the Stanford Question Answering Dataset (SQuAD2.0)[2] to fine-tune the model. This dataset contains questions posed by human annotators on a set of Wikipedia articles. In addition to questions with answers, SQuAD2.0 contains about 50,000 unanswerable questions. Such questions are plausible but can’t be directly answered from articles’ content. We only use the unanswerable questions. Our data is structured as a JSON Lines file, with each line containing a context and a question.

Prerequisites
To get started, all you need is an AWS account in which you can use Studio. You will need to create a user profile for Studio if you don’t already have one.
Fine-tune FLAN-T5 with the Jumpstart UI
To fine-tune the model with the Jumpstart UI, complete the following steps:
- On the SageMaker console, open Studio.
- Under SageMaker Jumpstart in the navigation pane, choose Models, notebooks, solutions.
You will see a list of foundation models, including FLAN T5 XL, which is marked as fine-tunable.
- Choose View model.
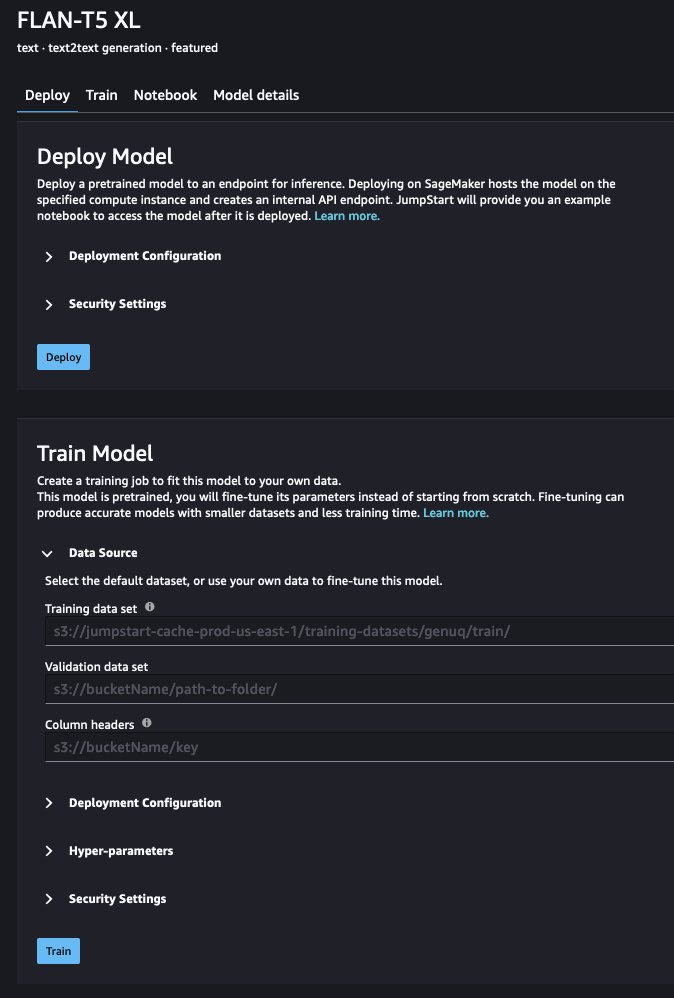
- Under Data source, you can provide the path to your training data. The source for the data used in this post is provided by default.
- You can keep the default value for the deployment configuration (including instance type), security, and the hyperparameters, but you should increase the number of epochs to at least three to get good results.
- Choose Train to train the model.
You can track the status of the training job in the UI.
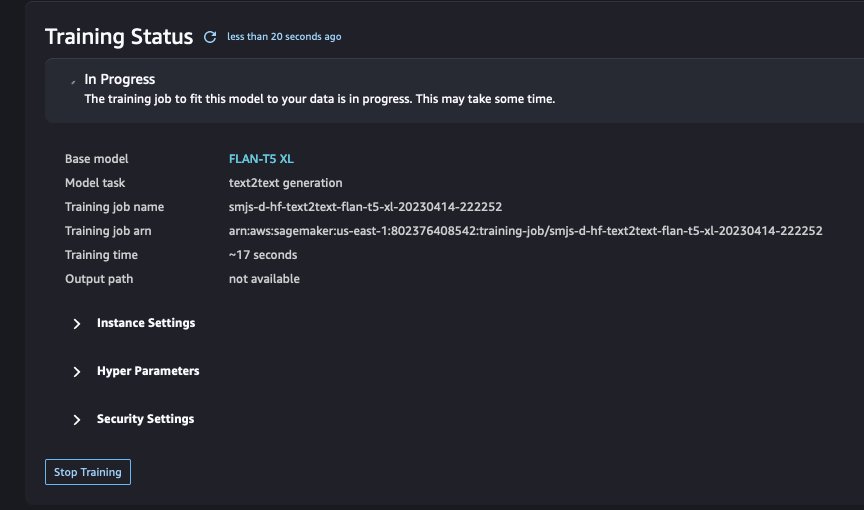
- When training is complete (after about 53 minutes in our case), choose Deploy to deploy the fine-tuned model.

After the endpoint is created (a few minutes), you can open a notebook and start using your fine-tuned model.
Fine-tune FLAN-T5 using a Python notebook
Our example notebook shows how to use Jumpstart and SageMaker to programmatically fine-tune and deploy a FLAN T5 XL model. It can be run in Studio or locally.
In this section, we first walk through some general setup. Then you fine-tune the model using the SQuADv2 datasets. Next, you deploy the pre-trained version of the model behind a SageMaker endpoint, and do the same with the fine-tuned model. Finally, you can query the endpoints and compare the quality of the output of the pre-trained and fine-tuned model. You will find that the output of the fine-tuned model is of much higher quality.
Set up prerequisites
Begin by installing and upgrading the necessary packages. Restart the kernel after running the following code:
Next, obtain the execution role associated with the current notebook instance:
You can define a convenient drop-down menu that will list the model sizes available for fine-tuning:
Jumpstart automatically retrieves appropriate training and inference instance types for the model that you chose:
You’re now ready to start fine-tuning.
Retrain the model on the fine-tuning dataset
After your setup is complete, complete the following steps:
Use the following code to retrieve the URI for the artifacts needed:
The training data is located in a public Amazon Simple Storage Service (Amazon S3) bucket.
Use the following code to point to the location of the data and set up the output location in a bucket in your account:
The original data is not in a format that corresponds to the task for which you are fine-tuning the model, so you can reformat it:
Now you can define some hyperparameters for the training:
You are now ready to launch the training job:
Depending on the size of the fine-tuning data and model chosen, the fine-tuning could take up to a couple of hours.
You can monitor performance metrics such as training and validation loss using Amazon CloudWatch during training. Conveniently, you can also fetch the most recent snapshot of metrics by running the following code:
When the training is complete, you have a fine-tuned model at model_uri. Let’s use it!
You can create two inference endpoints: one for the original pre-trained model, and one for the fine-tuned model. This allows you to compare the output of both versions of the model. In the next step, you deploy an inference endpoint for the pre-trained model. Then you deploy an endpoint for your fine-tuned model.
Deploy the pre-trained model
Let’s start by deploying the pre-trained model retrieve the inference Docker image URI. This is the base Hugging Face container image. Use the following code:
You can now create the endpoint and deploy the pre-trained model. Note that you need to pass the Predictor class when deploying model through the Model class to be able to run inference through the SageMaker API. See the following code:
The endpoint creation and model deployment can take a few minutes, then your endpoint is ready to receive inference calls.
Deploy the fine-tuned model
Let’s deploy the fine-tuned model to its own endpoint. The process is almost identical to the one we used earlier for the pre-trained model. The only difference is that we use the fine-tuned model name and URI:
When this process is complete, both pre-trained and fine-tuned models are deployed behind their own endpoints. Let’s compare their outputs.
Generate output and compare the results
Define some utility functions to query the endpoint and parse the response:
In the next code snippet, we define the prompt and the test data. The describes our target task, which is to generate questions that are related to the provided text but can’t be answered based on it.
The test data consists of three different paragraphs, one on the Australian city of Adelaide from the first two paragraphs of it Wikipedia page, one regarding Amazon Elastic Block Store (Amazon EBS) from the Amazon EBS documentation, and one of Amazon Comprehend from the Amazon Comprehend documentation. We expect the model to identify questions related to these paragraphs but that can’t be answered with the information provided therein.
You can now test the endpoints using the example articles
Test data: Adelaide
We use the following context:
The pre-trained model response is as follows:
The fine-tuned model responses are as follows:
Test data: Amazon EBS
We use the following context:
The pre-trained model responses are as follows:
The fine-tuned model responses are as follows:
Test data: Amazon Comprehend
We use the following context:
The pre-trained model responses are as follows:
The fine-tuned model responses are as follows:
The difference in output quality between the pre-trained model and the fine-tuned model is stark. The questions provided by the fine-tuned model touch on a wider range of topics. They are systematically meaningful questions, which isn’t always the case for the pre-trained model, as illustrated with the Amazon EBS example.
Although this doesn’t constitute a formal and systematic evaluation, it’s clear that the fine-tuning process has improved the quality of the model’s responses on this task.
Clean up
Lastly, remember to clean up and delete the endpoints:
Conclusion
In this post, we showed how to use instruction fine-tuning with FLAN T5 models using the Jumpstart UI or a Jupyter notebook running in Studio. We provided code explaining how to retrain the model using data for the target task and deploy the fine-tuned model behind an endpoint. The target task in this post was to identify questions that relate to a chunk of text provided in the input but can’t be answered based on the information provided in that text. We demonstrated that a model fine-tuned for this specific task returns better results than a pre-trained model.
Now that you know how to instruction fine-tune a model with Jumpstart, you can create powerful models customized for your application. Gather some data for your use case, uploaded it to Amazon S3, and use either the Studio UI or the notebook to tune a FLAN T5 model!
References
[1] Chung, Hyung Won, et al. “Scaling instruction-fine tuned language models.” arXiv preprint arXiv:2210.11416 (2022).
[2] Rajpurkar, Pranav, Robin Jia, and Percy Liang. “Know What You Don’t Know: Unanswerable Questions for SQuAD.” Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers). 2018.
About the authors
 Laurent Callot is a Principal Applied Scientist and manager at AWS AI Labs who has worked on a variety of machine learning problems, from foundational models and generative AI to forecasting, anomaly detection, causality, and AI Ops.
Laurent Callot is a Principal Applied Scientist and manager at AWS AI Labs who has worked on a variety of machine learning problems, from foundational models and generative AI to forecasting, anomaly detection, causality, and AI Ops.
![]() Andrey Kan is a Senior Applied Scientist at AWS AI Labs within interests and experience in different fields of Machine Learning. These include research on foundation models, as well as ML applications for graphs and time series.
Andrey Kan is a Senior Applied Scientist at AWS AI Labs within interests and experience in different fields of Machine Learning. These include research on foundation models, as well as ML applications for graphs and time series.
 Dr. Ashish Khetan is a Senior Applied Scientist with Amazon SageMaker built-in algorithms and helps develop machine learning algorithms. He got his PhD from University of Illinois Urbana Champaign. He is an active researcher in machine learning and statistical inference and has published many papers in NeurIPS, ICML, ICLR, JMLR, ACL, and EMNLP conferences.
Dr. Ashish Khetan is a Senior Applied Scientist with Amazon SageMaker built-in algorithms and helps develop machine learning algorithms. He got his PhD from University of Illinois Urbana Champaign. He is an active researcher in machine learning and statistical inference and has published many papers in NeurIPS, ICML, ICLR, JMLR, ACL, and EMNLP conferences.
 Baris Kurt is an Applied Scientist at AWS AI Labs. His interests are in time series anomaly detection and foundation models. He loves developing user friendly ML systems.
Baris Kurt is an Applied Scientist at AWS AI Labs. His interests are in time series anomaly detection and foundation models. He loves developing user friendly ML systems.
 Jonas Kübler is an Applied Scientist at AWS AI Labs. He is working on foundation models with the goal to facilitate use-case specific applications.
Jonas Kübler is an Applied Scientist at AWS AI Labs. He is working on foundation models with the goal to facilitate use-case specific applications.
Author: Laurent Callot