

Introducing Amazon Textract Bulk Document Uploader for enhanced evaluation and analysis
Amazon Textract is a machine learning (ML) service that automatically extracts text, handwriting, and data from any document or image… To make it simpler to evaluate the capabilities of Amazon Textract, we have launched a new Bulk Document Uploader feature on the Amazon Textract console that enabl…
Amazon Textract is a machine learning (ML) service that automatically extracts text, handwriting, and data from any document or image. To make it simpler to evaluate the capabilities of Amazon Textract, we have launched a new Bulk Document Uploader feature on the Amazon Textract console that enables you to quickly process your own set of documents without writing any code.
In this post, we walk through when and how to use the Amazon Textract Bulk Document Uploader to evaluate how Amazon Textract performs on your documents.
Overview of solution
The Bulk Document Uploader should be used for quick evaluation of Amazon Textract for predetermined use cases. By uploading multiple documents simultaneously through an intuitive UI, you can easily gauge how well Amazon Textract performs on your documents.
You can upload and process up to 150 documents at once. Unlike the existing Amazon Textract console demos, which impose artificial limits on the number of documents, document size, and maximum allowed number of pages, the Bulk Document Uploader supports processing up to 150 documents per request and has the same document size and page limits as the Amazon Textract APIs. This makes it more efficient for you to evaluate a larger set of documents.
The Bulk Document Uploader outputs a standard Amazon Textract JSON response and CSV file. The results are provided in JSON format for easy programmatic analysis. Additionally, a human-readable CSV file with confidence scores is provided for simple comparison and evaluation of the extracted information.
When using this feature, keep in mind the following:
- The Bulk Document Uploader processes documents via asynchronous operations. You can track the status of the processing on the Amazon Textract console. Only DetectDocumentText (OCR), AnalyzeDocument (Tables, Queries, Forms, and Signatures), and AnalyzeExpense APIs are currently supported.
- The Bulk Document Uploader provides JSON results of the API operations and formatted CSV reports. You may need to rely on external tools for visualization of the data, such as displaying bounding box highlights on the document using the JSON results.
- Using this feature to process documents incurs the same charges as regular Amazon Textract usage (depending on which feature is used), and is subject to the TPS (transactions per second) limits for APIs that are set for the account and Region. For more information on pricing, refer to Amazon Textract pricing. To learn more about Amazon Textract limits, refer to Quotas in Amazon Textract.
- Accepted file formats for bulk uploader are JPEG, PNG, TIF, and PDF. JPEG 2000-encoded images within PDFs are also supported. JPEG and PNG files have a 10 MB size limit, whereas PDF and TIF files have a 500 MB size limit. Multi-page PDF and TIF files have a 3,000 page limit.
Use the Bulk Document Uploader
The Bulk Document Uploader is intended to help you quickly evaluate how Amazon Textract performs on a set of your own documents, without needing to write any code. You can use the Bulk Document Uploader to process as many as 150 documents instead of uploading and processing documents individually. You can bulk upload documents directly from your computer or import documents from an existing Amazon Simple Storage Service (Amazon S3) bucket.
The Bulk Document Uploader provides results that you can download later for offline review. Each downloadable ZIP file contains the Amazon Textract API response in JSON file format and a human-readable CSV file of the output containing the extracted data and confidence scores. The output results are available for download for 7 days after processing. After 14 days, documents are cleared from the Submitted documents section. To use the Bulk Document Uploader, complete the following steps:
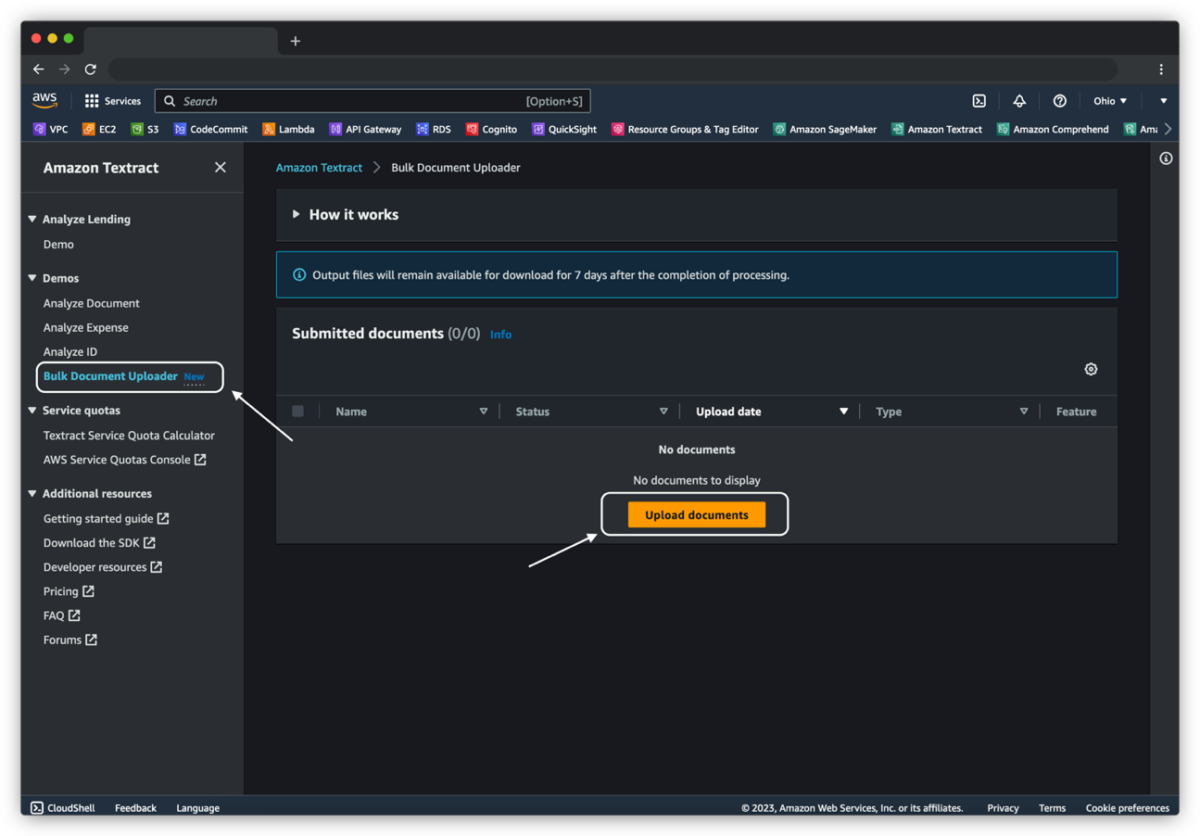
- On the Amazon Textract console, under Demos in the navigation pane, choose Bulk Document Uploader.
- Choose Upload documents.

- Specify the source of your documents.

You have two options to upload documents:
- Import documents from S3 bucket – If you’re using an S3 bucket for your documents, provide the bucket URL and (optionally) the prefix where your documents reside, in
s3://your-bucket/prefix/format. Alternatively, choose Browse S3 to browse and select the desired location of your documents. If the Amazon S3 location you specified contains more than 150 documents, then only the first 150 documents will be sent to Amazon Textract for processing.

- Upload documents from your computer – If you’re uploading documents from your computer, you can upload up to 50 documents at a time by choosing Upload Documents. To upload additional documents (up to the maximum of 150), choose Add documents after your initial documents are uploaded.



In this case, your documents are first uploaded to an S3 bucket in your account that is created on your behalf, therefore it’s important to ensure that you have permissions to access and upload documents to Amazon S3. This is a one-time action, and the same bucket will be used for all subsequent uploads from your computer. If you want to upload and process the same set of documents, you can use the path to this S3 bucket using the Import documents from S3 bucket option. The S3 bucket created on your behalf will be visible after the bucket gets created.

- Next, specify the Amazon Textract feature you want to use to process your documents.
You may select only one feature at a time to process your documents. If you need to evaluate additional features, you must create a separate request by selecting the desired feature and uploading the documents again. If the AnalyzeDocument – Queries feature is selected, you need to provide the queries you want to test against your documents. You can specify up to 30 queries at a time. If the uploaded documents contain multi-page (PDF or TIF) files, queries are only applied to the first page of each document. Refer to Best Practices for Queries to learn about how to construct queries.

- Choose Start processing to submit the documents to Amazon Textract for processing.
You can track the document status and download the output results of processed documents in the Submitted documents section. This section updates periodically, and you can manually refresh it to see if the processing is complete. Each document is processed individually, so you can either select the document with Ready to download status or wait for all documents to complete processing to download the results. The output of the processed documents will remain available for up to 7 days for download, after which they will expire. Expired documents will be cleared from the Submitted documents section after 7 additional days (14 days from the processed date). We suggest downloading and preserving the outputs within the 7-day period.

Conclusion
In this post, we announced the new Amazon Textract Bulk Document Uploader feature, which allows you to quickly process a large number of documents for evaluation purposes. You can use this feature to evaluate Amazon Textract for a predetermined use case with your documents. To learn more about how you can use Amazon Textract in your intelligent document processing workload, visit Amazon Textract features and Getting started with Amazon Textract.
About the Authors
 Shashwat Sapre is a Senior Technical Product Manager with the Amazon Textract team. He is focused on building machine learning-based services for AWS customers. In his spare time, he likes reading about new technologies, traveling and exploring different cuisines.
Shashwat Sapre is a Senior Technical Product Manager with the Amazon Textract team. He is focused on building machine learning-based services for AWS customers. In his spare time, he likes reading about new technologies, traveling and exploring different cuisines.
 Anjan Biswas is a Senior AI Services Solutions Architect with a focus on AI/ML and Data Analytics. Anjan is part of the world-wide AI services team and works with customers to help them understand and develop solutions to business problems with AI and ML. Anjan has over 14 years of experience working with global supply chain, manufacturing, and retail organizations, and is actively helping customers get started and scale on AWS AI services.
Anjan Biswas is a Senior AI Services Solutions Architect with a focus on AI/ML and Data Analytics. Anjan is part of the world-wide AI services team and works with customers to help them understand and develop solutions to business problems with AI and ML. Anjan has over 14 years of experience working with global supply chain, manufacturing, and retail organizations, and is actively helping customers get started and scale on AWS AI services.
Author: Shashwat Sapre