

Introducing an image-to-speech Generative AI application using Amazon SageMaker and Hugging Face
Accessibility has come a long way, but what about images? At the 2022 AWS re:Invent conference in Las Vegas, we demonstrated “Describe for Me” at the AWS Builders’ Fair, a website which helps the visually impaired understand images through image caption, facial recognition, and text-to-spee…
Vision loss comes in various forms. For some, it’s from birth, for others, it’s a slow descent over time which comes with many expiration dates: The day you can’t see pictures, recognize yourself, or loved ones faces or even read your mail. In our previous blogpost Enable the Visually Impaired to Hear Documents using Amazon Textract and Amazon Polly, we showed you our Text to Speech application called “Read for Me”. Accessibility has come a long way, but what about images?
At the 2022 AWS re:Invent conference in Las Vegas, we demonstrated “Describe for Me” at the AWS Builders’ Fair, a website which helps the visually impaired understand images through image caption, facial recognition, and text-to-speech, a technology we refer to as “Image to Speech.” Through the use of multiple AI/ML services, “Describe For Me” generates a caption of an input image and will read it back in a clear, natural-sounding voice in a variety of languages and dialects.
In this blog post we walk you through the Solution Architecture behind “Describe For Me”, and the design considerations of our solution.
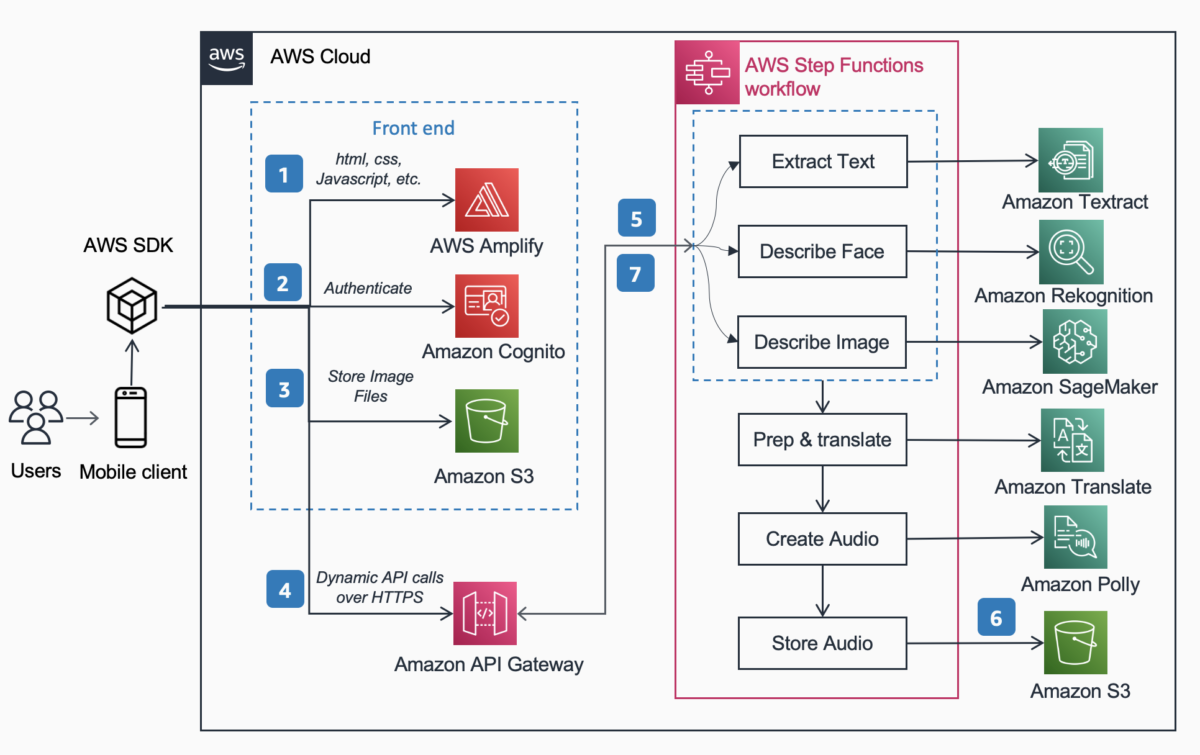
Solution Overview
The following Reference Architecture shows the workflow of a user taking a picture with a phone and playing an MP3 of the captioning the image.

The workflow includes the below steps,
- AWS Amplify distributes the DescribeForMe web app consisting of HTML, JavaScript, and CSS to end users’ mobile devices.
- The Amazon Cognito Identity pool grants temporary access to the Amazon S3 bucket.
- The user uploads an image file to the Amazon S3 bucket using AWS SDK through the web app.
- The DescribeForMe web app invokes the backend AI services by sending the Amazon S3 object Key in the payload to Amazon API Gateway
- Amazon API Gateway instantiates an AWS Step Functions workflow. The state Machine orchestrates the Artificial Intelligence /Machine Learning (AI/ML) services Amazon Rekognition, Amazon SageMaker, Amazon Textract, Amazon Translate, and Amazon Polly using AWS lambda functions.
- The AWS Step Functions workflow creates an audio file as output and stores it in Amazon S3 in MP3 format.
- A pre-signed URL with the location of the audio file stored in Amazon S3 is sent back to the user’s browser through Amazon API Gateway. The user’s mobile device plays the audio file using the pre-signed URL.
Solution Walkthrough
In this section, we focus on the design considerations for why we chose
- parallel processing within an AWS Step Functions workflow
- unified sequence-to-sequence pre-trained machine learning model OFA (One For All) from Hugging Face to Amazon SageMaker for image caption
- Amazon Rekognition for facial recognition
For a more detailed overview of why we chose a serverless architecture, synchronous workflow, express step functions workflow, headless architecture and the benefits gained, please read our previous blog post Enable the Visually Impaired to Hear Documents using Amazon Textract and Amazon Polly.
Parallel Processing
Using parallel processing within the Step Functions workflow reduced compute time up to 48%. Once the user uploads the image to the S3 bucket, Amazon API Gateway instantiates an AWS Step Functions workflow. Then the below three Lambda functions process the image within the Step Functions workflow in parallel.
- The first Lambda function called
describe_imageanalyzes the image using the OFA_IMAGE_CAPTION model hosted on a SageMaker real-time endpoint to provide image caption. - The second Lambda function called
describe_facesfirst checks if there are faces using Amazon Rekognition’s Detect Faces API, and if true, it calls the Compare Faces API. The reason for this is Compare Faces will throw an error if there are no faces found in the image. Also, calling Detect Faces first is faster than simply running Compare Faces and handling errors, so for images without faces in them, processing time will be faster. - The third Lambda function called
extract_texthandles text-to-speech utilizing Amazon Textract, and Amazon Comprehend.
Executing the Lambda functions in succession is suitable, but the faster, more efficient way of doing this is through parallel processing. The following table shows the compute time saved for three sample images.
| Image | People | Sequential Time | Parallel Time | Time Savings (%) | Caption |
 | 0 | 1869ms | 1702ms | 8% | A tabby cat curled up in a fluffy white bed. |
 | 1 | 4277ms | 2197ms | 48% | A woman in a green blouse and black cardigan smiles at the camera. I recognize one person: Kanbo. |
 | 4 | 6603ms | 3904ms | 40% | People standing in front of the Amazon Spheres. I recognize 3 people: Kanbo, Jack, and Ayman. |
Image Caption
Hugging Face is an open-source community and data science platform that allows users to share, build, train, and deploy machine learning models. After exploring models available in the Hugging Face model hub, we chose to use the OFA model because as described by the authors, it is “a task-agnostic and modality-agnostic framework that supports Task Comprehensiveness”.
OFA is a step towards “One For All”, as it is a unified multimodal pre-trained model that can transfer to a number of downstream tasks effectively. While the OFA model supports many tasks including visual grounding, language understanding, and image generation, we used the OFA model for image captioning in the Describe For Me project to perform the image to text portion of the application. Check out the official repository of OFA (ICML 2022), paper to learn about OFA’s Unifying Architectures, Tasks, and Modalities Through a Simple Sequence-to-Sequence Learning Framework.
To integrate OFA in our application we cloned the repo from Hugging Face and containerized the model to deploy it to a SageMaker endpoint. The notebook in this repo is an excellent guide to deploy the OFA large model in a Jupyter notebook in SageMaker. After containerizing your inference script, the model is ready to be deployed behind a SageMaker endpoint as described in the SageMaker documentation. Once the model is deployed, create an HTTPS endpoint which can be integrated with the “describe_image” lambda function that analyzes the image to create the image caption. We deployed the OFA tiny model because it is a smaller model and can be deployed in a shorter period of time while achieving similar performance.
Examples of image to speech content generated by “Describe For Me“ are shown below:

The aurora borealis, or northern lights, fill the night sky above a silhouette of a house..

A dog sleeps on a red blanket on a hardwood floor, next to an open suitcase filled with toys..

A tabby cat curled up in a fluffy white bed.
Facial recognition
Amazon Rekognition Image provides the DetectFaces operation that looks for key facial features such as eyes, nose, and mouth to detect faces in an input image. In our solution we leverage this functionality to detect any people in the input image. If a person is detected, we then use the CompareFaces operation to compare the face in the input image with the faces that “Describe For Me“ has been trained with and describe the person by name. We chose to use Rekognition for facial detection because of the high accuracy and how simple it was to integrate into our application with the out of the box capabilities.

A group of people posing for a picture in a room. I recognize 4 people: Jack, Kanbo, Alak, and Trac. There was text found in the image as well. It reads: AWS re: Invent
Potential Use Cases
Alternate Text Generation for web images
All images on a web site are required to have an alternative text so that screen readers can speak them to the visually impaired. It’s also good for search engine optimization (SEO). Creating alt captions can be time consuming as a copywriter is tasked with providing them within a design document. The Describe For Me API could automatically generate alt-text for images. It could also be utilized as a browser plugin to automatically add image caption to images missing alt text on any website.
Audio Description for Video
Audio Description provides a narration track for video content to help the visually impaired follow along with movies. As image caption becomes more robust and accurate, a workflow involving the creation of an audio track based upon descriptions for key parts of a scene could be possible. Amazon Rekognition can already detect scene changes, logos, and credit sequences, and celebrity detection. A future version of describe would allow for automating this key feature for films and videos.
Conclusion
In this post, we discussed how to use AWS services, including AI and serverless services, to aid the visually impaired to see images. You can learn more about the Describe For Me project and use it by visiting describeforme.com. Learn more about the unique features of Amazon SageMaker, Amazon Rekognition and the AWS partnership with Hugging Face.
Third Party ML Model Disclaimer for Guidance
This guidance is for informational purposes only. You should still perform your own independent assessment, and take measures to ensure that you comply with your own specific quality control practices and standards, and the local rules, laws, regulations, licenses and terms of use that apply to you, your content, and the third-party Machine Learning model referenced in this guidance. AWS has no control or authority over the third-party Machine Learning model referenced in this guidance, and does not make any representations or warranties that the third-party Machine Learning model is secure, virus-free, operational, or compatible with your production environment and standards. AWS does not make any representations, warranties or guarantees that any information in this guidance will result in a particular outcome or result.
About the Authors
 Jack Marchetti is a Senior Solutions architect at AWS focused on helping customers modernize and implement serverless, event-driven architectures. Jack is legally blind and resides in Chicago with his wife Erin and cat Minou. He also is a screenwriter, and director with a primary focus on Christmas movies and horror. View Jack’s filmography at his IMDb page.
Jack Marchetti is a Senior Solutions architect at AWS focused on helping customers modernize and implement serverless, event-driven architectures. Jack is legally blind and resides in Chicago with his wife Erin and cat Minou. He also is a screenwriter, and director with a primary focus on Christmas movies and horror. View Jack’s filmography at his IMDb page.
 Alak Eswaradass is a Senior Solutions Architect at AWS based in Chicago, Illinois. She is passionate about helping customers design cloud architectures utilizing AWS services to solve business challenges. Alak is enthusiastic about using SageMaker to solve a variety of ML use cases for AWS customers. When she’s not working, Alak enjoys spending time with her daughters and exploring the outdoors with her dogs.
Alak Eswaradass is a Senior Solutions Architect at AWS based in Chicago, Illinois. She is passionate about helping customers design cloud architectures utilizing AWS services to solve business challenges. Alak is enthusiastic about using SageMaker to solve a variety of ML use cases for AWS customers. When she’s not working, Alak enjoys spending time with her daughters and exploring the outdoors with her dogs.
 Kandyce Bohannon is a Senior Solutions Architect based out of Minneapolis, MN. In this role, Kandyce works as a technical advisor to AWS customers as they modernize technology strategies especially related to data and DevOps to implement best practices in AWS. Additionally, Kandyce is passionate about mentoring future generations of technologists and showcasing women in technology through the AWS She Builds Tech Skills program.
Kandyce Bohannon is a Senior Solutions Architect based out of Minneapolis, MN. In this role, Kandyce works as a technical advisor to AWS customers as they modernize technology strategies especially related to data and DevOps to implement best practices in AWS. Additionally, Kandyce is passionate about mentoring future generations of technologists and showcasing women in technology through the AWS She Builds Tech Skills program.
 Trac Do is a Solutions Architect at AWS. In his role, Trac works with enterprise customers to support their cloud migrations and application modernization initiatives. He is passionate about learning customers’ challenges and solving them with robust and scalable solutions using AWS services. Trac currently lives in Chicago with his wife and 3 boys. He is a big aviation enthusiast and in the process of completing his Private Pilot License.
Trac Do is a Solutions Architect at AWS. In his role, Trac works with enterprise customers to support their cloud migrations and application modernization initiatives. He is passionate about learning customers’ challenges and solving them with robust and scalable solutions using AWS services. Trac currently lives in Chicago with his wife and 3 boys. He is a big aviation enthusiast and in the process of completing his Private Pilot License.
Author: Jack Marchetti