

Introducing guardrails in Knowledge Bases for Amazon Bedrock
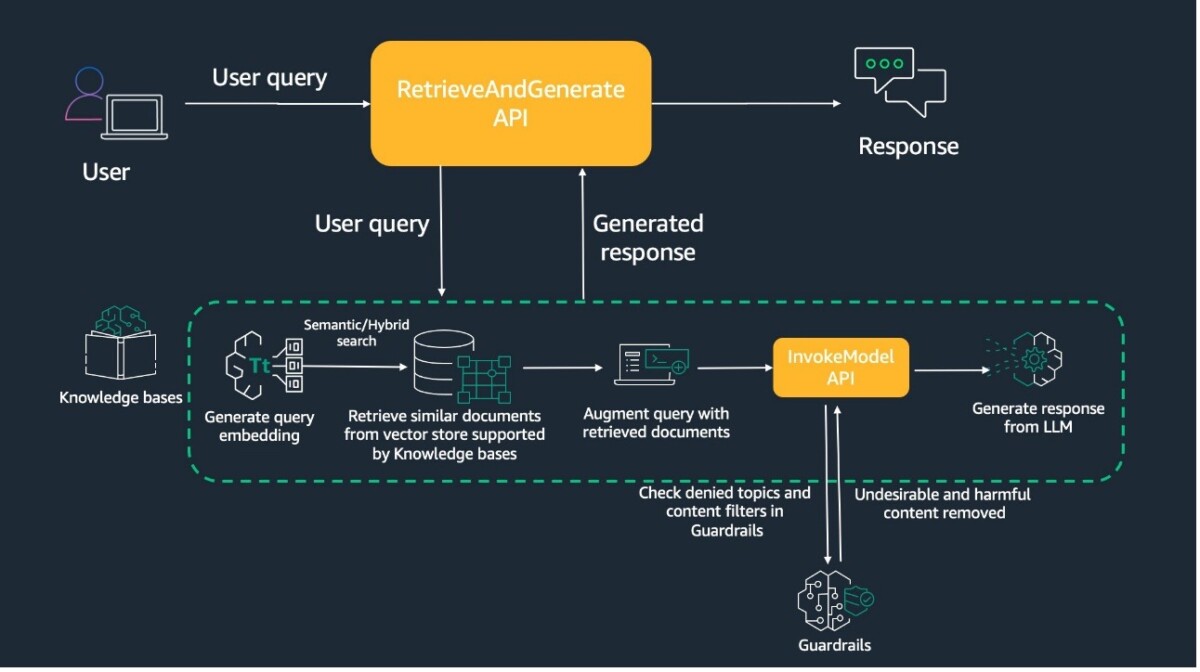
Solution overview Knowledge Bases for Amazon Bedrock allows you to configure your RAG applications to query your knowledge base using the RetrieveAndGenerate API, generating responses from the retrieved information… By default, knowledge bases allow your RAG applications to query the entire ve…
Knowledge Bases for Amazon Bedrock is a fully managed capability that helps you securely connect foundation models (FMs) in Amazon Bedrock to your company data using Retrieval Augmented Generation (RAG). This feature streamlines the entire RAG workflow, from ingestion to retrieval and prompt augmentation, eliminating the need for custom data source integrations and data flow management.
We recently announced the general availability of Guardrails for Amazon Bedrock, which allows you to implement safeguards in your generative artificial intelligence (AI) applications that are customized to your use cases and responsible AI policies. You can create multiple guardrails tailored to various use cases and apply them across multiple FMs, standardizing safety controls across generative AI applications.
Today’s launch of guardrails in Knowledge Bases for Amazon Bedrock brings enhanced safety and compliance to your generative AI RAG applications. This new functionality offers industry-leading safety measures that filter harmful content and protect sensitive information in your documents, improving user experience and aligning with organizational standards.
Solution overview
Knowledge Bases for Amazon Bedrock allows you to configure your RAG applications to query your knowledge base using the RetrieveAndGenerate API, generating responses from the retrieved information.
By default, knowledge bases allow your RAG applications to query the entire vector database, accessing all records and retrieving relevant results. This may lead to the generation of inappropriate or undesirable content or provide sensitive information, which could potentially violate certain policies or guidelines set by your company. Integrating guardrails with your knowledge base provides a mechanism to filter and control the generated output, complying with predefined rules and regulations.
The following diagram illustrates an example workflow.

When you test the knowledge base using the Amazon Bedrock console or call the RetrieveAndGenerate API using one of the AWS SDKs, the system generates a query embedding and performs a semantic search to retrieve similar documents from the vector store.
The query is then augmented to have the retrieved document chunks, prompt, and guardrails configuration. Guardrails are applied to check for denied topics and filter out harmful content before the augmented query is sent to the InvokeModel API. Finally, the InvokeModel API generates a response from the large language model (LLM), making sure the output is free of any undesirable content.
In the following sections, we demonstrate how to create a knowledge base with guardrails. We also compare query results using the same knowledge base with and without guardrails.
Use cases for guardrails with Knowledge Bases for Amazon Bedrock
The following are common use cases for integrating guardrails in the knowledge base:
- Internal knowledge management for a legal firm — This helps legal professionals search through case files, legal precedents, and client communications. Guardrails can prevent the retrieval of confidential client information and filter out inappropriate language. For instance, a lawyer might ask, “What are the key points from the latest case law on intellectual property?” and guardrails will make sure no confidential client details or inappropriate language are included in the response, maintaining the integrity and confidentiality of the information.
- Conversational search for financial services — This enables financial advisors to search through investment portfolios, transaction histories, and market analyses. Guardrails can prevent the retrieval of unauthorized investment advice and filter out content that violates regulatory compliance. An example query could be, “What are the recent performance metrics for our high-net-worth clients?” with guardrails making sure only permissible information is shared.
- Customer support for an ecommerce platform — This allows customer service representatives to access order histories, customer queries, and product details. Guardrails can block sensitive customer data (like names, emails, or addresses) from being exposed in responses. For example, when a representative asks, “Can you summarize the recent complaints about our new product line?” guardrails will redact any personally identifiable information (PII), enforcing privacy and compliance with data protection regulations.
Prepare a dataset for Knowledge Bases for Amazon Bedrock
For this post, we use a sample dataset containing multiple fictional emergency room reports, such as detailed procedural notes, preoperative and postoperative diagnoses, and patient histories. These records illustrate how to integrate knowledge bases with guardrails and query them effectively.
- If you want to follow along in your AWS account, download the file. Each medical record is a Word document.
- We store the dataset in an Amazon Simple Storage Service (Amazon S3) bucket. For instructions to create a bucket, see Creating a bucket.
- Upload the unzipped files to this S3 bucket.
Create a knowledge base for Amazon Bedrock
For instructions to create a new knowledge base, see Create a knowledge base. For this example, we use the following settings:
- On the Configure data source page, under Amazon S3, choose the S3 bucket with your dataset.
- Under Chunking strategy, select No chunking because the documents in the dataset are preprocessed to be within a certain length.
- In the Embeddings model section, choose model Titan G1 Embeddings – Text.
- In the Vector database section, choose Quick create a new vector store.

Synchronize the dataset with the knowledge base
After you create the knowledge base, and your data files are in an S3 bucket, you can start the incremental ingestion. For instructions, see Sync to ingest your data sources into the knowledge base.
While you wait for the sync job to finish, you can move on to the next section, where you create guardrails.
Create a guardrail on the Amazon Bedrock console
Complete the following steps to create a guardrail:
- On the Amazon Bedrock console, choose Guardrails in the navigation pane.
- Choose Create guardrail.
- On the Provide guardrail details page, under Guardrail details, provide a name and optional description for the guardrail.
- In the Denied topics section, add the information for two topics as shown in the following screenshot.
- In the Add sensitive information filters section, under PII types, add all the PII types.
- Choose Create guardrail.

Query the knowledge base on the Amazon Bedrock console
Let’s now test our knowledge base with guardrails:
- On the Amazon Bedrock console, choose Knowledge bases in the navigation pane.
- Choose the knowledge base you created.
- Choose Test knowledge base.
- Choose the Configurations icon, then scroll down to Guardrails.
The following screenshots show some side-by-side comparisons of querying a knowledge base without (left) and with (right) guardrails.
The first example illustrates querying against denied topics.

Next, we query data that contains PII.

Finally, we query about another denied topic.

Query the knowledge base with using the AWS SDK
You can use the following sample code to query the knowledge base with guardrails using the AWS SDK for Python (Boto3):
import boto3
client = boto3.client('bedrock-agent-runtime')
response = client.retrieve_and_generate(
input={
'text': 'Example input text'
},
retrieveAndGenerateConfiguration={
'knowledgeBaseConfiguration': {
'generationConfiguration': {
'guardrailConfiguration': {
'guardrailId': 'your-guardrail-id',
'guardrailVersion': 'your-guardrail-version'
}
},
'knowledgeBaseId': 'your-knowledge-base-id',
'modelArn': 'your-model-arn'
},
'type': 'KNOWLEDGE_BASE'
},
sessionId='your-session-id'
)Clean up
To clean up your resources, complete the following steps:
- Delete the knowledge base:
- On the Amazon Bedrock console, choose Knowledge bases under Orchestration in the navigation pane.
- Choose the knowledge base you created.
- Take note of the AWS Identity and Access Management (IAM) service role name in the Knowledge base overview
- In the Vector database section, take note of the Amazon OpenSearch Serverless collection ARN.
- Choose Delete, then enter delete to confirm.
- Delete the vector database:
- On the Amazon OpenSearch Service console, choose Collections under Serverless in the navigation pane.
- Enter the collection ARN you saved in the search bar.
- Select the collection and chose Delete.
- Enter confirm in the confirmation prompt, then choose Delete.
- Delete the IAM service role:
- On the IAM console, choose Roles in the navigation pane.
- Search for the role name you noted earlier.
- Select the role and choose Delete.
- Enter the role name in the confirmation prompt and delete the role.
- Delete the sample dataset:
- On the Amazon S3 console, navigate to the S3 bucket you used.
- Select the prefix and files, then choose Delete.
- Enter permanently delete in the confirmation prompt to delete.
Conclusion
In this post, we covered the integration of guardrails with Knowledge Bases for Amazon Bedrock. With this, you can benefit from a robust and customizable safety framework that aligns with your application’s unique requirements and responsible AI practices. This integration aims to enhance the overall security, compliance, and responsible usage of foundation models within the knowledge base ecosystem, providing you with greater control and confidence in your AI-driven applications.
For pricing information, visit Amazon Bedrock Pricing. To get started using Knowledge Bases for Amazon Bedrock, refer to Create a knowledge base. For deep-dive technical content and to learn how our Builder communities are using Amazon Bedrock in their solutions, visit our community.aws website.
About the Authors
 Hardik Vasa is a Senior Solutions Architect at AWS. He focuses on Generative AI and Serverless technologies, helping customers make the best use of AWS services. Hardik shares his knowledge at various conferences and workshops. In his free time, he enjoys learning about new tech, playing video games, and spending time with his family.
Hardik Vasa is a Senior Solutions Architect at AWS. He focuses on Generative AI and Serverless technologies, helping customers make the best use of AWS services. Hardik shares his knowledge at various conferences and workshops. In his free time, he enjoys learning about new tech, playing video games, and spending time with his family.
 Bani Sharma is a Sr Solutions Architect with Amazon Web Services (AWS), based out of Denver, Colorado. As a Solutions Architect, she works with a large number of Small and Medium businesses, and provides technical guidance and solutions on AWS. She has an area of depth in Containers, modernization and currently working on gaining depth in Generative AI. Prior to AWS, Bani worked in various technical roles for a large Telecom provider and worked as a Senior Developer for a multi-national bank.
Bani Sharma is a Sr Solutions Architect with Amazon Web Services (AWS), based out of Denver, Colorado. As a Solutions Architect, she works with a large number of Small and Medium businesses, and provides technical guidance and solutions on AWS. She has an area of depth in Containers, modernization and currently working on gaining depth in Generative AI. Prior to AWS, Bani worked in various technical roles for a large Telecom provider and worked as a Senior Developer for a multi-national bank.
Author: Hardik Vasa