

Level up data-driven player insights with the updated Game Analytics Pipeline
To address these challenges, Amazon Web Services (AWS) developed the Guidance for Game Analytics Pipeline on AWS, a modular and serverless solution to help studios ingest, store, process, and visualize game event data… Data stack flexibility The guidance now supports Apache Iceberg tables and a…
In the fast-paced gaming industry, successful studios utilize real player data to drive game development. Data-driven insights create powerful feedback loops to refine game features, optimize monetization strategies, detect cheaters, and improve performance. This empowers developers to improve player experiences and drive growth.
Despite recognizing the value of analytics, many game studios grapple with limited resources, technical expertise, and time constraints that make it challenging to build and maintain robust analytics pipelines. To address these challenges, Amazon Web Services (AWS) developed the Guidance for Game Analytics Pipeline on AWS, a modular and serverless solution to help studios ingest, store, process, and visualize game event data.
The guidance has continuously evolved since the first release in 2021 to meet new customer use cases with a solution that emphasizes minimal management overhead and high extensibility. This approach empowers developers to focus on deriving valuable insights from their data, rather than managing infrastructure, while maintaining the flexibility to adapt as requirements change.
What’s new
The guidance has been updated to reflect new features and updated best practices. This release introduces new options for:
- Deployment
- Data stack flexibility
- Data ingestion
- Real-time analytics
- Infrastructure upgrades
These improvements make the pipeline more powerful and flexible to suit new use cases and unlock deeper insights.
All new features and configuration options have been documented on the documentation site. You can visit the site to view the comprehensive guidance to setup, customize, and troubleshoot the game analytics pipeline.
More deployment options
HashiCorp Terraform has been added as an alternative deployment option to the AWS Cloud Development Kit (AWS CDK), a highly requested feature from our user community. This new option provides flexibility to integrate and deploy the Guidance for Game Analytics Pipeline with your existing Infrastructure as Code (IaC) stack of choice. The new templates maintain the same modular architecture as the AWS CDK implementation. This design allows teams to customize the pipeline to suit evolving workload requirements.
Data stack flexibility
The guidance now supports Apache Iceberg tables and an option to deploy with Amazon Redshift Serverless, in addition to the existing Apache Hive table support. Apache Iceberg support brings a host of benefits including atomic updates, improved query performance, and interoperability with compatible third-party analytics tools. Apache Iceberg tables are deployed with automated table optimization to reduce storage costs and improve query performance with minimal operational overhead.
Amazon Redshift unlocks new capabilities for use cases with high concurrency, high volume, and low latency requirements. It can provide better price-performance for frequent large data volume queries. Whether you prefer a data lake approach with Apache Hive or Iceberg tables, or a data warehouse solution with Amazon Redshift, these options offer more versatility to manage and analyze your game data for your specific needs.
More ways to ingest data
The data ingestion stage of the guidance now offers more options to match your specific throughput and latency requirements. Amazon Kinesis Data Streams can be toggled between on-demand and provisioned modes, offering flexible scaling options for varying traffic patterns.
For use cases where real-time processing isn’t critical, direct ingestion to Amazon Data Firehose enables reliable near real-time delivery of game events to your data lake. These choices help optimize performance and cost by being able to choose the appropriate ingestion method to match your specific workload requirements.
Updated real-time analytics capabilities
The real-time analytics capabilities have been upgraded from Kinesis Data Analytics for SQL applications to Amazon Managed Service for Apache Flink, a powerful and flexible open-source framework for stream processing. Real-time visualization and analysis capabilities have been enhanced with Amazon OpenSearch Service support. Custom metrics are stored in a Amazon OpenSearch Serverless time-series collection using Amazon OpenSearch Ingestion. The next-generation OpenSearch UI provides collaborative workspaces with natural language capabilities and multi-source data integration. These powerful services provide new capabilities for transforming complex data into actionable real-time insights, unlocking deeper visibility into player behavior.
Updates and upgrades
Based on customer feedback, the solution was streamlined to focus on the core analytics infrastructure. Customers expressed a preference to integrate their own continuous integration and delivery (CI/CD) tools for consistency with existing deployment processes. The updated solution provides greater deployment flexibility by removing the DataOps CI/CD deployment requirement. You can view the updated deployment model by following the Get Started section within the guide documentation.
Compute components have also been upgraded to utilize the latest service versions and compute options. The AWS Lambda functions have been updated to the latest Node.js runtime, AWS SDK for JavaScript v3, and now utilize AWS Graviton processors for improved price-performance. The data processing jobs have been upgraded to AWS Glue 5.0, while development environments have been refreshed with updated development containers and CDK versions.
Architecture review
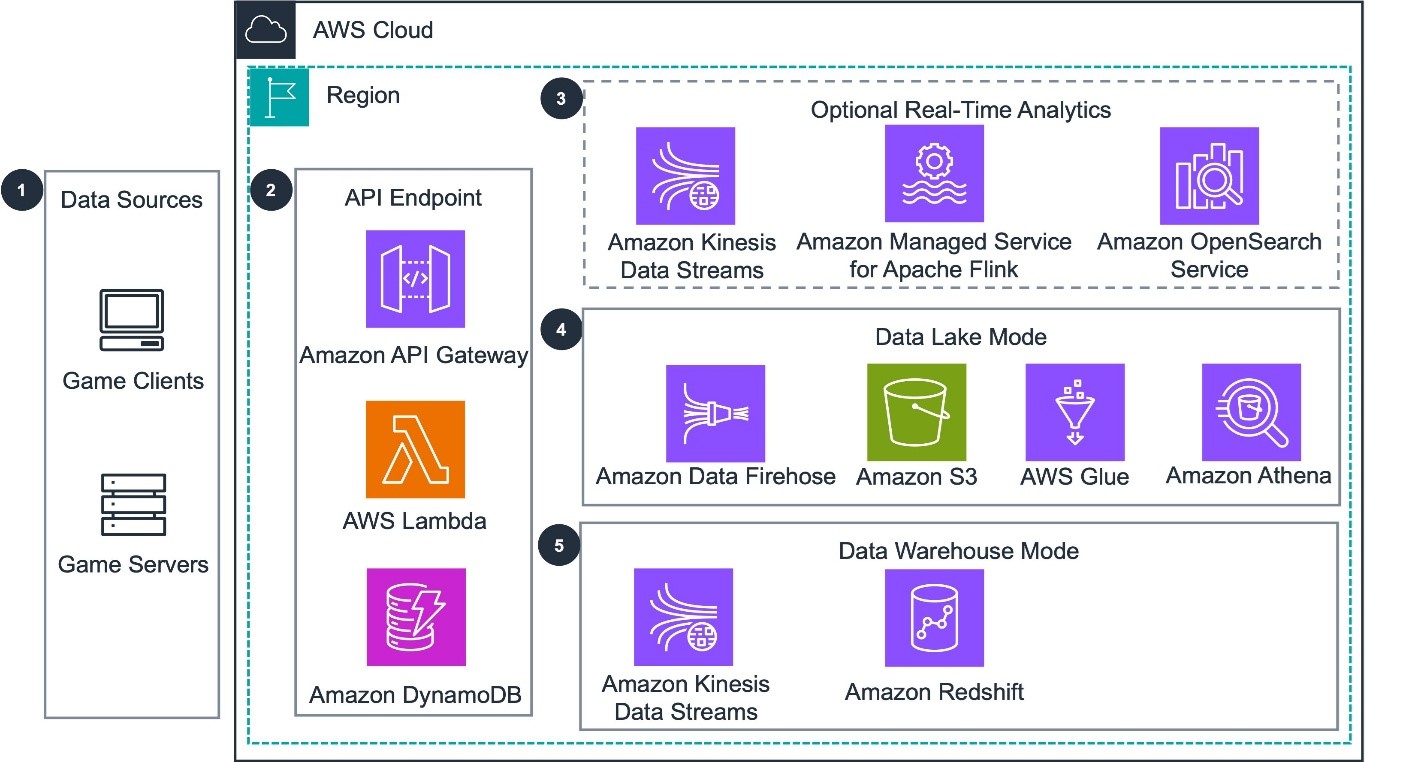
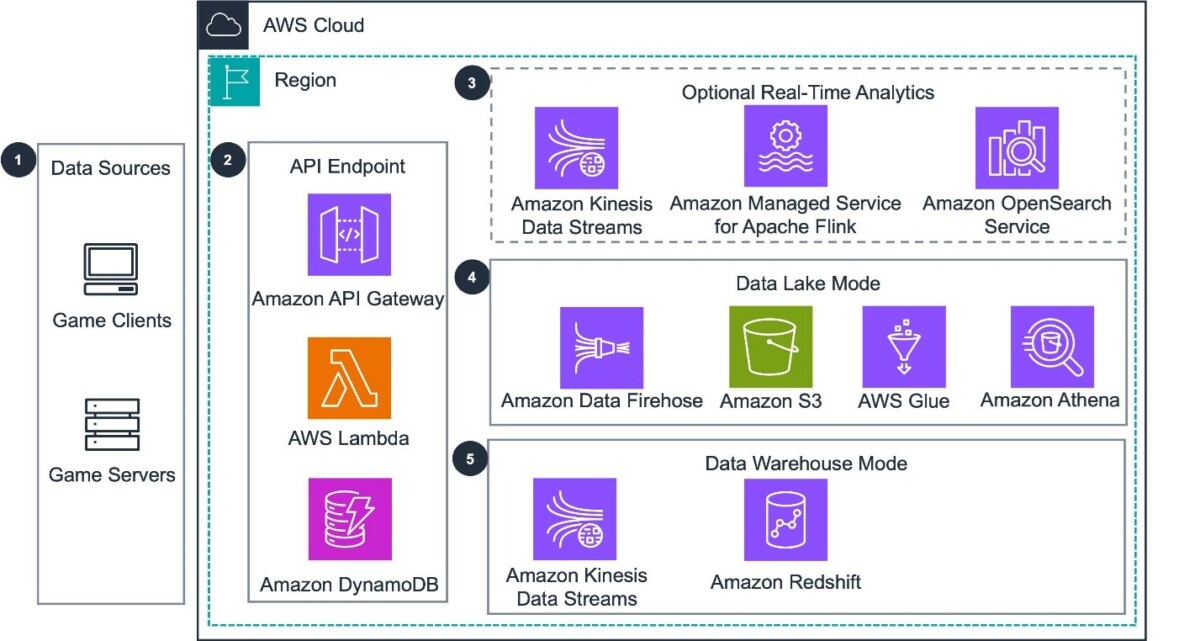
Figure 1: Architecture diagram of the Guidance for Game Analytics Pipeline on AWS solution.
The Game Analytics Pipeline streamlines the collection and processing of game event data to generate player insights. The following is an overview of the data flow through the key components used to derive insights:
- The Guidance for Game Analytics Pipeline Guidance accepts game event data from HTTPS REST based sources (such as game clients, game servers, or backend services).
- Amazon API Gateway provides REST API endpoints for data producers to send events and for administrators to perform management tasks using AWS Lambda. Data producers can be registered with access keys to send events to the API proxy. Game configurations and API access keys are stored in Amazon DynamoDB.
- An optional real-time analytics pipeline captures streaming event data through Amazon Kinesis Data Streams. The pipeline processes events with Amazon Managed Service for Apache Flink, and publishes custom metrics to Amazon OpenSearch Service. The OpenSearch Service UI provides interactive visualizations and alerts for real-time monitoring of these metrics.
- When the guidance is deployed using a data lake, events are batched using Amazon Data Firehose, stored in Parquet in Amazon Simple Storage Service (Amazon S3) with Hive or Iceberg tables. It is then processed with AWS Glue and queried using Amazon Athena.
- When the guidance is deployed using a data warehouse, events are ingested from Amazon Kinesis Data Streams into Amazon Redshift in a serverless configuration. Amazon Redshift includes processing and querying capabilities for your data.
Conclusion
Gaming companies of all sizes benefit from understanding their players and games at a deeper level through analyzing their data. Whether you’re processing real-time player interactions or analyzing day-to-day gameplay patterns, the updated Guidance for Game Analytics Pipeline provides the visibility and flexibility to better understand your players.
You can get started with the Guidance for Game Analytics Pipeline by following the Get Started guide. The source code for the pipeline is available in the AWS Solution Guidance GitHub Repository. For more information read our Guidance for Game Analytics Pipeline on AWS. If you have any specific questions about the solution or need help creating an analytics action plan, contact an AWS Representative.
Further reading
Author: Nathan Yee