

Making traffic lights more efficient with Amazon Rekognition
Amazon Rekognition supports adding image and video analysis to your applications… A Python function uses CV2 to split the video footage into image frames… The function makes a call to Amazon Rekognition when the image frames are completed… Amazon Rekognition image operations place bound…
State and local agencies spend approximately $1.23 billion annually to operate and maintain signalized traffic intersections. On the other end, traffic congestion at intersections costs drivers about $22 billion annually. Implementing an artificial intelligence (AI)-powered detection-based solution can significantly mitigate congestion at intersections and reduce operation and maintenance costs. In this blog post, we show you how Amazon Rekognition (an AI technology) can mitigate congestion at traffic intersections and reduce operations and maintenance costs.
State and local agencies rely on traffic signals to facilitate the safe flow of traffic involving cars, pedestrians, and other users. There are two main types of traffic lights: fixed and dynamic. Fixed traffic lights are timed lights controlled by electro-mechanical signals that switch and hold the lights based on a set period of time. Dynamic traffic lights are designed to adjust based on traffic conditions by using detectors both underneath the surface of the road and above the traffic light. However, as population continues to rise, there are more cars, bikes, and pedestrians using the streets. This increase in road users can negatively impact the efficiency of either of the two traffic systems.
Solution overview
At a high level, our solution uses Amazon Rekognition to automatically detect objects (cars, bikes, and so on) and scenes at an intersection. After detection, Amazon Rekognition creates bounding boxes around each object (such as a vehicle) and calculates the distance between each object (in this scenario, that would be the distance between vehicles detected at an intersection). Results from the calculated distances are used programmatically to stop or allow the flow of traffic, thus reducing congestion. All of this happens without human intervention.
Prerequisties
The proposed solution can be implemented in a personal AWS environment using the code that we provide. However, there are a few prerequisites that must in place. Before running the labs in this post, ensure you have the following:
- An AWS account. Create one if necessary.
- The appropriate AWS Identity and Access Management (IAM) permissions to access services used in the lab. If this is your first time setting up an AWS account, see the IAM documentation for information about configuring IAM.
- A SageMaker Studio Notebook. Create one if necessary.
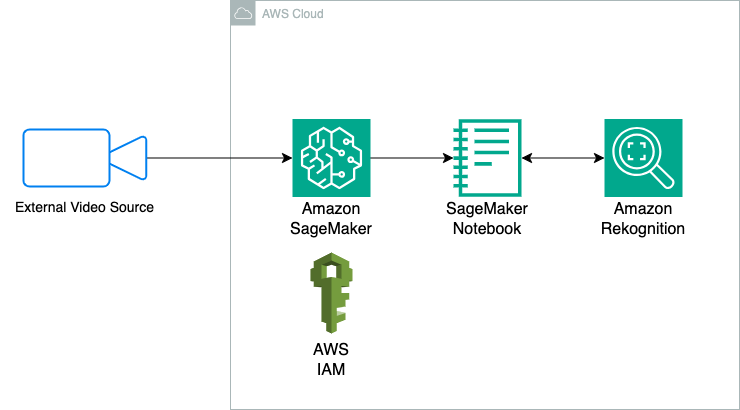
Solution architecture
The following diagram illustrates the lab’s architecture:

This solution uses the following AI and machine learning (AI/ML), serverless, and managed technologies:
- Amazon SageMaker, a fully managed machine learning service that enables data scientists and developers to build, train and deploy machine learning applications.
- Amazon Rekognition supports adding image and video analysis to your applications.
- IAM grants authentication and authorization that allows resources in the solution to talk to each other.
To recap how the solution works
- Traffic intersection video footage is uploaded to your SageMaker environment from an external device.
- A Python function uses CV2 to split the video footage into image frames.
- The function makes a call to Amazon Rekognition when the image frames are completed.
- Amazon Rekognition analyzes each frame and creates bounding boxes around each vehicle it detects.
- The function counts the bounding boxes and changes the traffic signal based on the number of cars it detects using pre-defined logic.
Solution walkthrough
Now, let’s walk through implementing the solution.
Configure SageMaker:
- Choose Domains in the navigation pane, and then select your domain name.
- Find and copy the SageMaker Execution Role.

- Go to the IAM console and choose Roles in the navigation pane and paste the SageMaker Execution Role you copied in the preceding step.

Enable SageMaker to interact with Amazon Rekognition:
Next, enable SageMaker to interact with Amazon Rekognition using the SageMaker execution role.
- In the SageMaker console, select your SageMaker execution role and choose Add permission and then choose Attach policies.
- In the search bar, enter and select AmazonRekognitionFullAccess Policy. See the following figure.

With the IAM permissions configured, you can run the notebook in SageMaker with access to Amazon Rekognition for the video analysis.
Download the Rekognition Notebook and traffic intersection data to your local environment. On the Amazon Sagemaker Studio, upload the notebook and data you downloaded.
Code walkthrough:
This lab uses OpenCv and Boto3 to prepare the SageMaker environment. OpenCv is an open source library with over 250 algorithms for computer vision analysis. Boto3 is the AWS SDK for Python that helps you to integrate AWS services with applications or scripts written in Python.
- First, we import OpenCv and Boto3 package. The next cell of codes builds a function for analyzing the video. We will walk through key components of the function. The function starts by creating a frame for the video to be analyzed.

- The frame is written to a new video writer file with an MP4 extension. The function also loops through the file and, if the video doesn’t have a frame, the function converts it to a JPEG file. Then the code define and identify traffic lanes using bounding boxes. Amazon Rekognition image operations place bounding boxes around images detected for later analysis.

- The function captures the video frame and sends it to Amazon Rekognition to analyze images in the video using the bounding boxes. The model uses bounding boxes to detect and classify captured images (cars, pedestrians, and so on) in the video. The code then detects whether a car is in the video sent to Amazon Rekognition. A bounding box is generated for each car detected in the video.

- The size and position of the car is computed to accurately detect its position. After computing the size and position of the car, the model checks whether the car is in a detected lane. After determining whether there are cars in one of the detected lanes, the model counts the numbers of detected cars in the lane.

- The results from detecting and computing the size, position and numbers of cars in a lane are written to a new file in the rest of the function.

- Writing the outputs to a new file, a few geometry computations are done to determine the details of detected objects. For example, polygons are used to determine the size of objects.

- With the function completely built, the next step is running the function and with a minimum confidence sore of 95% using a test video.

- The last line of codes allow you to download the video from the directory in SageMaker to check the results and confidence level of the output.







Costs
The logic behind our cost estimates is put at $6,000 per intersection with the assumption one frame per second using four cameras with a single SageMaker notebook for each intersection. One important callout is that not every intersection is a 4-way intersection. Implementing this solution on more populated traffic areas will increase the overall flow of traffic.
Cost breakdown and details
| Service | Description | First month cost | First 12 months cost |
| Amazon SageMaker Studio notebooks | · Instance name: ml.t3.medium · Number of data scientists: 1 · Number of Studio notebook instances per data scientist: 1 · Studio notebook hours per day: 24 · Studio notebook days per month: 30 | $36 | $432 |
| Amazon Rekognition | Number of images processed with labels API calls per month: 345,600 per month | $345.60 | $4,147.20 |
| Amazon Simple Storage Service (Amazon S3) (Standard storage class) | · S3 Standard storage: 4,320 GB per month · PUT, COPY, POST, and LIST requests to S3 Standard per month: 2,592,000 | $112.32 | $1,347.84 |
| Total estimate per year | $5,927.04 |
However, this is an estimate, and you may incur additional costs depending on customization. For additional information on costs, visit the AWS pricing page for the services covered in the solution architecture. If you have questions, reach out to the AWS team for a more technical and focused discussion.
Clean up
Delete all AWS resources created for this solution that are no longer needed to avoid future charges.
Conclusion
This post provides a solution to make traffic lights more efficient using Amazon Rekognition. The solution proposed in this post can mitigate costs, support road safety, and reduce congestion at intersections. All of these make traffic management more efficient. We strongly recommend learning more about how Amazon Rekognition can help accelerate other image recognition and video analysis tasks by visiting the Amazon Rekognition Developer Guide.
About the authors
 Hao Lun Colin Chu is an innovative Solution Architect at AWS, helping partners and customers leverage cutting-edge cloud technologies to solve complex business challenges. With extensive expertise in cloud migrations, modernization, and AI/ML, Colin advises organizations on translating their needs into transformative AWS-powered solutions. Driven by a passion for using technology as a force for good, he is committed to delivering solutions that empower organizations and improve people’s lives. Outside of work, he enjoys playing drum, volleyball and board games!
Hao Lun Colin Chu is an innovative Solution Architect at AWS, helping partners and customers leverage cutting-edge cloud technologies to solve complex business challenges. With extensive expertise in cloud migrations, modernization, and AI/ML, Colin advises organizations on translating their needs into transformative AWS-powered solutions. Driven by a passion for using technology as a force for good, he is committed to delivering solutions that empower organizations and improve people’s lives. Outside of work, he enjoys playing drum, volleyball and board games!
 Joe Wilson is a Solutions Architect at Amazon Web Services supporting nonprofit organizations. He provides technical guidance to nonprofit organizations seeking to securely build, deploy or expand applications in the cloud. He is passionate about leveraging data and technology for social good. Joe background is in data science and international development. Outside work, Joe loves spending time with his family, friends and chatting about innovation and entrepreneurship.
Joe Wilson is a Solutions Architect at Amazon Web Services supporting nonprofit organizations. He provides technical guidance to nonprofit organizations seeking to securely build, deploy or expand applications in the cloud. He is passionate about leveraging data and technology for social good. Joe background is in data science and international development. Outside work, Joe loves spending time with his family, friends and chatting about innovation and entrepreneurship.
Author: Colin Chu