

Maximize Your Game Data Insights with the updated Game Analytics Pipeline
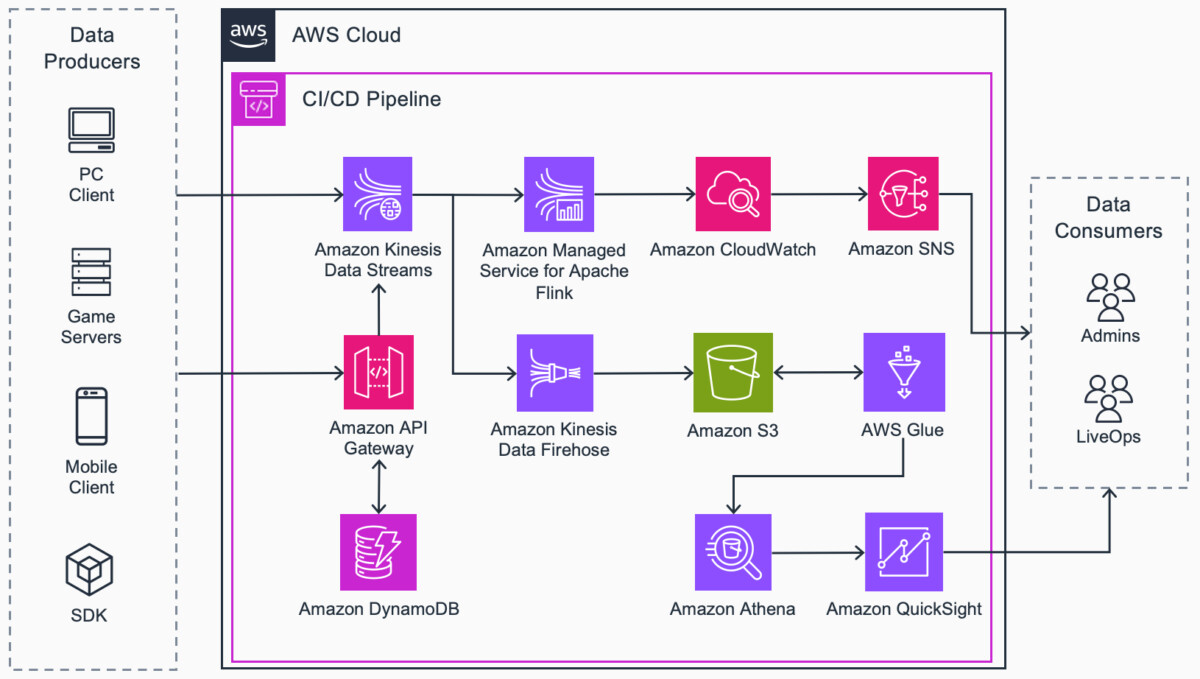
Streaming data is captured from the game with Amazon Kinesis Data Streams… If you want to use an API Proxy, you can register data producers with REST API endpoints with Amazon API Gateway… Game configurations and API access keys are stored in Amazon DynamoDB… Streaming event data is …
In the highly competitive gaming industry, collecting and utilizing data has become a driving factor for game success. Game studios of all sizes have realized the immense value in analyzing player data to drive key business decisions. Additionally, the trend of releasing Games-as-a-Service where revenue is primarily generated from in-app purchases, subscriptions, and other microtransactions, has further increased the importance of understanding your players and game at a deeper level. From increasing player engagement and monetization to detecting fraud and optimizing performance, data analytics has become a vital tool for game developers.
However, many studios, particularly smaller ones, face significant challenges in integrating robust analytics pipelines into their games. These challenges range from a lack of dedicated data scientists or analytics experts on the team to limited bandwidth for managing extra infrastructure. To address these problems, AWS developed the Game Analytics Pipeline (GAP). Originally released in 2021, this solution provided a fully serverless analytics pipeline to automate the collection, storage, processing, and visualization of telemetry, and event data from a wide variety of game data producers, such as players, game servers, and the game backend.
The Updated Game Analytics Pipeline
Today, the GAP solution has been updated, and modernized to provide customers the ability to deploy the latest AWS service, and feature updates, using a DataOps engineering practice for their game analytics requirements. The GAP solution has been codified as an AWS cloud development kit (CDK) application, allowing customers to determine the modules or components that best fit their use case, and deploy only the necessary resources.
With an out-of-the-box DataOps CI/CD pipeline, customers can test and QA their architectural decisions before deploying into production. This modular system allows for additional AWS capabilities, such as AI/ML models, to be integrated into the pipeline to provide valuable insights and recommendations to enhance player experiences. These models can be used to identify fraudulent activity in near real-time, provide player specific in-game purchase promotions, automate LiveOps through AIOps, enable dynamic NPC dialogue through generative AI, and more. In addition to creating a modular solution, the GAP solution has updated library dependencies, bug fixes, and uses the latest AWS Glue engine versions for faster ETL processing. In this blog, we’ll walk through the architecture of the updated game analytics pipeline and how to deploy it.
GAP now provides customers with the flexibility to choose the type of analytics processing they want to do, and how they want to integrate the pipeline into their game. Data processing can be streamed for near-real time metrics or processed in batch to gain insight on historical data. For developers, the AWS SDK can be integrated into your game to collect data. For example, if you’re developing a game in Unity, you can utilize the AWS .NET SDK which supports C#. Alternatively, you can send data through an API Proxy via AWS API Gateway to add an extra layer of security. Details about this can be found in the steps of Figure 1.
Architecture Review
GAP can be broken down into two main components: the analytics pipeline and the DataOps CI/CD pipeline.
Analytics Pipeline

- Data producers send telemetry events to the AWS Cloud.
- Streaming data is captured from the game with Amazon Kinesis Data Streams.
- If you want to use an API Proxy, you can register data producers with REST API endpoints with Amazon API Gateway. Game configurations and API access keys are stored in Amazon DynamoDB.
- Streaming event data is captured and processed by Amazon Managed Service for Apache Flink and custom metrics are published to Amazon CloudWatch.
- The custom metrics can be visualized with CloudWatch Dashboards and CloudWatch alarms can be set to notify developers or take automated actions when thresholds are breached.
- Critical alarm notifications are delivered to data consumers with Amazon Simple Notification Service(Amazon SNS).
- Batched telemetry is processed through Amazon Data Firehose.
- Raw and processed telemetry is stored in Amazon Simple Storage Service(Amazon S3).
- Perform extract, transform, and load (ETL) processes on stored telemetry data with AWS Glue.
- Interactively query and analyze prepared data with Amazon Athena.
- Visualize business intelligence (BI) data with Amazon QuickSight.
DataOps CI/CD Pipeline

- Build and test the codified infrastructure using the AWS Cloud Development Kit(AWS CDK) to synthesize an AWS CloudFormation
- When infrastructure code changes are committed to the AWS CodeCommitrepository, the CI/CD pipeline is initiated.
- Compiled infrastructure assets, such as a Docker container image and CloudFormation templates, are stored in Amazon Elastic Container Registry(Amazon ECR) and Amazon S3.
- The infrastructure is deployed for integration and system testing into the quality assurance (QA) AWS account using the CloudFormation Stack.
- Automated testing scripts are run to verify that the deployed infrastructure is functional inside an AWS CodeBuild
- The tested infrastructure is deployed into the Production (PROD) AWS account using the CloudFormation Stack.
Deployment
Steps to deploy GAP are outlined in the AWS Solution Guidance GitHub Repository found here. If you have any specific questions about the solution or need help creating an analytics action plan, contact your AWS Account Team.
Conclusion
Gaming companies of all sizes benefit from understanding their players and games at a deeper level through analyzing their data. The Game Analytics Pipeline provides a fully serverless analytics pipeline codified into modules using Infrastructure as Code to provide customers an easier way to build the best analytics pipeline for their game. For more information on GAP, see the Guidance for Game Analytics Pipeline on AWS.
Author: Trenton Potgeiter