

Moderate audio and text chats using AWS AI services and LLMs
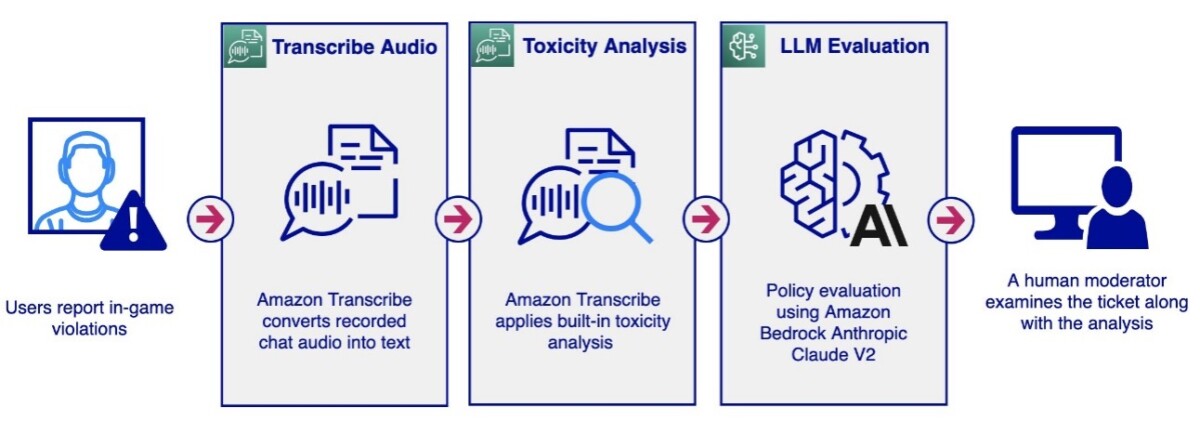
In this post, we introduce solutions that enable audio and text chat moderation using various AWS services, including Amazon Transcribe, Amazon Comprehend, Amazon Bedrock, and Amazon OpenSearch Service… The audio moderation workflow involves the following steps: The workflow begins with rec…
Online gaming and social communities offer voice and text chat functionality for their users to communicate. Although voice and text chat often support friendly banter, it can also lead to problems such as hate speech, cyberbullying, harassment, and scams. Today, many companies rely solely on human moderators to review toxic content. However, verifying violations in chat is time-consuming, error-prone, and challenging to scale.
In this post, we introduce solutions that enable audio and text chat moderation using various AWS services, including Amazon Transcribe, Amazon Comprehend, Amazon Bedrock, and Amazon OpenSearch Service.
Social platforms seek an off-the-shelf moderation solution that is straightforward to initiate, but they also require customization for managing diverse policies. Latency and cost are also critical factors that must be taken into account. By orchestrating toxicity classification with large language models (LLMs) using generative AI, we offer a solution that balances simplicity, latency, cost, and flexibility to satisfy various requirements.
The sample code for this post is available in the GitHub repository.
Audio chat moderation workflow
An audio chat moderation workflow could be initiated by a user reporting other users on a gaming platform for policy violations such as profanity, hate speech, or harassment. This represents a passive approach to audio moderation. The system records all audio conversations without immediate analysis. When a report is received, the workflow retrieves the related audio files and initiates the analysis process. A human moderator then reviews the reported conversation, investigating its content to determine if it violates platform policy.

Alternatively, the workflow could be triggered proactively. For instance, in a social audio chat room, the system could record all conversations and apply analysis.

Both passive and proactive approaches can trigger the following pipeline for audio analysis.
The audio moderation workflow involves the following steps:
- The workflow begins with receiving the audio file and storing it on a Amazon Simple Storage Service (Amazon S3) bucket for Amazon Transcribe to access.
- The Amazon Transcribe
StartTranscriptionJobAPI is invoked with Toxicity Detection enabled. Amazon Transcribe converts the audio into text, providing additional information about toxicity analysis. For more information about toxicity analysis, refer to Flag harmful language in spoken conversations with Amazon Transcribe Toxicity Detection. - If the toxicity analysis returns a toxicity score exceeding a certain threshold (for example, 50%), we can use Knowledge Bases for Amazon Bedrock to evaluate the message against customized policies using LLMs.
- The human moderator receives a detailed audio moderation report highlighting the conversation segments considered toxic and in violation of policy, allowing them to make an informed decision.
The following screenshot shows a sample application displaying toxicity analysis for an audio segment. It includes the original transcription, the results from the Amazon Transcribe toxicity analysis, and the analysis conducted using an Amazon Bedrock knowledge base through the Amazon Bedrock Anthropic Claude V2 model.
The LLM analysis provides a violation result (Y or N) and explains the rationale behind the model’s decision regarding policy violation. Furthermore, the knowledge base includes the referenced policy documents used by the evaluation, providing moderators with additional context.

Amazon Transcribe Toxicity Detection
Amazon Transcribe is an automatic speech recognition (ASR) service that makes it straightforward for developers to add speech-to-text capability to their applications. The audio moderation workflow uses Amazon Transcribe Toxicity Detection, which is a machine learning (ML)-powered capability that uses audio and text-based cues to identify and classify voice-based toxic content across seven categories, including sexual harassment, hate speech, threats, abuse, profanity, insults, and graphic language. In addition to analyzing text, Toxicity Detection uses speech cues such as tones and pitch to identify toxic intent in speech.
The audio moderation workflow activates the LLM’s policy evaluation only when the toxicity analysis exceeds a set threshold. This approach reduces latency and optimizes costs by selectively applying LLMs, filtering out a significant portion of the traffic.
Use LLM prompt engineering to accommodate customized policies
The pre-trained Toxicity Detection models from Amazon Transcribe and Amazon Comprehend provide a broad toxicity taxonomy, commonly used by social platforms for moderating user-generated content in audio and text formats. Although these pre-trained models efficiently detect issues with low latency, you may need a solution to detect violations against your specific company or business domain policies, which the pre-trained models alone can’t achieve.
Additionally, detecting violations in contextual conversations, such as identifying child sexual grooming conversations, requires a customizable solution that involves considering the chat messages and context outside of it, such as user’s age, gender, and conversation history. This is where LLMs can offer the flexibility needed to extend these requirements.
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies. These solutions use Anthropic Claude v2 from Amazon Bedrock to moderate audio transcriptions and text chat messages using a flexible prompt template, as outlined in the following code:
The template contains placeholders for the policy description, the chat message, and additional rules that requires moderation. The Anthropic Claude V2 model delivers responses in the instructed format (Y or N), along with an analysis explaining why it thinks the message violates the policy. This approach allows you to define flexible moderation categories and articulate your policies in human language.
The traditional method of training an in-house classification model involves cumbersome processes such as data annotation, training, testing, and model deployment, requiring the expertise of data scientists and ML engineers. LLMs, in contrast, offer a high degree of flexibility. Business users can modify prompts in human language, leading to enhanced efficiency and reduced iteration cycles in ML model training.
Amazon Bedrock knowledge bases
Although prompt engineering is efficient for customizing policies, injecting lengthy policies and rules directly into LLM prompts for each message may introduce latency and increase cost. To address this, we use Amazon Bedrock knowledge bases as a managed Retrieval Augmented Generation (RAG) system. This enables you to manage the policy document flexibly, allowing the workflow to retrieve only the relevant policy segments for each input message. This minimizes the number of tokens sent to the LLMs for analysis.
You can use the AWS Management Console to upload the policy documents to an S3 bucket and then index the documents to a vector database for efficient retrieval. The following is a conceptual workflow managed by an Amazon Bedrock knowledge base that retrieves documents from Amazon S3, splits the text into chunks, and invokes the Amazon Bedrock Titan text embeddings model to convert the text chunks into vectors, which are then stored in the vector database.

In this solution, we use Amazon OpenSearch Service as the vector store. OpenSearch is a scalable, flexible, and extensible open source software suite for search, analytics, security monitoring, and observability applications, licensed under the Apache 2.0 license. OpenSearch Service is a fully managed service that makes it straightforward to deploy, scale, and operate OpenSearch in the AWS Cloud.
After the document is indexed in OpenSearch Service, the audio and text moderation workflow sends chat messages, triggering the following query flow for customized policy evaluation.

The process is similar to the initiation workflow. First, the text message is converted to text embeddings using the Amazon Bedrock Titan Text Embedding API. These embeddings are then used to perform a vector search against the OpenSearch Service database, which has already been populated with document embeddings. The database returns policy chunks with the highest matching score, relevant to the input text message. We then compose prompts containing both the input chat message and the policy segment, which are sent to Anthropic Claude V2 for evaluation. The LLM model returns an analysis result based on the prompt instructions.
For detailed instructions on how to create a new instance with your policy document in an Amazon Bedrock knowledge base, refer to Knowledge Bases now delivers fully managed RAG experience in Amazon Bedrock.
Text chat moderation workflow
The text chat moderation workflow follows a similar pattern to audio moderation, but it uses Amazon Comprehend toxicity analysis, which is tailored for text moderation. The sample app supports an interface for uploading bulk text files in CSV or TXT format and provides a single-message interface for quick testing. The following diagram illustrates the workflow.

The text moderation workflow involves the following steps:
- The user uploads a text file to an S3 bucket.
- Amazon Comprehend toxicity analysis is applied to the text message.
- If the toxicity analysis returns a toxicity score exceeding a certain threshold (for example, 50%), we use an Amazon Bedrock knowledge base to evaluate the message against customized policies using the Anthropic Claude V2 LLM.
- A policy evaluation report is sent to the human moderator.
Amazon Comprehend toxicity analysis
In the text moderation workflow, we use Amazon Comprehend toxicity analysis to assess the toxicity level of the text messages. Amazon Comprehend is a natural language processing (NLP) service that uses ML to uncover valuable insights and connections in text. The Amazon Comprehend toxicity detection API assigns an overall toxicity score to text content, ranging from 0–1, indicating the likelihood of it being toxic. It also categorizes text into the following categories and provides a confidence score for each: hate_speech, graphic, harrassement_or_abuse, sexual, violence_or_threat, insult, and profanity.
In this text moderation workflow, Amazon Comprehend toxicity analysis plays a crucial role in identifying whether the incoming text message contains toxic content. Similar to the audio moderation workflow, it includes a condition to activate the downstream LLM policy evaluation only when the toxicity analysis returns a score exceeding a predefined threshold. This optimization helps reduce overall latency and cost associated with LLM analysis.
Summary
In this post, we introduced solutions for audio and text chat moderation using AWS services, including Amazon Transcribe, Amazon Comprehend, Amazon Bedrock, and OpenSearch Service. These solutions use pre-trained models for toxicity analysis and are orchestrated with generative AI LLMs to achieve the optimal balance in accuracy, latency, and cost. They also empower you to flexibly define your own policies.
You can experience the sample app by following the instructions in the GitHub repo.
About the author
 Lana Zhang is a Senior Solutions Architect at AWS WWSO AI Services team, specializing in AI and ML for Content Moderation, Computer Vision, Natural Language Processing and Generative AI. With her expertise, she is dedicated to promoting AWS AI/ML solutions and assisting customers in transforming their business solutions across diverse industries, including social media, gaming, e-commerce, media, advertising & marketing.
Lana Zhang is a Senior Solutions Architect at AWS WWSO AI Services team, specializing in AI and ML for Content Moderation, Computer Vision, Natural Language Processing and Generative AI. With her expertise, she is dedicated to promoting AWS AI/ML solutions and assisting customers in transforming their business solutions across diverse industries, including social media, gaming, e-commerce, media, advertising & marketing.
Author: Lana Zhang