

Multimodal evaluators: MLLM-as-a-judge for image-to-text tasks in Strands Evals
If you’re building visual shopping, image or document understanding, or chart analysis, you need a way to verify whether your model’s response is actually grounded in the source image… A text-only evaluator cannot tell you whether a caption faithfully describes an image, whether an extracted i…
If you’re building visual shopping, image or document understanding, or chart analysis, you need a way to verify whether your model’s response is actually grounded in the source image. A text-only evaluator cannot tell you whether a caption faithfully describes an image, whether an extracted invoice total matches the document, or whether a screen summary hallucinated a button that was never on the page. Gartner predicts that by 2030, 80% of enterprise software will be multimodal, up from less than 10% in 2024. Without automated multimodal evaluation, you’re stuck between expensive human review and unreliable text-only proxies.
Today, we’re announcing four new multimodal large language model (MLLM)-as-a-Judge evaluators for image-to-text tasks in Strands Evals software development kit (SDK): Overall Quality, Correctness, Faithfulness, and Instruction Following. Each evaluator scores image-to-text outputs against the source image. The evaluator sends the image directly to a multimodal judge model, alongside the query, the response, and (optionally) a reference answer. The judge returns a score grounded in the image, together with a reasoning string you can use for debugging. You can use these evaluators as drop-in replacements for text-only judges in your existing Strands Evals Case → Experiment → Report workflow, and plug them into continuous integration (CI) to catch visual hallucinations, factual errors, and instruction violations automatically.
In this post, you will learn how to:
- Set up the four multimodal evaluators and run them on an image-to-text task.
- Switch between reference-based and reference-free evaluation with the same evaluator.
- Write a custom multimodal rubric for domain-specific criteria.
- Choose a judge model on Amazon Bedrock that balances accuracy, cost, and latency.
- Apply prompt-design choices that improved judge-to-human alignment in our experiments.
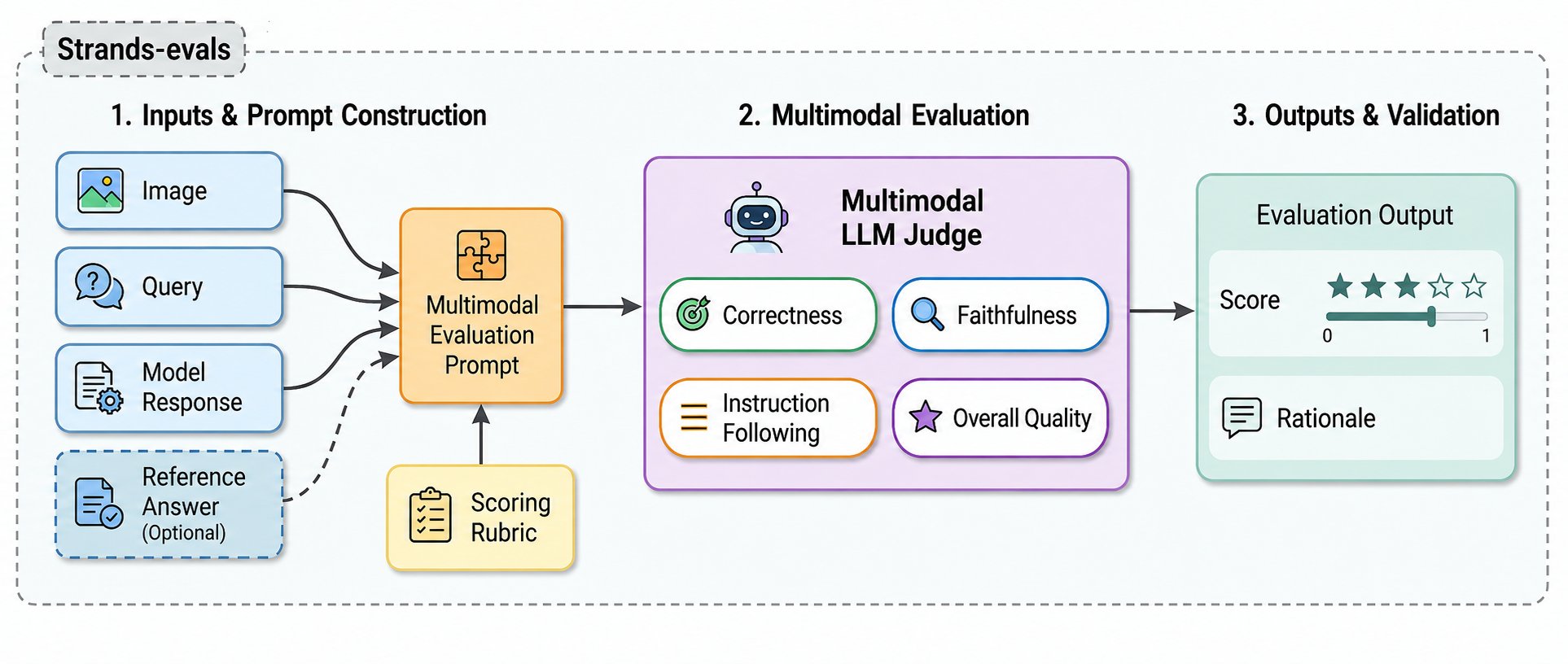
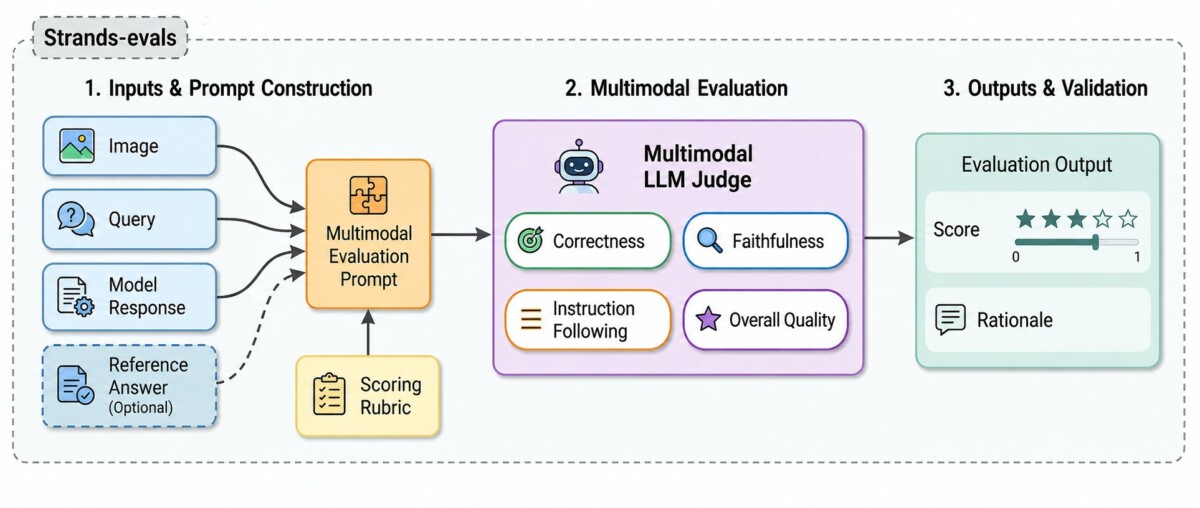
Figure 1: Overview of the multimodal judge framework. Given an image (or document image), a textual query, and a model-generated response, the framework constructs a multimodal evaluation prompt, applies an MLLM-based judge, and returns a score (Likert 1-5 or binary) along with reasoning. The framework supports both reference-based and reference-free evaluation, and integrates with Strands Evals for case management and reporting.
Prerequisites
To follow the walkthrough in this post, you need:
- Python 3.10 or later installed in your environment.
- pip install
strands-agents-evalsfor the evaluators, and pip installstrands-agentsfor the target agent used in the walkthrough. - An AWS account with access to Amazon Bedrock.
- AWS credentials configured locally (for example, via
aws configureor an AWS Identity and Access Management (AWS IAM) role) with Amazon BedrockInvokeModelpermission for the judge model. - Familiarity with the Strands Evals
Case→Experiment→Reportworkflow. If you are new to Strands Evals, see the Strands Evals launch blog post for a quick tour.
Why text-only judges miss image-grounded failures
Suppose you’ve shipped a model that reads invoices, summarizes dashboards, or narrates screenshots. Running a text-only LLM-as-a-Judge over the response gets you some signal (the writing is fluent, the structure is clean), but it misses exactly the failures that matter:
- The model confidently names a chart trend that the chart doesn’t actually show.
- It hallucinates a product, a label, or a person who isn’t in the picture.
- It answers the wrong question, or answers the right one in the wrong format.
A text-only judge reads the output and approves it without verifying the image. The ground truth lives in the image, and the judge never sees it.
Even when you do get a low score from a holistic “rate overall quality” judge, the score alone doesn’t tell you what broke. The failure could be a factual error, an invented detail, or an ignored instruction. These three failure modes require three different fixes, so collapsing them into one score makes debugging harder than it needs to be.
Four evaluators for image-to-text tasks
The four evaluators target the most widely used multimodal category. The input is an image (or document image) together with text, and the output is text. This category covers image captioning, visual question answering, chart and infographic interpretation, document field extraction, OCR, and screenshot summarization. The table below summarizes what each of the four new evaluators catches.
| Evaluator | Score | Core question | What it catches | |
| 1 | Overall Quality | Likert 1-5 | How good is the response overall? | Poor relevance, inaccuracy, shallow answers, lack of comprehensiveness |
| 2 | Correctness | Binary | Is the response factually correct and complete given the image and query? | Factual errors, wrong attributes, counts, positions, omissions |
| 3 | Faithfulness | Binary | Is the response grounded in the image without hallucinations? | Invented objects, unsupported inferences, external-knowledge leakage |
| 4 | Instruction Following | Binary | Does the response adhere to the query’s constraints? | Format violations, wrong counts, off-topic content, ignored scope |
Every evaluator supports two modes. Reference-based mode compares the response against a gold answer and is useful when you have labeled test sets. Reference-free mode judges from the image alone and is the only option when the system runs on live images with no ground truth available.
End-to-end walkthrough: evaluating a chart-reading task
To make the API concrete, you’ll walk through a single Case. The input is a bar chart of average revenue per paying streaming membership by region (U.S./Canada, EMEA, Asia Pacific, Latin America). The system under test is a simple vision agent that answers a narrow question about the chart. You run the four multimodal evaluators in the same Experiment. They share a common MultimodalOutputEvaluator base class and accept images through ImageData.
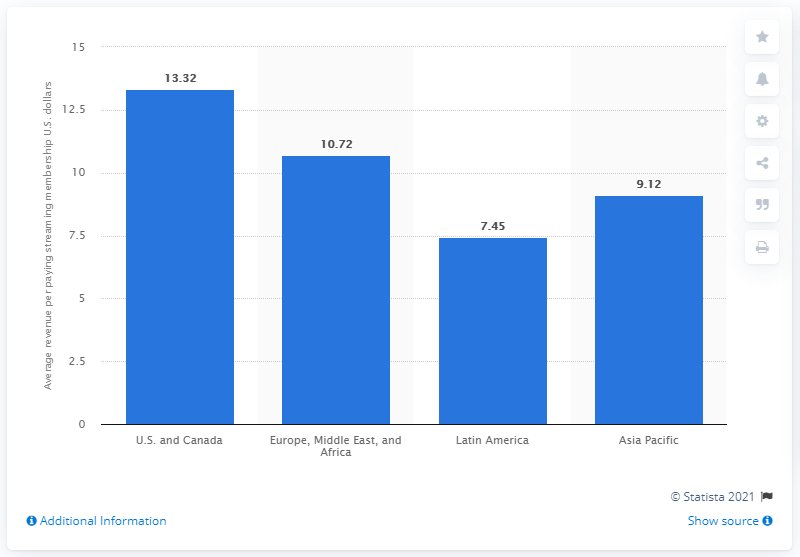
Figure 2: Average revenue per paying streaming membership, by region (Statista). The system under test is asked to answer a grounded question about this chart.
Step 1. Define the Case and evaluators. The Case wraps the image and instruction in a MultimodalInput, and providing expected_output activates reference-based judging for the evaluators that support it.
Step 2. Wire up the task and run the experiment. The task function receives each Case, runs the vision model on the image plus instruction, and returns the response string to be evaluated.
Because each Case above carries a MultimodalInput with media, the four evaluators include the image in the judge prompt. To ablate whether the image modality is contributing meaningfully on your own data, swap the MultimodalInput for a plain-string input (for example, a text description of the image) and rerun. The same evaluator scores from text alone.
Step 3. Inspect the Report. Each Report contains per-case scores, test_passes, and reasons:
Running on the chart above produces the following transcript:
Two things to notice. First, every evaluator returns a reason string in addition to a score, which is critical for debugging. When a run fails in CI, you can see why without re-running. Second, the same Case was scored by four independent judges (one Likert, three binary) in a single Experiment, so your workflow is identical to single-evaluator runs in text-only Strands Evals.
Custom rubrics. For domain-specific criteria, the base class accepts an arbitrary rubric string:
What we learned: three design questions
Q1. Does the judge need to see the image?
A natural question: can a text-only LLM judge, given a detailed auto-generated image description in place of the image, substitute for a multimodal judge? We compared MLLM-as-a-Judge (image plus text) against LLM-as-a-Judge with long and short image descriptions feeding into the same prompt.
Takeaway: the multimodal judge aligned more closely with human scores than either text-only variant. Once you count the extra LLM call to generate the image description, the text-only route is not meaningfully cheaper or faster either. If you have a multimodal judge available, use it directly.
Q2. Which model on Amazon Bedrock to use as the judge?
We evaluated several MLLMs available on Amazon Bedrock as judges and used alignment with human scores, per-query cost, and latency to pick a default. Anthropic Claude Sonnet 4.6 on Amazon Bedrock offered the best accuracy-to-cost trade-off across our runs, and we use it as the default judge model for the multimodal evaluators. Two broader observations also held up consistently across the models we tried. First, larger reasoning-capable models were more reliable as judges than smaller ones. Second, within the capable tier, premium-priced models did not gain measurable accuracy over mid-tier ones for this task.
Recommended default: Anthropic Claude Sonnet 4.6.
Q3. Which prompt-design choices actually matter?
We ablated several prompt-design axes against our final recommended prompt. The takeaways that generalized across our runs:
- Ask the judge to reason before scoring. This was the single most impactful choice we measured. Score-only output is cheaper and more self-consistent, but alignment with human scores drops noticeably. If you only remember one thing, it is this.
- Include a few diverse calibration examples. Alignment improved monotonically as we moved from zero-shot to a handful of examples.
- Use a fine-grained, multi-dimensional rubric (e.g., visual accuracy, instruction adherence, completeness, coherence) instead of a single holistic prompt. Separating dimensions prevents a single vague score from absorbing distinct failure modes.
Bonus: reference-based vs. reference-free
Injecting a gold reference answer into the judge prompt helps content-grounded evaluators. Overall Quality, Correctness, and Faithfulness aligned more closely with human judgment when a reference was available. Instruction Following went the other way. Adding reference content distracted the judge from checking structural constraints (format, scope, order, count) that are determined by the query and response alone.
As a general guideline: use references for content-grounded metrics, and skip them for structural metrics like instruction following.
Best practices
Based on our experiments and integration work, we recommend:
- Default to
MultimodalOverallQualityEvaluatorfor quick sanity checks, then add targeted binary evaluators (Correctness, Faithfulness, Instruction Following) as you diagnose specific failure modes. - Start with Claude Sonnet 4.6 as the judge, and drop to smaller reasoning-capable MLLMs on Amazon Bedrock only if cost or latency dominates your constraints. Avoid small models for judgment.
- Keep the reason+score output format. Score-only is tempting for cost, but alignment with human scores drops noticeably.
- Use references for correctness, faithfulness, and overall quality if available. Skip them for instruction following.
Conclusion
The four new MLLM-as-a-Judge evaluators in Strands Evals move image-to-text evaluation from expensive human review or unreliable text-only proxies to automated, image-grounded scoring. Overall Quality, Correctness, Faithfulness, and Instruction Following each target a distinct failure mode, support both reference-based and reference-free evaluation, and return diagnostic reasoning alongside every score. On our held-out validation split, the four evaluators aligned well with human judgment across diverse image domains. This is the first step toward broader multimodal evaluation in Strands Evals. Future work includes step-level evaluation for multimodal tool use and agent trajectories, and additional modality combinations such as text-to-image, video-to-text, and audio-to-text.
Start evaluating your image-to-text agents today. Install Strands Evals with the following command:
Then explore the resources below:
- Read the Strands Evals documentation for an end-to-end overview of the
Case→Experiment→Reportworkflow. - See the multimodal evaluator reference for the full API, including
MultimodalInput,ImageData, the built-in rubrics, and the four convenience subclasses. - Try the multimodal evaluator example in the Strands Agents docs repository.
- Share your feedback and feature requests in GitHub Issues.
About the authors
Author: Sangmin Woo