

Node problem detection and recovery for AWS Neuron nodes within Amazon EKS clusters
In the post, we introduce the AWS Neuron node problem detector and recovery DaemonSet for AWS Trainium and AWS Inferentia on Amazon Elastic Kubernetes Service (Amazon EKS)… This component can quickly detect rare occurrences of issues when Neuron devices fail by tailing monitoring logs… It mark…
Implementing hardware resiliency in your training infrastructure is crucial to mitigating risks and enabling uninterrupted model training. By implementing features such as proactive health monitoring and automated recovery mechanisms, organizations can create a fault-tolerant environment capable of handling hardware failures or other issues without compromising the integrity of the training process.
In the post, we introduce the AWS Neuron node problem detector and recovery DaemonSet for AWS Trainium and AWS Inferentia on Amazon Elastic Kubernetes Service (Amazon EKS). This component can quickly detect rare occurrences of issues when Neuron devices fail by tailing monitoring logs. It marks the worker nodes in a defective Neuron device as unhealthy, and promptly replaces them with new worker nodes. By accelerating the speed of issue detection and remediation, it increases the reliability of your ML training and reduces the wasted time and cost due to hardware failure.
This solution is applicable if you’re using managed nodes or self-managed node groups (which use Amazon EC2 Auto Scaling groups) on Amazon EKS. At the time of writing this post, automatic recovery of nodes provisioned by Karpenter is not yet supported.
Solution overview
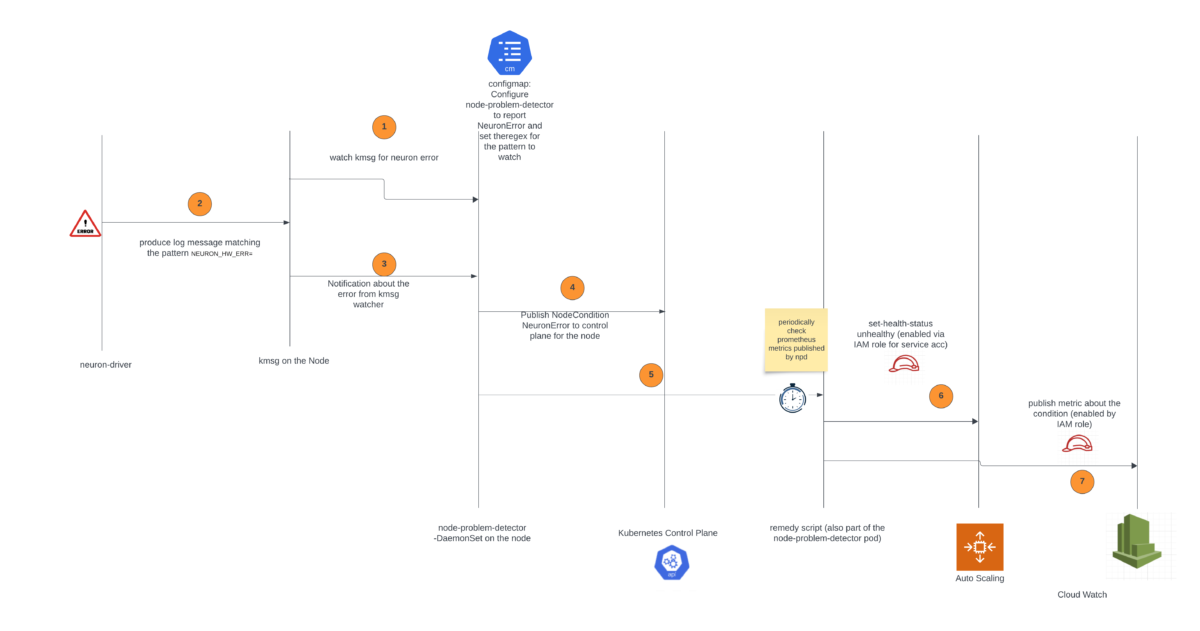
The solution is based on the node problem detector and recovery DaemonSet, a powerful tool designed to automatically detect and report various node-level problems in a Kubernetes cluster.
The node problem detector component will continuously monitor the kernel message (kmsg) logs on the worker nodes. If it detects error messages specifically related to the Neuron device (which is the Trainium or AWS Inferentia chip), it will change NodeCondition to NeuronHasError on the Kubernetes API server.
The node recovery agent is a separate component that periodically checks the Prometheus metrics exposed by the node problem detector. When it finds a node condition indicating an issue with the Neuron device, it will take automated actions. First, it will mark the affected instance in the relevant Auto Scaling group as unhealthy, which will invoke the Auto Scaling group to stop the instance and launch a replacement. Additionally, the node recovery agent will publish Amazon CloudWatch metrics for users to monitor and alert on these events.
The following diagram illustrates the solution architecture and workflow.

In the following walkthrough, we create an EKS cluster with Trn1 worker nodes, deploy the Neuron plugin for the node problem detector, and inject an error message into the node. We then observe the failing node being stopped and replaced with a new one, and find a metric in CloudWatch indicating the error.
Prerequisites
Before you start, make sure you have installed the following tools on your machine:
- The latest version of the AWS Command Line Interface (AWS CLI)
- eksctl
- kubectl
- Terraform
- The Session Manager plugin
Deploy the node problem detection and recovery plugin
Complete the following steps to configure the node problem detection and recovery plugin:
- Create an EKS cluster using the data on an EKS Terraform module:
- Install the required AWS Identity and Access Management (IAM) role for the service account and the node problem detector plugin.
- Create a policy as shown below. Update the
Resourcekey value to match your node group ARN that contains the Trainium and AWS Inferentia nodes, and update theec2:ResourceTag/aws:autoscaling:groupNamekey value to match the Auto Scaling group name.
You can get these values from the Amazon EKS console. Choose Clusters in the navigation pane, open the trainium-inferentia cluster, choose Node groups, and locate your node group.
This component will be installed as a DaemonSet in your EKS cluster.
The container images in the Kubernetes manifests are stored in public repository such as registry.k8s.io and public.ecr.aws. For production environments, it’s recommended that customers limit external dependencies that impact these areas and host container images in a private registry and sync from images public repositories. For detailed implementation, please refer to the blog post: Announcing pull through cache for registry.k8s.io in Amazon Elastic Container Registry.
By default, the node problem detector will not take any actions on failed node. If you would like the EC2 instance to be terminated automatically by the agent, update the DaemonSet as follows:
kubectl edit -n neuron-healthcheck-system ds/node-problem-detector
...
env:
- name: ENABLE_RECOVERY
value: "true"Test the node problem detector and recovery solution
After the plugin is installed, you can see Neuron conditions show up by running kubectl describe node. We simulate a device error by injecting error logs in the instance:
Around 2 minutes later, you can see that the error has been identified:
kubectl describe node ip-100-64-58-151.us-east-2.compute.internal | grep 'Conditions:' -A7Now that the error has been detected by the node problem detector, and the recovery agent has automatically taken the action to set the node as unhealthy, Amazon EKS will cordon the node and evict the pods on the node:
You can open the CloudWatch console and verify the metric for NeuronHealthCheck. You can see the CloudWatch NeuronHasError_DMA_ERROR metric has the value 1.

After replacement, you can see a new worker node has been created:
Let’s look at a real-world scenario, in which you’re running a distributed training job, using an MPI operator as outlined in Llama-2 on Trainium, and there is an irrecoverable Neuron error in one of the nodes. Before the plugin is deployed, the training job will become stuck, resulting in wasted time and computational costs. With the plugin deployed, the node problem detector will proactively remove the problem node from the cluster. In the training scripts, it saves checkpoints periodically so that the training will resume from the previous checkpoint.
The following screenshot shows example logs from a distributed training job.
The training has been started. (You can ignore loss=nan for now; it’s a known issue and will be removed. For immediate use, refer to the reduced_train_loss metric.)

The following screenshot shows the checkpoint created at step 77.

Training stopped after one of the nodes has a problem at step 86. The error was injected manually for testing.

After the faulty node was detected and replaced by the Neuron plugin for node problem and recovery, the training process resumed at step 77, which was the last checkpoint.


Although Auto Scaling groups will stop unhealthy nodes, they may encounter issues preventing the launch of replacement nodes. In such cases, training jobs will stall and require manual intervention. However, the stopped node will not incur further charges on the associated EC2 instance.
If you want to take custom actions in addition to stopping instances, you can create CloudWatch alarms watching the metrics NeuronHasError_DMA_ERROR,NeuronHasError_HANG_ON_COLLECTIVES, NeuronHasError_HBM_UNCORRECTABLE_ERROR, NeuronHasError_SRAM_UNCORRECTABLE_ERROR, and NeuronHasError_NC_UNCORRECTABLE_ERROR, and use a CloudWatch Metrics Insights query like SELECT AVG(NeuronHasError_DMA_ERROR) FROM NeuronHealthCheck to sum up these values to evaluate the alarms. The following screenshots show an example.

Clean up
To clean up all the provisioned resources for this post, run the cleanup script:
Conclusion
In this post, we showed how the Neuron problem detector and recovery DaemonSet for Amazon EKS works for EC2 instances powered by Trainium and AWS Inferentia. If you’re running Neuron based EC2 instances and using managed nodes or self-managed node groups, you can deploy the detector and recovery DaemonSet in your EKS cluster and benefit from improved reliability and fault tolerance of your machine learning training workloads in the event of node failure.
About the authors
 Harish Rao is a senior solutions architect at AWS, specializing in large-scale distributed AI training and inference. He empowers customers to harness the power of AI to drive innovation and solve complex challenges. Outside of work, Harish embraces an active lifestyle, enjoying the tranquility of hiking, the intensity of racquetball, and the mental clarity of mindfulness practices.
Harish Rao is a senior solutions architect at AWS, specializing in large-scale distributed AI training and inference. He empowers customers to harness the power of AI to drive innovation and solve complex challenges. Outside of work, Harish embraces an active lifestyle, enjoying the tranquility of hiking, the intensity of racquetball, and the mental clarity of mindfulness practices.
 Ziwen Ning is a software development engineer at AWS. He currently focuses on enhancing the AI/ML experience through the integration of AWS Neuron with containerized environments and Kubernetes. In his free time, he enjoys challenging himself with badminton, swimming and other various sports, and immersing himself in music.
Ziwen Ning is a software development engineer at AWS. He currently focuses on enhancing the AI/ML experience through the integration of AWS Neuron with containerized environments and Kubernetes. In his free time, he enjoys challenging himself with badminton, swimming and other various sports, and immersing himself in music.
 Geeta Gharpure is a senior software developer on the Annapurna ML engineering team. She is focused on running large scale AI/ML workloads on Kubernetes. She lives in Sunnyvale, CA and enjoys listening to Audible in her free time.
Geeta Gharpure is a senior software developer on the Annapurna ML engineering team. She is focused on running large scale AI/ML workloads on Kubernetes. She lives in Sunnyvale, CA and enjoys listening to Audible in her free time.
 Darren Lin is a Cloud Native Specialist Solutions Architect at AWS who focuses on domains such as Linux, Kubernetes, Container, Observability, and Open Source Technologies. In his spare time, he likes to work out and have fun with his family.
Darren Lin is a Cloud Native Specialist Solutions Architect at AWS who focuses on domains such as Linux, Kubernetes, Container, Observability, and Open Source Technologies. In his spare time, he likes to work out and have fun with his family.
Author: Darren Lin