

Operationalize generative AI applications on AWS: Part I – Overview of LLMOps solution
With the rising popularity of generative artificial intelligence (AI), companies are exploring foundation models (FMs) and realizing the immediate benefit they provide to their business… FMs are large machine learning models that are pre-trained on vast amounts of data, which can perform many task…
With the rising popularity of generative artificial intelligence (AI), companies are exploring foundation models (FMs) and realizing the immediate benefit they provide to their business. FMs are large machine learning models that are pre-trained on vast amounts of data, which can perform many tasks such as text, code, and generate images. As more companies train unique models or fine tune FMs, and deploy applications powered by these models, the need to operationalize model processes and follow best practices to optimize speed, cost, and quality has become a priority.
Large language models (LLMs) are a class of FMs that focus on language-based tasks such as summarization, text generation, classification, Q&A, and more. Large Language Model Operations (LLMOps), a subset of Foundation Model Operations (FMOps), focuses on the processes, techniques, and best practices used for the operational management of LLMs. Using LLMOps improves the efficiency in which models are developed and enables scalability to manage multiple models. FMOps stems from the concept of Machine Learning Operations (MLOps), which is the combination of people, processes, and technology to deliver machine learning solutions efficiently into production. It takes the MLOps methodology and adds the additional skills, processes, and technologies needed to operationalize generative AI models and applications.
This is part 1 of a 3-part blog series where we will cover LLMOps in detail for the games industry. We will dive into use cases, services, and code needed to implement LLMOps on AWS. This blog gives a primer on LLMOps, high-level solution design and specific use cases in the games industry.
Use cases for LLMOps in Games
Let’s explore some use cases in the games industry to see how customers are leveraging Generative AI to improve developer efficiency and game play quality.
Unique non-player character (NPC) dialogue
Game replay is important to ensure players return to the game and do not quit when having to replay a certain section, for example due to continued defeat against a difficult adversary. Creating a unique experience each time a player interacts with an NPC or watches a cut scene can increase player satisfaction. By creating NPCs backed by LLMs, NPC responses can be uniquely generated during each interaction, while maintaining the required lore and information needed to be presented.
Script writing efficiency
NPCs are sometimes meant to say a specific script, and uniqueness isn’t a requirement. In this case, LLMs can help improve the efficiency in script writing. By providing a model with the lore, setting, and expected outcomes of a game, one can quickly generate scripts for the personas of different NPCs. This will improve the efficiency of script writers, providing them time to create and explore new characters and ideas.
Chat and audio moderation and toxicity detection
Online games offering chat and audio services face a difficulty in maintaining a game community where friendly banter and trash talk is allowed, but inappropriate language is not. Moderation workflows can be built to analyze chat and audio of a reported player to determine if their language fits within the game publisher’s guidelines. LLMs can be used as evaluation agents to understand the context of a player’s language and determine if action should be taken.
Design patterns for model customization
In order for companies to utilize these use cases, they need a generative AI application. At the core of a generative AI application is one or more models. Applications can use a foundation model as is, and with extensive prompt engineering, it’s possible to get quality and acceptable results. However, the vast majority of use cases will benefit from customization of the models. Customization can be done in a variety of ways as described in the following section.
Model customization methods
Fine-tuning – altering the foundation model using your own data. This process changes the model parameters, which requires a larger upfront amount of computing power, but allows for FMs to be trained to do tasks which they previously could not.
Pretraining – training a model from scratch using your own repository of unlabeled data. This provides the greatest level of control and customization; however, it requires vast amounts of data (often terabytes), in-depth machine learning knowledge, and large amounts of computing power. Training a model should be used for use cases where there are no FMs which can be fine-tuned to execute your task.
Retrieval Augmented Generation (RAG) – This is an alternative to fine-tuning a model where model parameters are not changed. Instead, domain data is converted to vector embeddings, which are indexed in a vector database and a similarity search of the prompt embedding is performed against the index and resulting data is fed as context within the prompt.
The choice of customization depends on the use case. Fine tuning excels in domain adaptation – for example, you can tune a model with game lore to be used as the base for NPCs and leveraging different prompt templates for different NPCs. For use cases where contextual knowledge and verifiable responses is more important, RAG performs better, such as writing scripts for different character personas. These scripts could change at a more frequent pace, the database can be continuously reindexed for changing data and scripts can be updated more frequently. RAG is particularly popular with game studios when it comes to protecting the intellectual property, and security of game-specific data. By utilizing RAG, you can provide secure, and governed access to FMs without directly incorporating the data into the model though the process of re-training, or fine-tuning.
Irrespective of the type of customization, an LLMOps pipeline for handling changes to the model and changes to the overall application will lead to faster iteration cycles.
LLMOps overview
LLMOps encompasses three main phases: Continuous Integration (CI), Continuous Deployment (CD), and Continuous Tuning (CT).
CI consists of merging all working copies of an application’s code into a single version and running system and unit tests on it. When working with LLMs and other FMs, unit tests often need to be manual tests of the model’s output. For example, with an NPC backed by an LLM, tests could consist of asking questions to the NPC about their background, other characters in the game, and the setting.
CD consists of deploying the application infrastructure and model(s) into the specified environments once the models are evaluated for performance and quality with metric based evaluation or with humans in the loop. Common pattern consists of deploying into a development environment and quality assurance (QA) environment, before deploying into production(PROD). By placing a manual approval between the QA and PROD environment deployments, you can ensure the new models are tested in QA prior to deployment in PROD.
CT is the process of fine-tuning a foundation model with additional data to update the model’s parameters which optimizes and creates a new version of the model as explained in the previous section. This process generally consists of data pre-processing, model tuning, model evaluation, and model registration. Once the model is stored in a model registry, it can be reviewed and approved for deployment.
LLMOps on AWS
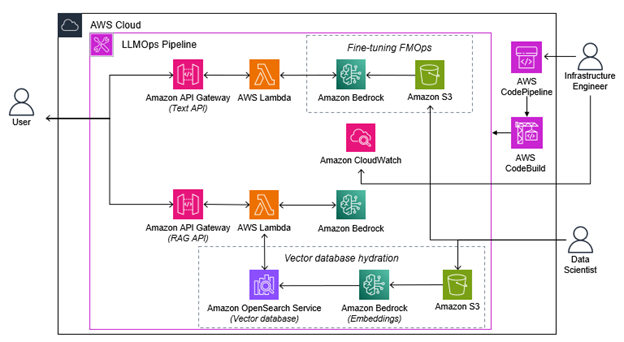
The following diagram illustrates the LLMOps on AWS solution.

At a high level, this architecture deploys the following infrastructure:
- Amazon API Gateway backed APIs to access a text generation model and image generation model on Amazon Bedrock deployed into multiple environments.
- AWS CodeCommit repository and AWS CodePipeline for automating CI/CD/CT actions including self-mutation to add new stages and resources when needed.
- Amazon SageMaker Pipeline and AWS Step Functions workflow to automate fine-tuning.
- Amazon OpenSearch cluster and Amazon SageMaker Processing Job to automate vector database indexing for RAG.
In the second blog post in this three-part series, we will dive deeper into the architecture and how the services come together.
Deployment
Below are a few methods to deploy this solution on AWS.
- The architecture is used as the backbone to build the Dynamic Non-Player Character Dialogue on AWS The Github repo walks through how to deploy the solution.
- A workshop Operationalize Generative AI Applications using LLMOps that provides step-by-step instructions to learn and deploy LLMOps on AWS.
Conclusion
Currently, many game companies invest large amounts of effort in writing scripts for NPCs, mapping different script scenarios, and reviewing reported players. In this blog, we explored how LLMs within games and game backends can create unique player experiences and reduce development time for manual tasks, so companies can focus on creating the best game experience for their customers. LLMOps is the backbone for ensuring an operational platform is established for tuning and managing models at scale.
In part 2, we will deep dive into the architecture shown above and explain how the services work together to create a solution that allows for the management of generative AI applications across AWS regions and accounts.
Author: Chaitra Mathur