

Operationalize generative AI applications on AWS: Part II – Architecture Deep Dive
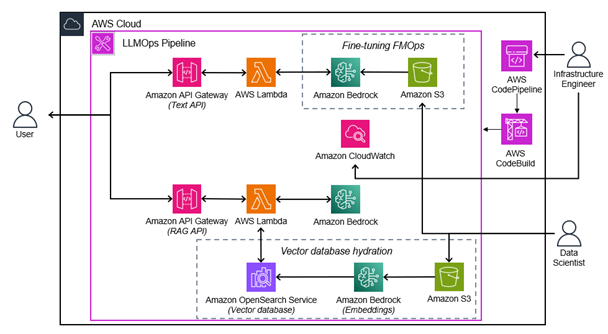
We will break the architecture into four sections: The APIs used to invoke the text and image foundation models The code pipeline to build, test, and deploy architecture changes Continuous fine-tuning to create custom models RAG with automated vector database hydration By the end of t…
In our previous blog, Operationalize generative AI applications on AWS: Part I, we covered the basics of how companies are using generative AI and Large Language Model Operations (LLMOps) on AWS. We discussed use cases for game companies using generative AI, ways to customize LLM, and a high-level architecture for the LLMOps solution on AWS. In this blog we will dive deeper into the architecture.
The architecture that we describe here is a solution guidance to create non-player characters (NPC) for games using generative AI services. The application provides three choices for generating dialogs for the NPC character, using responses from (1) base LLM; or (2) finetuned LLM; or (3) a games-specific, context-aware Retrieval Augmented Generation (RAG) pipeline. The application is then deployed using a continuous integration and continuous deployment (CI/CD) pipeline. This entire architecture is serverless meaning there is no infrastructure to manage, all services scale automatically, and you only pay for what you use. Although we describe this in the context of games, the LLMOps architecture can be applied to operationalizing any other type of generative AI application.
We will break the architecture into four sections:
- The APIs used to invoke the text and image foundation models
- The code pipeline to build, test, and deploy architecture changes
- Continuous fine-tuning to create custom models
- RAG with automated vector database hydration
By the end of this blog, the architecture will look as follows:

Figure 1: High level Architecture
Base Model Inference

Figure 2: Base Model Inference
The foundational aspect of any generative AI application is the model used to generate content and the APIs used to invoke these models. This solution is built using foundation models hosted on Amazon Bedrock. These models are accessed by sending prompts through an API hosted on Amazon API Gateway, which triggers an AWS Lambda function. The Lambda functions are coded with prompt templates tailored for the specific model they’re associated with, and the prompts along with the prompt templates invoke the model via the Bedrock invoke_model() SDK method.
Amazon Bedrock supports text, image, and embedding models allowing for this architecture to be used for many different use cases.
Code Pipeline: High-Level

Figure 3: High-Level Code Pipeline
Once the APIs are created, the next step is to wrap it in a CI/CD pipeline (AWS CodePipeline) to automate the continuous integration and continuous deployment of your application. At this point, models aren’t being customized and the application is only interacting with FMs, so there is no Continuous Tuning aspect yet. While the diagram above only changed slightly, below is what is actually being deployed.
Code Pipeline: Detailed

Figure 4: Detailed Code Pipeline
An AWS CodeCommit Repository is created to store the application code. When any source code changes are made, the pipeline is re-executed. At each stage, the pipeline checks to see if the changes affected the current stage, and if it does, automatically makes the necessary changes. This is the self-mutating piece of the pipeline. The pipeline builds and tests the application, deploys it into a QA environment, runs system tests on the deployment, and if they succeed, deploys the infrastructure changes into production. Deploying into QA first allows you to catch potential issues before deploying to production.
Continuous Fine-Tuning

Figure 5: High-Level Continuous Tuning
Now that the APIs and models can be tested in environments before deploying into production, it is safe to start fine-tuning models, if needed, to create custom models. As discussed in the first blog post, continuous tuning consists of data preprocessing, model tuning, model evaluation, and model registration. In this solution, these four steps are automated with an Amazon SageMaker Pipelines and an AWS Step Functions flow.

Figure 6: Automated Fine-Tuning Pipeline
When data is uploaded to the specific Amazon Simple Storage Service (S3) bucket, a lambda function is triggered which kicks off a SageMaker Pipeline. The SageMaker pipeline automates data preprocessing, model fine tuning, model evaluation, and model registration. Each step in the pipeline can be an Amazon SageMaker Processing Job, but as of the writing this blog (April 2024), it does not natively support fine-tuning jobs in Amazon Bedrock. To get around this, a callback step is used to send a message to an Amazon Simple Queue Service (SQS) Queue which starts a Step Function Flow.

Figure 7: Fine-Tuning Call Back Step Function
This Step Function Flow uses Lambda Functions to start the fine-tuning job on Amazon Bedrock, waits 10 minutes, checks the progress of the job, and if it is incomplete waits another 10 minutes and repeats the process until it completes. Once the tuning job completes, a successful callback is sent back to the SageMaker Pipeline.
The data preprocessing and model evaluation steps run SageMaker Processing Jobs, which allow you to run a script on a processing container fully managed by Amazon SageMaker, which is only provisioned for the duration of the job. The final step is a RegisterModel Step within SageMaker Pipelines, which creates a model package and registers it in SageMaker Model Registry. A model package is a reusable model artifacts abstraction that packages all ingredients necessary for inference.
At this point, the new model version is stored in SageMaker Model Registry and the fine-tuned, custom model is available in Bedrock. Once the model is provisioned for use via Bedrock, code pipeline is triggered to use this new model. To run inference against a custom model in Amazon Bedrock, provisioned throughput must be associated with the custom model. To make the association, purchase provisioned throughput on the Bedrock page in the AWS Management Console and select your custom model.
Once Provisioned Throughput is in InService, the model can be approved within the Model Registry. Upon Approval, an Amazon EventBridge message triggers a Lambda Function which updates a variable within AWS Systems Manager Parameter Store and begins an execution of the Code Pipeline. The pipeline identifies a change in the Parameter Store Variable and updates the applications to use the new model. Assuming all tests, pass, the application will automatically be deployed into production using the new custom model.
Retrieval Augments Generation (RAG)

Figure 8: Retrieval Augmented Generation
As an alternative way to add context and additional information to the model without fine-tuning, we can utilize RAG. RAG consists of two main parts: (1) Converting the data to vector space and storing that in a Vector Database which we call hydration, and (2) Adding context from the vector database to incoming prompts.
Database hydration

Figure 9: Automated database hydration
Hydrating the vector database consists of processing your documents or data into chunks, creating embeddings for the chunks by using an embeddings model, and storing these embeddings along with the data in a vector database. We automate this process by starting a SageMaker Processing Job whenever new data is uploaded to S3. The processing job chunks the data, creates embeddings of the data using an embeddings model hosted on Amazon Bedrock, and stores the output in an Amazon OpenSearch Service Cluster, which is used as the vector database.
Adding context
When a prompt is sent to the model, the prompt is converted to vector embeddings and a similarity search is run against the vector database. The search returns the top x number of most relevant documents which are then added to the prompt and passed to the LLM. We use lambda function to orchestrate this RAG pipeline.
Conclusion
In this blog, we described LLMOps architecture in the context of a generative AI application built using native AWS services. The generative AI application uses Amazon Bedrock models to create dialogs for the NPC character. We described how to automate fine tuning of models and also automate RAG pipeline for augmenting the incoming prompts. We showed you how to wrap the entire application in a CI/CD pipeline. In the next and final post in the three-part series, we will dive into the code used to deploy this solution. For a step-by-step walkthrough of this solution, refer to the following workshop: Operationalize Generative AI Applications on AWS.
Author: Andrew Walko