

Package and deploy classical ML and LLMs easily with Amazon SageMaker, part 1: PySDK Improvements
Amazon SageMaker is a fully managed service that enables developers and data scientists to quickly and effortlessly build, train, and deploy machine learning (ML) models at any scale… SageMaker makes it straightforward to deploy models into production directly through API calls to the service… A…
Amazon SageMaker is a fully managed service that enables developers and data scientists to quickly and effortlessly build, train, and deploy machine learning (ML) models at any scale. SageMaker makes it straightforward to deploy models into production directly through API calls to the service. Models are packaged into containers for robust and scalable deployments. Although it provides various entry points like the SageMaker Python SDK, AWS SDKs, the SageMaker console, and Amazon SageMaker Studio notebooks to simplify the process of training and deploying ML models at scale, customers are still looking for better ways to deploy their models for playground testing and to optimize production deployments.
We are launching two new ways to simplify the process of packaging and deploying models using SageMaker.
In this post, we introduce the new SageMaker Python SDK ModelBuilder experience, which aims to minimize the learning curve for new SageMaker users like data scientists, while also helping experienced MLOps engineers maximize utilization of SageMaker hosting services. It reduces the complexity of initial setup and deployment, and by providing guidance on best practices for taking advantage of the full capabilities of SageMaker. We provide detailed information and GitHub examples for this new SageMaker capability.
The other new launch is to use the new interactive deployment experience in SageMaker Studio. We discuss this in Part 2.
Deploying models to a SageMaker endpoint entails a series of steps to get the model ready to be hosted on a SageMaker endpoint. This involves getting the model artifacts in the correct format and structure, creating inference code, and specifying essential details like the model image URL, Amazon Simple Storage Service (Amazon S3) location of model artifacts, serialization and deserialization steps, and necessary AWS Identity and Access Management (IAM) roles to facilitate appropriate access permissions. Following this, an endpoint configuration requires determining the inference type and configuring respective parameters such as instance types, counts, and traffic distribution among model variants.
To further help our customers when using SageMaker hosting, we introduced the new ModelBuilder class in the SageMaker Python SDK, which brings the following key benefits when deploying models to SageMaker endpoints:
- Unifies the deployment experience across frameworks – The new experience provides a consistent workflow for deploying models built using different frameworks like PyTorch, TensorFlow, and XGBoost. This simplifies the deployment process.
- Automates model deployment – Tasks like selecting appropriate containers, capturing dependencies, and handling serialization/deserialization are automated, reducing manual effort required for deployment.
- Provides a smooth transition from local to SageMaker hosted endpoint – With minimal code changes, models can be easily transitioned from local testing to deployment on a SageMaker endpoint. Live logs make debugging seamless.
Overall, SageMaker ModelBuilder simplifies and streamlines the model packaging process for SageMaker inference by handling low-level details and provides tools for testing, validation, and optimization of endpoints. This improves developer productivity and reduces errors.
In the following sections, we deep dive into the details of this new feature. We also discuss how to deploy models to SageMaker hosting using ModelBuilder, which simplifies the process. Then we walk you through a few examples for different frameworks to deploy both traditional ML models and the foundation models that power generative AI use cases.
Getting to know SageMaker ModelBuilder
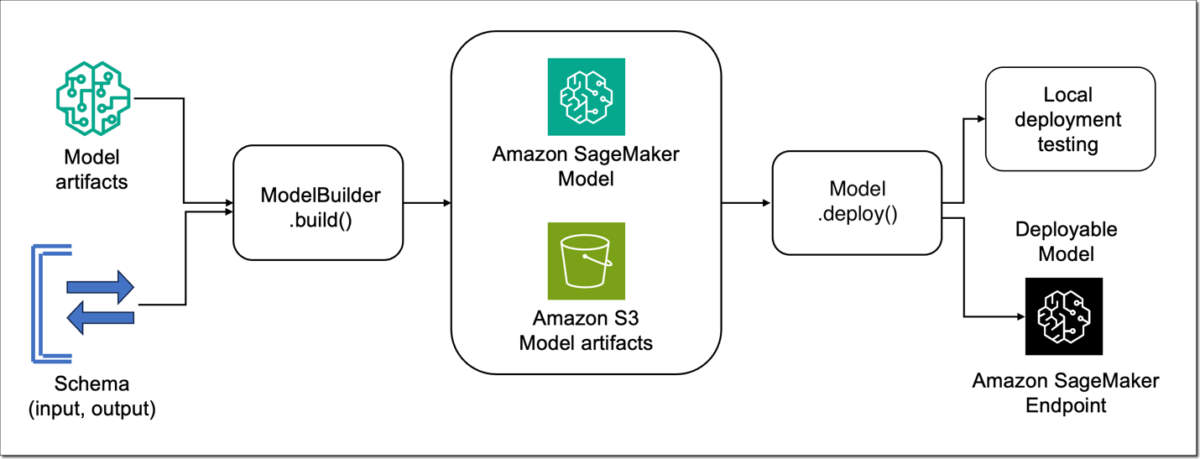
The new ModelBuilder is a Python class focused on taking ML models built using frameworks, like XGBoost or PyTorch, and converting them into models that are ready for deployment on SageMaker. ModelBuilder provides a build() function, which generates the artifacts according the model server, and a deploy() function to deploy locally or to a SageMaker endpoint. The introduction of this feature simplifies the integration of models with the SageMaker environment, optimizing them for performance and scalability. The following diagram shows how ModelBuilder works on a high-level.

ModelBuilder class
The ModelBuilder class provide different options for customization. However, to deploy the framework model, the model builder just expects the model, input, output, and role:
SchemaBuilder
The SchemaBuilder class enables you to define the input and output for your endpoint. It allows the schema builder to generate the corresponding marshaling functions for serializing and deserializing the input and output. The following class file provides all the options for customization:
However, in most cases, just sample input and output would work. For example:
By providing sample input and output, SchemaBuilder can automatically determine the necessary transformations, making the integration process more straightforward. For more advanced use cases, there’s flexibility to provide custom translation functions for both input and output, ensuring that more complex data structures can also be handled efficiently. We demonstrate this in the following sections by deploying different models with various frameworks using ModelBuilder.
Local mode experience
In this example, we use ModelBuilder to deploy XGBoost model locally. You can use Mode to switch between local testing and deploying to a SageMaker endpoint. We first train the XGBoost model (locally or in SageMaker) and store the model artifacts in the working directory:
Then we create a ModelBuilder object by passing the actual model object, the SchemaBuilder that uses the sample test input and output objects (the same input and output we used when training and testing the model) to infer the serialization needed. Note that we use Mode.LOCAL_CONTAINER to specify a local deployment. After that, we call the build function to automatically identify the supported framework container image as well as scan for dependencies. See the following code:
Finally, we can call the deploy function in the model object, which also provides live logging for easier debugging. You don’t need to specify the instance type or count because the model will be deployed locally. If you provided these parameters, they will be ignored. This function will return the predictor object that we can use to make prediction with the test data:
Optionally, you can also control the loading of the model and preprocessing and postprocessing using InferenceSpec. We provide more details later in this post. Using LOCAL_CONTAINER is a great way to test out your script locally before deploying to a SageMaker endpoint.
Refer to the model-builder-xgboost.ipynb example to test out deploying both locally and to a SageMaker endpoint using ModelBuilder.
Deploy traditional models to SageMaker endpoints
In the following examples, we showcase how to use ModelBuilder to deploy traditional ML models.
XGBoost models
Similar to the previous section, you can deploy an XGBoost model to a SageMaker endpoint by changing the mode parameter when creating the ModelBuilder object:
Note that when deploying to SageMaker endpoints, you need to specify the instance type and instance count when calling the deploy function.
Refer to the model-builder-xgboost.ipynb example to deploy an XGBoost model.
Triton models
You can use ModelBuilder to serve PyTorch models on Triton Inference Server. For that, you need to specify the model_server parameter as ModelServer.TRITON, pass a model, and have a SchemaBuilder object, which requires sample inputs and outputs from the model. ModelBuilder will take care of the rest for you.
Refer to model-builder-triton.ipynb to deploy a model with Triton.
Hugging Face models
In this example, we show you how to deploy a pre-trained transformer model provided by Hugging Face to SageMaker. We want to use the Hugging Face pipeline to load the model, so we create a custom inference spec for ModelBuilder:
We also define the input and output of the inference workload by defining the SchemaBuilder object based on the model input and output:
Then we create the ModelBuilder object and deploy the model onto a SageMaker endpoint following the same logic as shown in the other example:
Refer to model-builder-huggingface.ipynb to deploy a Hugging Face pipeline model.
Deploy foundation models to SageMaker endpoints
In the following examples, we showcase how to use ModelBuilder to deploy foundation models. Just like the models mentioned earlier, all that is required is the model ID.
Hugging Face Hub
If you want to deploy a foundation model from Hugging Face Hub, all you need to do is pass the pre-trained model ID. For example, the following code snippet deploys the meta-llama/Llama-2-7b-hf model locally. You can change the mode to Mode.SAGEMAKER_ENDPOINT to deploy to SageMaker endpoints.
For gated models on Hugging Face Hub, you need to request access via Hugging Face Hub and use the associated key by passing it as the environment variable HUGGING_FACE_HUB_TOKEN. Some Hugging Face models may require trusting remote code. It can be set as an environment variable as well using HF_TRUST_REMOTE_CODE. By default, ModelBuilder will use a Hugging Face Text Generation Inference (TGI) container as the underlying container for Hugging Face models. If you would like to use AWS Large Model Inference (LMI) containers, you can set up the model_server parameter as ModelServer.DJL_SERVING when you configure the ModelBuilder object.
A neat feature of ModelBuilder is the ability to run local tuning of the container parameters when you use LOCAL_CONTAINER mode. This feature can be used by simply running tuned_model = model.tune().
Refer to demo-model-builder-huggingface-llama2.ipynb to deploy a Hugging Face Hub model.
SageMaker JumpStart
Amazon SageMaker JumpStart also offers a number of pre-trained foundation models. Just like the process of deploying a model from Hugging Face Hub, the model ID is required. Deploying a SageMaker JumpStart model to a SageMaker endpoint is as straightforward as running the following code:
For all available SageMaker JumpStart model IDs, refer to Built-in Algorithms with pre-trained Model Table. Refer to model-builder-jumpstart-falcon.ipynb to deploy a SageMaker JumpStart model.
Inference component
ModelBulder allows you to use the new inference component capability in SageMaker to deploy models. For more information on inference components, see Reduce Model Deployment Costs By 50% on Average Using SageMaker’s Latest Features. You can use inference components for deployment with ModelBuilder by specifying endpoint_type=EndpointType.INFERENCE_COMPONENT_BASED in the deploy() method. You can also use the tune() method, which fetches the optimal number of accelerators, and modify it if required.
Refer to model-builder-inference-component.ipynb to deploy a model as an inference component.
Customize the ModelBuilder Class
The ModelBuilder class allows you to customize model loading using InferenceSpec.
In addition, you can control payload and response serialization and deserialization and customize preprocessing and postprocessing using CustomPayloadTranslator. Additionally, when you need to extend our pre-built containers for model deployment on SageMaker, you can use ModelBuilder to handle the model packaging process. In this following section, we provide more details of these capabilities.
InferenceSpec
InferenceSpec offers an additional layer of customization. It allows you to define how the model is loaded and how it will handle incoming inference requests. Through InferenceSpec, you can define custom loading procedures for your models, bypassing the default loading mechanisms. This flexibility is particularly beneficial when working with non-standard models or custom inference pipelines. The invoke method can be customized, providing you with the ability to tailor how the model processes incoming requests (preprocessing and postprocessing). This customization can be essential to ensure that the inference process aligns with the specific needs of the model. See the following code:
The following code shows an example of using this class:
CustomPayloadTranslator
When invoking SageMaker endpoints, the data is sent through HTTP payloads with different MIME types. For example, an image sent to the endpoint for inference needs to be converted to bytes at the client side and sent through the HTTP payload to the endpoint. When the endpoint receives the payload, it needs to deserialize the byte string back to the data type that is expected by the model (also known as server-side deserialization). After the model finishes prediction, the results need to be serialized to bytes that can be sent back through the HTTP payload to the user or client. When the client receives the response byte data, it needs to perform client-side deserialization to convert the bytes data back to the expected data format, such as JSON. At a minimum, you need to convert the data for the following (as numbered in the following diagram):
- Inference request serialization (handled by the client)
- Inference request deserialization (handled by the server or algorithm)
- Invoking the model against the payload
- Sending response payload back
- Inference response serialization (handled by the server or algorithm)
- Inference response deserialization (handled by the client)
The following diagram shows the process of serialization and deserialization during the invocation process.

In the following code snippet, we show an example of CustomPayloadTranslator when additional customization is needed to handle both serialization and deserialization in the client and server side, respectively:
In the demo-model-builder-pytorch.ipynb notebook, we demonstrate how to easily deploy a PyTorch model to a SageMaker endpoint using ModelBuilder with the CustomPayloadTranslator and the InferenceSpec class.
Stage model for deployment
If you want to stage the model for inference or in the model registry, you can use model.create() or model.register(). The enabled model is created on the service, and then you can deploy later. See the following code:
Use custom containers
SageMaker provides pre-built Docker images for its built-in algorithms and the supported deep learning frameworks used for training and inference. If a pre-built SageMaker container doesn’t fulfill all your requirements, you can extend the existing image to accommodate your needs. By extending a pre-built image, you can use the included deep learning libraries and settings without having to create an image from scratch. For more details about how to extend the pre-built containers, refer to SageMaker document. ModelBuilder supports use cases when bringing your own containers that are extended from our pre-built Docker containers.
To use your own container image in this case, you need to set the fields image_uri and model_server when defining ModelBuilder:
Here, the image_uri will be the container image ARN that is stored in your account’s Amazon Elastic Container Registry (Amazon ECR) repository. One example is shown as follows:
When the image_uri is set, during the ModelBuilder build process, it will skip auto detection of the image as the image URI is provided. If model_server is not set in ModelBuilder, you will receive a validation error message, for example:
As of the publication of this post, ModelBuilder supports bringing your own containers that are extended from our pre-built DLC container images or containers built with the model servers like Deep Java Library (DJL), Text Generation Inference (TGI), TorchServe, and Triton inference server.
Custom dependencies
When running ModelBuilder.build(), by default it automatically captures your Python environment into a requirements.txt file and installs the same dependency in the container. However, sometimes your local Python environment will conflict with the environment in the container. ModelBuilder provides a simple way for you to modify the captured dependencies to fix such dependency conflicts by allowing you to provide your custom configurations into ModelBuilder. Note that this is only for TorchServe and Triton with InferenceSpec. For example, you can specify the input parameter dependencies, which is a Python dictionary, in ModelBuilder as follows:
We define the following fields:
- auto – Whether to try to auto capture the dependencies in your environment.
- requirements – A string of the path to your own
requirements.txtfile. (This is optional.) - custom – A list of any other custom dependencies that you want to add or modify. (This is optional.)
If the same module is specified in multiple places, custom will have highest priority, then requirements, and auto will have lowest priority. For example, let’s say that during autodetect, ModelBuilder detects numpy==1.25, and a requirements.txt file is provided that specifies numpy>=1.24,<1.26. Additionally, there is a custom dependency: custom = ["numpy==1.26.1"]. In this case, numpy==1.26.1 will be picked when we install dependencies in the container.
Clean up
When you’re done testing the models, as a best practice, delete the endpoint to save costs if the endpoint is no longer required. You can follow the Clean up section in each of the demo notebooks or use following code to delete the model and endpoint created by the demo:
Conclusion
The new SageMaker ModelBuilder capability simplifies the process of deploying ML models into production on SageMaker. By handling many of the complex details behind the scenes, ModelBuilder reduces the learning curve for new users and maximizes utilization for experienced users. With just a few lines of code, you can deploy models with built-in frameworks like XGBoost, PyTorch, Triton, and Hugging Face, as well as models provided by SageMaker JumpStart into robust, scalable endpoints on SageMaker.
We encourage all SageMaker users to try out this new capability by referring to the ModelBuilder documentation page. ModelBuilder is available now to all SageMaker users at no additional charge. Take advantage of this simplified workflow to get your models deployed faster. We look forward to hearing how ModelBuilder accelerates your model development lifecycle!
Special thanks to Sirisha Upadhyayala, Raymond Liu, Gary Wang, Dhawal Patel, Deepak Garg and Ram Vegiraju.
About the authors
 Melanie Li, PhD, is a Senior AI/ML Specialist TAM at AWS based in Sydney, Australia. She helps enterprise customers build solutions using state-of-the-art AI/ML tools on AWS and provides guidance on architecting and implementing ML solutions with best practices. In her spare time, she loves to explore nature and spend time with family and friends.
Melanie Li, PhD, is a Senior AI/ML Specialist TAM at AWS based in Sydney, Australia. She helps enterprise customers build solutions using state-of-the-art AI/ML tools on AWS and provides guidance on architecting and implementing ML solutions with best practices. In her spare time, she loves to explore nature and spend time with family and friends.
 Marc Karp is an ML Architect with the Amazon SageMaker Service team. He focuses on helping customers design, deploy, and manage ML workloads at scale. In his spare time, he enjoys traveling and exploring new places.
Marc Karp is an ML Architect with the Amazon SageMaker Service team. He focuses on helping customers design, deploy, and manage ML workloads at scale. In his spare time, he enjoys traveling and exploring new places.
 Sam Edwards, is a Cloud Engineer (AI/ML) at AWS Sydney specialized in machine learning and Amazon SageMaker. He is passionate about helping customers solve issues related to machine learning workflows and creating new solutions for them. Outside of work, he enjoys playing racquet sports and traveling.
Sam Edwards, is a Cloud Engineer (AI/ML) at AWS Sydney specialized in machine learning and Amazon SageMaker. He is passionate about helping customers solve issues related to machine learning workflows and creating new solutions for them. Outside of work, he enjoys playing racquet sports and traveling.
 Raghu Ramesha is a Senior ML Solutions Architect with the Amazon SageMaker Service team. He focuses on helping customers build, deploy, and migrate ML production workloads to SageMaker at scale. He specializes in machine learning, AI, and computer vision domains, and holds a master’s degree in Computer Science from UT Dallas. In his free time, he enjoys traveling and photography.
Raghu Ramesha is a Senior ML Solutions Architect with the Amazon SageMaker Service team. He focuses on helping customers build, deploy, and migrate ML production workloads to SageMaker at scale. He specializes in machine learning, AI, and computer vision domains, and holds a master’s degree in Computer Science from UT Dallas. In his free time, he enjoys traveling and photography.
 Shiva Raaj Kotini works as a Principal Product Manager in the Amazon SageMaker inference product portfolio. He focuses on model deployment, performance tuning, and optimization in SageMaker for inference.
Shiva Raaj Kotini works as a Principal Product Manager in the Amazon SageMaker inference product portfolio. He focuses on model deployment, performance tuning, and optimization in SageMaker for inference.
 Mohan Gandhi is a Senior Software Engineer at AWS. He has been with AWS for the last 10 years and has worked on various AWS services like EMR, EFA and RDS. Currently, he is focused on improving the SageMaker Inference Experience. In his spare time, he enjoys hiking and marathons.
Mohan Gandhi is a Senior Software Engineer at AWS. He has been with AWS for the last 10 years and has worked on various AWS services like EMR, EFA and RDS. Currently, he is focused on improving the SageMaker Inference Experience. In his spare time, he enjoys hiking and marathons.
Author: Melanie Li