

Package and deploy classical ML and LLMs easily with Amazon SageMaker, part 2: Interactive User Experiences in SageMaker Studio
Amazon SageMaker is a fully managed service that enables developers and data scientists to quickly and easily build, train, and deploy machine learning (ML) models at scale… SageMaker makes it easy to deploy models into production directly through API calls to the service… SageMaker provides a …
Amazon SageMaker is a fully managed service that enables developers and data scientists to quickly and easily build, train, and deploy machine learning (ML) models at scale. SageMaker makes it easy to deploy models into production directly through API calls to the service. Models are packaged into containers for robust and scalable deployments.
SageMaker provides a variety of options to deploy models. These options vary in the amount of control you have and the work needed at your end. The AWS SDK gives you most control and flexibility. It’s a low-level API available for Java, C++, Go, JavaScript, Node.js, PHP, Ruby, and Python. The SageMaker Python SDK is a high-level Python API that abstracts some of the steps and configuration, and makes it easier to deploy models. The AWS Command Line Interface (AWS CLI) is another high-level tool that you can use to interactively work with SageMaker to deploy models without writing your own code.
We are launching two new options that further simplify the process of packaging and deploying models using SageMaker. One way is for programmatic deployment. For that, we are offering improvements in the Python SDK. For more information, refer to Package and deploy classical ML and LLMs easily with Amazon SageMaker, part 1: PySDK Improvements. The second way is for interactive deployment. For that, we are launching a new interactive experience in Amazon SageMaker Studio. It will help you quickly deploy your own trained or foundational models (FMs) from Amazon SageMaker JumpStart with optimized configuration, and achieve predictable performance at the lowest cost. Read on to check out what the new interactive experience looks like.
New interactive experience in SageMaker Studio
This post assumes that you have trained one or more ML models or are using FMs from the SageMaker JumpStart model hub and are ready to deploy them. Training a model using SageMaker is not a prerequisite for deploying model using SageMaker. Some familiarity with SageMaker Studio is also assumed.
We walk you through how to do the following:
- Create a SageMaker model
- Deploy a SageMaker model
- Deploy a SageMaker JumpStart large language model (LLM)
- Deploy multiple models behind one endpoint
- Test model inference
- Troubleshoot errors
Create a SageMaker model
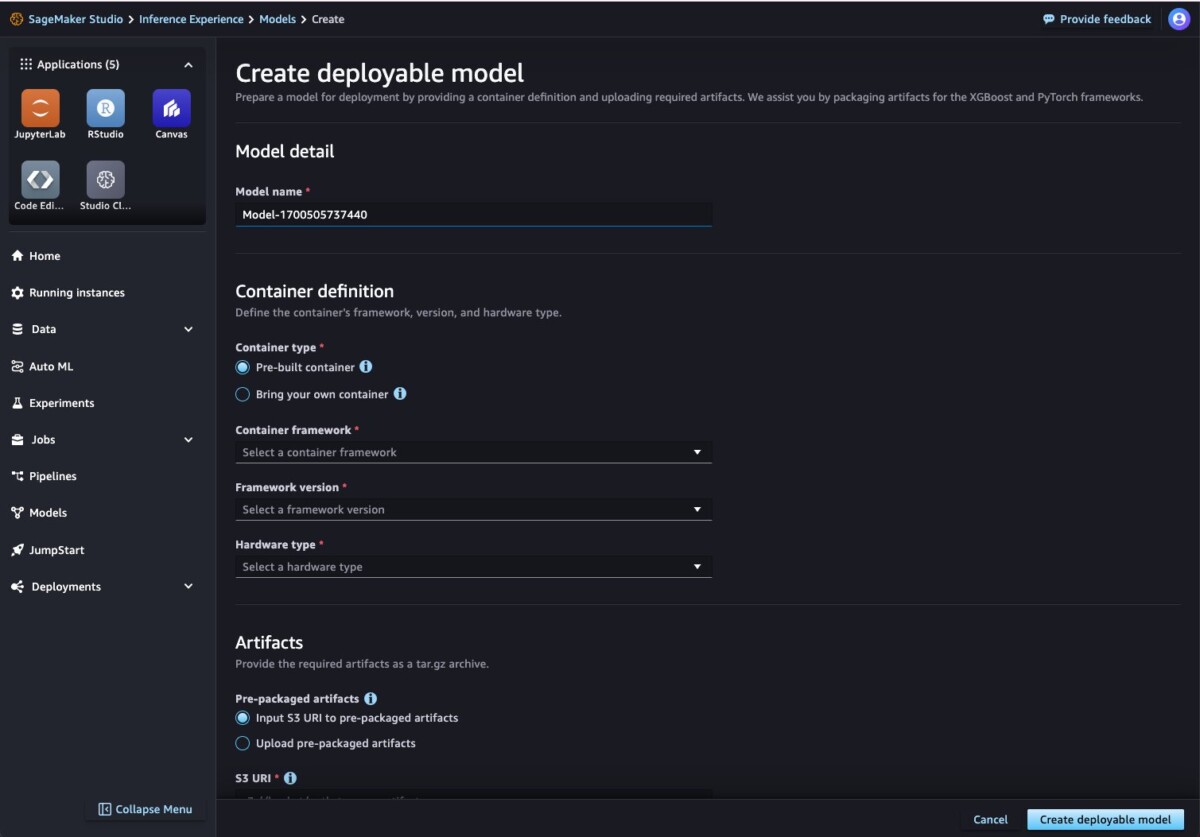
The first step in setting up a SageMaker endpoint for inference is to create a SageMaker model object. This model object is made up of two things: a container for the model, and the trained model that will be used for inference. The new interactive UI experience makes the SageMaker model creation process straightforward. If you’re new to SageMaker Studio, refer to the Developer Guide to get started.
- In the SageMaker Studio interface, choose Models in the navigation pane.
- On the Deployable models tab, choose Create.
Now all you need to do is provide the model container details, the location of your model data, and an AWS Identity and Access Management (IAM) role for SageMaker to assume on your behalf.

- For the model container, you can use one of the SageMaker pre-built Docker images that it provides for popular frameworks and libraries. If you choose to use this option, choose a container framework, a corresponding framework version, and a hardware type from the list of supported types.


Alternatively, you can specify a path to your own container stored in Amazon Elastic Container Registry (Amazon ECR).

- Next, upload your model artifacts. SageMaker Studio provides two ways to upload model artifacts:
- First, you can specify a
model.tar.gzeither in an Amazon Simple Storage Service (Amazon S3) bucket or in your local path. Thismodel.tar.gzmust be structured in a format that is compliant with the container that you are utilizing. - Alternatively, it supports raw artifact uploading for PyTorch and XGBoost models. For these two frameworks, provide the model artifacts in the format the container expects. For example, for PyTorch this would be a
model.pth. Note that your model artifacts also include an inference script for preprocessing and postprocessing. If you don’t provide an inference script, the default inference handlers for the container you have chosen will be implemented.
- First, you can specify a
- After you select your container and artifact, specify an IAM role.
- Choose Create deployable model to create a SageMaker model.


The preceding steps demonstrate the simplest workflow. You can further customize the model creation process. For example, you can specify VPC details and enable network isolation to make sure that the container can’t make outbound calls on the public internet. You can expand the Advanced options section to see more options.
You can get guidance on the hardware for best price/performance ratio to deploy your endpoint by running a SageMaker Inference Recommender benchmarking job. To further customize the SageMaker model, you can pass in any tunable environment variables at the container level. Inference Recommender will also take a range of these variables to find the optimal configuration for your model serving and container.

After you create your model, you can see it on the Deployable models tab. If there was any issue found in the model creation, you will see the status in the Monitor status column. Choose the model’s name to view the details.

Deploy a SageMaker model
In the most basic scenario, all you need to do is select a deployable model from the Models page or an LLM from the SageMaker JumpStart page, select an instance type, set the initial instance count, and deploy the model. Let’s see what this process looks like in SageMaker Studio for your own SageMaker model. We discuss using LLMs later in this post.
- On the Models page, choose the Deployable models tab.
- Select the model to deploy and choose Deploy.

- The next step is to select an instance type that SageMaker will put behind the inference endpoint.

You want an instance that delivers the best performance at the lowest cost. SageMaker makes it straightforward for you to make this decision by showing recommendations. If you had benchmarked your model using SageMaker Inference Recommender during the SageMaker model creation step, you will see the recommendations from that benchmark on the drop-down menu.

Otherwise, you will see a list of prospective instances on the menu. SageMaker uses its own heuristics to populate the list in that case.

- Specify the initial instance count, then choose Deploy.
SageMaker will create an endpoint configuration and deploy your model behind that endpoint. After the model is deployed, you will see the endpoint and model status as In service. Note that the endpoint may be ready before the model.

This is also the place in SageMaker Studio where you will manage the endpoint. You can navigate to the endpoint details page by choosing Endpoints under Deployments in the navigation pane. Use the Add model and Delete buttons to change the models behind the endpoint without needing to recreate an endpoint. The Test inference tab enables you to test your model by sending test requests to one of the in-service models directly from the SageMaker Studio interface. You can also edit the auto scaling policy on the Auto-scaling tab on this page. More details on adding, removing, and testing models are covered in the following sections. You can see the network, security, and compute information for this endpoint on the Settings tab.
Customize the deployment
The preceding example showed how straightforward it is to deploy a single model with minimum configuration required from your side. SageMaker populates most of the fields for you, but you can customize the configuration. For example, it automatically generates a name for the endpoint. However, you can name the endpoint according to your preference, or use an existing endpoint on the Endpoint name drop-down menu. For existing endpoints, you will see only the endpoints that are in service at that time. You can use the Advanced options section to specify an IAM role, VPC details, and tags.
Deploy a SageMaker JumpStart LLM
To deploy a SageMaker JumpStart LLM, complete the following steps:
- Navigate to the JumpStart page in SageMaker Studio.
- Choose one of the partner names to browse the list of models available from that partner, or use the search feature to get to the model page if you know the name of the model.
- Choose the model you want to deploy.

- Choose Deploy.



Note that use of LLMs is subject to EULA and the terms and conditions of the provider.
- Accept the license and terms.
- Specify an instance type.
Many models from the JumpStart model hub come with a price-performance optimized default instance type for deployment. For models that don’t come with this default, you will be provided with a list of supported instance types on the Instance type drop-down menu. For benchmarked models, if you want to optimize the deployment specifically for either cost or performance to meet your specific use case, you can choose Alternate configurations to view more options that have been benchmarked with different combinations of total tokens, input length, and max concurrency. You can also select from other supported instances for that model.

- If using an alternate configuration, select your instance and choose Select.

- Choose Deploy to deploy the model.

You will see the endpoint and model status change to In service. You also have options to customize the deployment to meet your requirements in this case.
Deploy multiple models behind one endpoint
SageMaker enables you to deploy multiple models behind a single endpoint. This reduces hosting costs by improving endpoint utilization compared to using endpoints with only one model behind them. It also reduces deployment overhead because SageMaker manages loading models in memory and scaling them based on the traffic patterns to your endpoint. SageMaker Studio now makes it straightforward to do this.
- Get started by selecting the models that you want to deploy, then choose Deploy.

- Then you can create an endpoint with multiple models that have an allocated amount of compute that you define.

In this case, we use an ml.p4d.24xlarge instance for the endpoint and allocate the necessary number of resources for our two different models. Note that your endpoint is constrained to the instance types that are supported by this feature.

- If you start the flow from the Deployable models tab and want to add a SageMaker JumpStart LLM, or vice versa, you can make it an endpoint fronting multiple models by choosing Add model after starting the deployment workflow.

- Here, you can choose another FM from the SageMaker JumpStart model hub or a model using the Deployable Models option, which refers to models that you have saved as SageMaker model objects.
- Choose your model settings:
- If the model uses a CPU instance, choose the number of CPUs and minimum number of copies for the model.
- If the model uses a GPU instance, choose the number of accelerators and minimum number of copies for the model.
- Choose Add model.

- Choose Deploy to deploy these models to a SageMaker endpoint.




When the endpoint is up and ready (In service status), you’ll have two models deployed behind a single endpoint.

Test model inference
SageMaker Studio now makes it straightforward to test model inference requests. You can send the payload data directly using the supported content type, such as application or JSON, text or CSV, or use Python SDK sample code to make an invocation request from your programing environment like a notebook or local integrated development environment (IDE).

Note that the Python SDK example code option is available only for SageMaker JumpStart models, and it’s tailored for the specific model use case with input/output data transformation.

Troubleshoot errors
To help troubleshoot and look deeper into model deployment, there are tooltips on the resource Status label to show corresponding error and reason messages. There are also links to Amazon CloudWatch log groups on the endpoint details page. For single-model endpoints, the link to the CloudWatch container logs is conveniently located in the Summary section of the endpoint details. For endpoints with multiple models, the links to the CloudWatch logs are located on each row of the Models table view. The following are some common error scenarios for troubleshooting:
- Model ping health check failure – The model deployment could fail because the serving container didn’t pass the model ping health check. To debug the issue, refer to the following container logs published by the CloudWatch log groups:
- Inconsistent model and endpoint configuration caused deployment failures – If the deployment failed by one of the following error messages, it means the selected model to deploy used a different IAM role, VPC configuration, or network isolation configuration. The remediation is to update the model details to use the same IAM role, VPC configuration, and network isolation configuration during the deployment flow. If you’re adding a model to an existing endpoint, you could recreate the model object to match the target endpoint configurations.
- Not enough capacity to deploy more models on the existing endpoint infrastructure – If the deployment failed with the following error message, it means the current endpoint infrastructure doesn’t have enough compute or memory hardware resources to deploy the model. The remediation is to increase the maximum instance count on the endpoint or delete any existing models deployed on the endpoint to make room for new model deployment.
- Unsupported instance type for multiple model endpoint deployment – If the deployment failed with the following error message, it means the selected instance type is currently not supported for the multiple model endpoint deployment. The remediation is to change the instance type to an instance that supports this feature and retry the deployment.
For other model deployment issues, refer to Supported features.
Clean up
Cleanup is also straightforward. You can remove one or more models from your existing SageMaker endpoint by selecting the specific model on the SageMaker console. To delete the whole endpoint, navigate to the Endpoints page, select the desired endpoint, choose Delete, and accept the disclaimer to proceed with deletion.


Conclusion
The enhanced interactive experience in SageMaker Studio allows data scientists to focus on model building and bringing their artifacts to SageMaker while abstracting out the complexities of deployment. For those who prefer a code-based approach, check out the low-code equivalent with the ModelBuilder class.
To learn more, visit the SageMaker ModelBuilder Python interface documentation and the guided deploy workflows in SageMaker Studio. There is no additional charge for the SageMaker SDK and SageMaker Studio. You pay only for the underlying resources used. For more information on how to deploy models with SageMaker, see Deploy models for inference.
Special thanks to Sirisha Upadhyayala, Melanie Li, Dhawal Patel, Sam Edwards and Kumara Swami Borra.
About the authors
 Raghu Ramesha is a Senior ML Solutions Architect with the Amazon SageMaker Service team. He focuses on helping customers build, deploy, and migrate ML production workloads to SageMaker at scale. He specializes in machine learning, AI, and computer vision domains, and holds a master’s degree in Computer Science from UT Dallas. In his free time, he enjoys traveling and photography.
Raghu Ramesha is a Senior ML Solutions Architect with the Amazon SageMaker Service team. He focuses on helping customers build, deploy, and migrate ML production workloads to SageMaker at scale. He specializes in machine learning, AI, and computer vision domains, and holds a master’s degree in Computer Science from UT Dallas. In his free time, he enjoys traveling and photography.
 Deepak Garg is a Solutions Architect at AWS. He loves diving deep into AWS services and sharing his knowledge with customers. Deepak has background in Content Delivery Networks and Telecommunications
Deepak Garg is a Solutions Architect at AWS. He loves diving deep into AWS services and sharing his knowledge with customers. Deepak has background in Content Delivery Networks and Telecommunications
 Ram Vegiraju is a ML Architect with the Amazon SageMaker Service team. He focuses on helping customers build and optimize their AI/ML solutions on Amazon SageMaker. In his spare time, he loves traveling and writing.
Ram Vegiraju is a ML Architect with the Amazon SageMaker Service team. He focuses on helping customers build and optimize their AI/ML solutions on Amazon SageMaker. In his spare time, he loves traveling and writing.
 Marc Karp is an ML Architect with the Amazon SageMaker Service team. He focuses on helping customers design, deploy, and manage ML workloads at scale. In his spare time, he enjoys traveling and exploring new places.
Marc Karp is an ML Architect with the Amazon SageMaker Service team. He focuses on helping customers design, deploy, and manage ML workloads at scale. In his spare time, he enjoys traveling and exploring new places.
 Shiva Raaj Kotini works as a Principal Product Manager in the Amazon SageMaker Inference product portfolio. He focuses on model deployment, performance tuning, and optimization in SageMaker for inference.
Shiva Raaj Kotini works as a Principal Product Manager in the Amazon SageMaker Inference product portfolio. He focuses on model deployment, performance tuning, and optimization in SageMaker for inference.
 Alwin (Qiyun) Zhao is a Senior Software Development Engineer with the Amazon SageMaker Inference Platform team. He is the lead developer of the deployment guardrails and shadow deployments, and he focuses on helping customers to manage ML workloads and deployments at scale with high availability. He also works on platform architecture evolutions for fast and secure ML jobs deployment and running ML online experiments at ease. In his spare time, he enjoys reading, gaming, and traveling.
Alwin (Qiyun) Zhao is a Senior Software Development Engineer with the Amazon SageMaker Inference Platform team. He is the lead developer of the deployment guardrails and shadow deployments, and he focuses on helping customers to manage ML workloads and deployments at scale with high availability. He also works on platform architecture evolutions for fast and secure ML jobs deployment and running ML online experiments at ease. In his spare time, he enjoys reading, gaming, and traveling.
 Gaurav Bhanderi is a Front End engineer with AI platforms team in SageMaker. He works on delivering Customer facing UI solutions within AWS org. In his free time, he enjoys hiking and exploring local restaurants.
Gaurav Bhanderi is a Front End engineer with AI platforms team in SageMaker. He works on delivering Customer facing UI solutions within AWS org. In his free time, he enjoys hiking and exploring local restaurants.
Author: Raghu Ramesha