

Significant new capabilities make it easier to use Amazon Bedrock to build and scale generative AI applications – and achieve impressive results
TutoSartup excerpt from this article:
We introduced Amazon Bedrock to the world a little over a year ago, delivering an entirely new way to build generative artificial intelligence (AI) applications... With the broadest selection of first- and third-party foundation models (FMs) as well as user-friendly capabilities, Amazon Bedrock is the fastest and easiest way to build and scale secure generative AI applications... Now tens of thous...
We introduced Amazon Bedrock to the world a little over a year ago, delivering an entirely new way to build generative artificial intelligence (AI) applications... With the broadest selection of first- and third-party foundation models (FMs) as well as user-friendly capabilities, Amazon Bedrock is the fastest and easiest way to build and scale secure generative AI applications... Now tens of thous...
US Q1 GDP Growth Looks Set For Slowdown In Thursday’s Release
TutoSartup excerpt from this article:
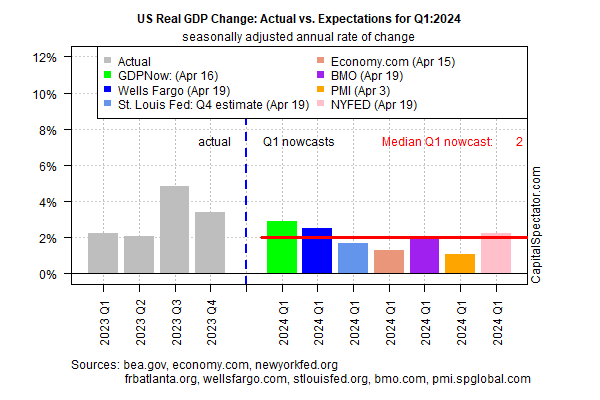
The US economy appears on track to post softer growth in the first-quarter GDP report scheduled for release on Thursday (Apr...The economy rose 3... Despite another round of softer growth, most estimates for the upcoming Q1 report — the initial estimate from the Bureau of Economic Analysis — indicate that the economy will continue to expand at a healthy pace that minimizes recession risk... ...
The US economy appears on track to post softer growth in the first-quarter GDP report scheduled for release on Thursday (Apr...The economy rose 3... Despite another round of softer growth, most estimates for the upcoming Q1 report — the initial estimate from the Bureau of Economic Analysis — indicate that the economy will continue to expand at a healthy pace that minimizes recession risk... ...
Building scalable, secure, and reliable RAG applications using Knowledge Bases for Amazon Bedrock
TutoSartup excerpt from this article:
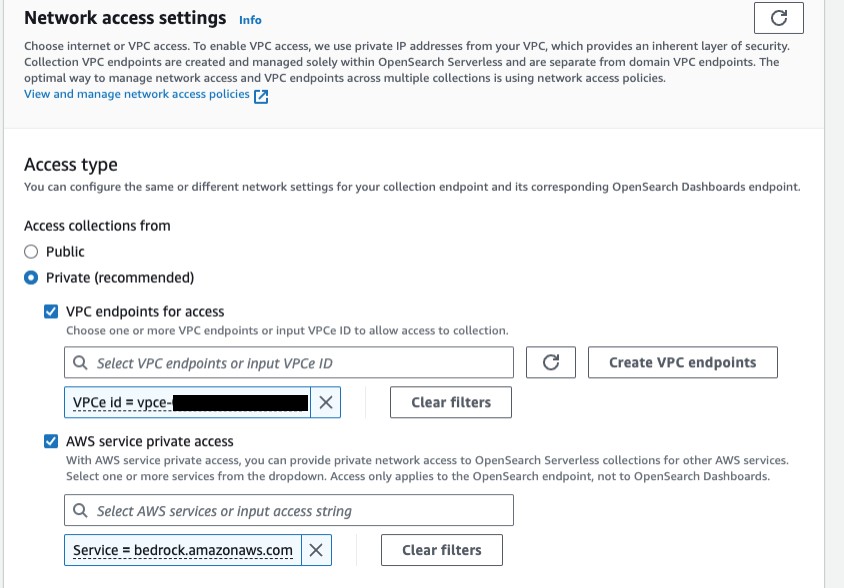
Security – Implementing strong access controls, encryption, and monitoring helps secure sensitive data used in your organization’s knowledge base and prevent misuse of generative AI... Here are some features which we will cover: AWS CloudFormation support Private network policies for Amazon OpenSearch Serverless Multiple S3 buckets as data sources Service Quotas support Hybrid ...
Security – Implementing strong access controls, encryption, and monitoring helps secure sensitive data used in your organization’s knowledge base and prevent misuse of generative AI... Here are some features which we will cover: AWS CloudFormation support Private network policies for Amazon OpenSearch Serverless Multiple S3 buckets as data sources Service Quotas support Hybrid ...
Meta’s Llama 3 models are now available in Amazon Bedrock
TutoSartup excerpt from this article:
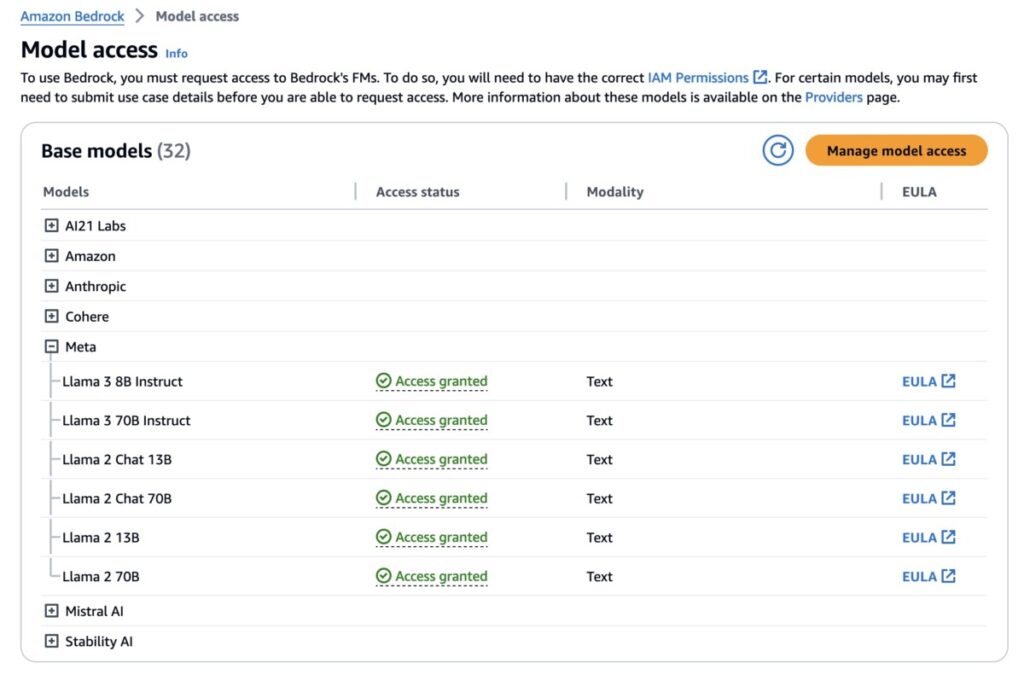
Today, we are announcing the general availability of Meta’s Llama 3 models in Amazon Bedrock... New Llama 3 models are the most capable to support a broad range of use cases with improvements in reasoning, code generation, and instruction... According to Meta’s Llama 3 announcement, the Llama 3 model family is a collection of pre-trained and instruction-tuned large language models (LLMs) in 8...
Today, we are announcing the general availability of Meta’s Llama 3 models in Amazon Bedrock... New Llama 3 models are the most capable to support a broad range of use cases with improvements in reasoning, code generation, and instruction... According to Meta’s Llama 3 announcement, the Llama 3 model family is a collection of pre-trained and instruction-tuned large language models (LLMs) in 8...
Guardrails for Amazon Bedrock now available with new safety filters and privacy controls
TutoSartup excerpt from this article:
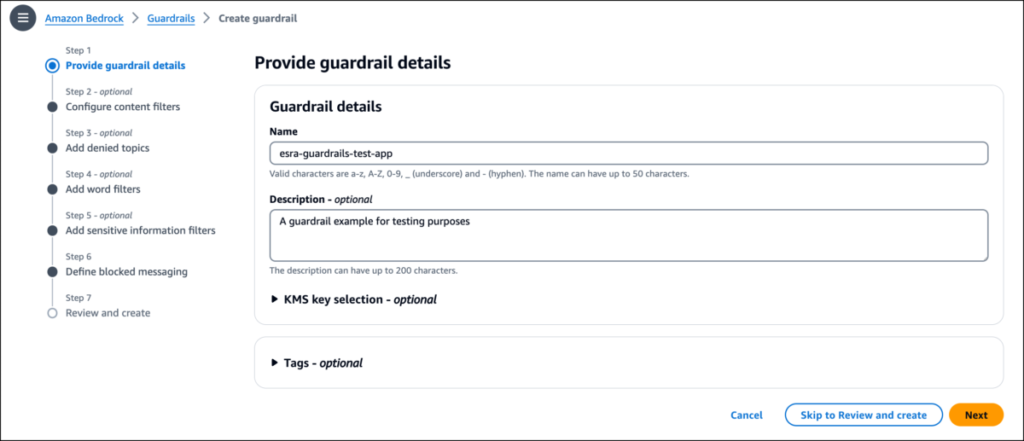
” In the preview post, Antje showed you how to use guardrails to configure thresholds to filter content across harmful categories and define a set of topics that need to be avoided in the context of your application... The Content filters feature now has two additional safety categories: Misconduct for detecting criminal activities and Prompt Attack for detecting prompt injection and jailbreak ...
” In the preview post, Antje showed you how to use guardrails to configure thresholds to filter content across harmful categories and define a set of topics that need to be avoided in the context of your application... The Content filters feature now has two additional safety categories: Misconduct for detecting criminal activities and Prompt Attack for detecting prompt injection and jailbreak ...
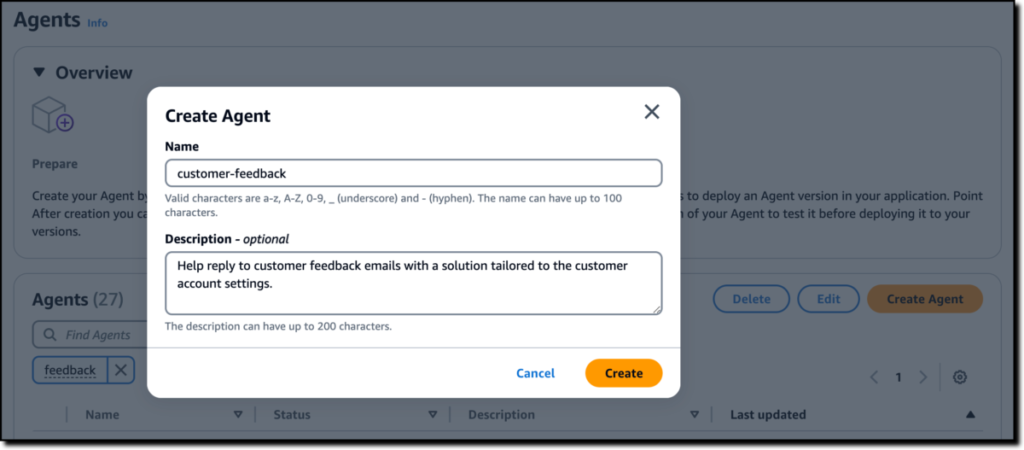
Agents for Amazon Bedrock: Introducing a simplified creation and configuration experience
TutoSartup excerpt from this article:
Starting today, these new capabilities streamline the creation and management of agents: Quick agent creation – You can now quickly create an agent and optionally add instructions and action groups later, providing flexibility and agility for your development process... Agent builder – All agent configurations can be operated in the new agent builder section of the console... Return of con...
Starting today, these new capabilities streamline the creation and management of agents: Quick agent creation – You can now quickly create an agent and optionally add instructions and action groups later, providing flexibility and agility for your development process... Agent builder – All agent configurations can be operated in the new agent builder section of the console... Return of con...
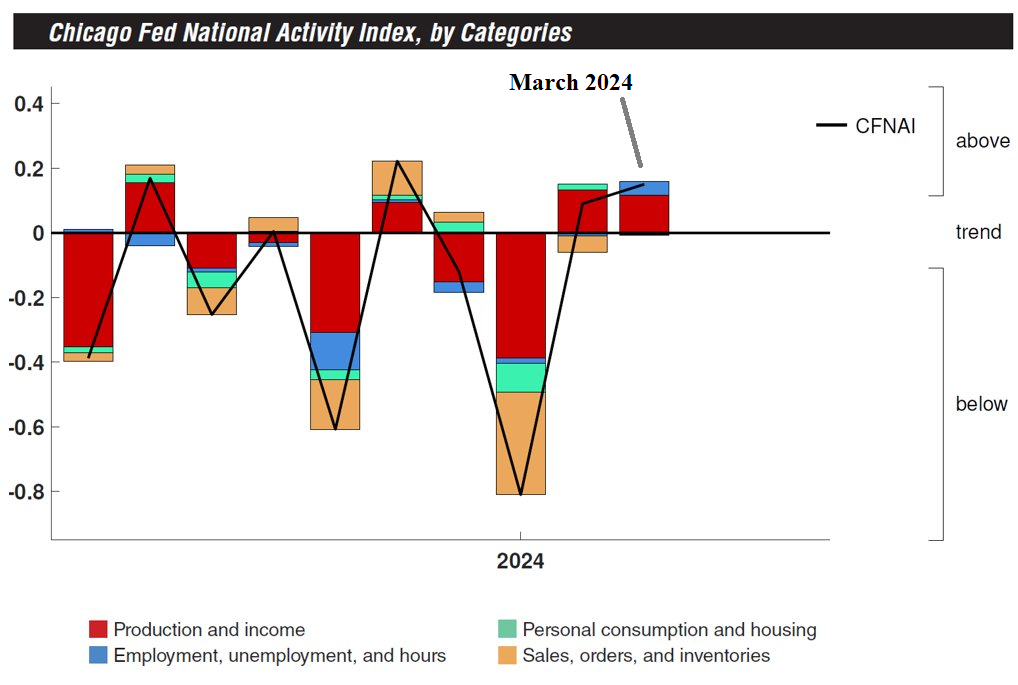
Macro Briefing: 23 April 2024
TutoSartup excerpt from this article:
* US considers sanctions targeting some Chinese banks supporting Russia * US stock market decline has “further to go,” predicts JPMorgan analyst * Tech sector looks frothy, says head of world’s largest sovereign wealth fund * Eurozone economy growing again for first time since May 2023: PMI survey * Risk-parity strategy takes a beating, persuading investors to bail * US economic growth stren...
* US considers sanctions targeting some Chinese banks supporting Russia * US stock market decline has “further to go,” predicts JPMorgan analyst * Tech sector looks frothy, says head of world’s largest sovereign wealth fund * Eurozone economy growing again for first time since May 2023: PMI survey * Risk-parity strategy takes a beating, persuading investors to bail * US economic growth stren...