

Prioritizing employee well-being: An innovative approach with generative AI and Amazon SageMaker Canvas
We delve into the following topics: The importance of mental health in the workplace An overview of the SageMaker Canvas low-code no-code platform for building machine learning (ML) models The mental health assessment model: Data preparation using the chat feature Training the …
In today’s fast-paced corporate landscape, employee mental health has become a crucial aspect that organizations can no longer overlook. Many companies recognize that their greatest asset lies in their dedicated workforce, and each employee plays a vital role in collective success. As such, promoting employee well-being by creating a safe, inclusive, and supportive environment is of utmost importance.
However, quantifying and assessing mental health can be a daunting task. Traditional methods like employee well-being surveys or manual approaches may not always provide the most accurate or actionable insights. In this post, we explore an innovative solution that uses Amazon SageMaker Canvas for mental health assessment at the workplace.
We delve into the following topics:
- The importance of mental health in the workplace
- An overview of the SageMaker Canvas low-code no-code platform for building machine learning (ML) models
- The mental health assessment model:
- Data preparation using the chat feature
- Training the model on SageMaker Canvas
- Model evaluation and performance metrics
- Deployment and integration:
- Deploying the mental health assessment model
- Integrating the model into workplace wellness programs or HR systems
In this post, we use a dataset from a 2014 survey that measures attitudes towards mental health and frequency of mental health disorders in the tech workplace, then we aggregate and prepare data for an ML model using Amazon SageMaker Data Wrangler for a tabular dataset on SageMaker Canvas. Then we train, build, test, and deploy the model using SageMaker Canvas, without writing any code.
Discover how SageMaker Canvas can revolutionize the way organizations approach employee mental health assessment, empowering them to create a more supportive and productive work environment. Stay tuned for insightful content that could reshape the future of workplace well-being.
Importance of mental health
Maintaining good mental health in the workplace is crucial for both employees and employers. In today’s fast-paced and demanding work environment, the mental well-being of employees can have a significant impact on productivity, job satisfaction, and overall company success. At Amazon, where innovation and customer obsession are at the core of our values, we understand the importance of fostering a mentally healthy workforce.
By prioritizing the mental well-being of our employees, we create an environment where they can thrive and contribute their best. This helps us deliver exceptional products and services. Amazon supports mental health by providing access to resources and support services. All U.S. employees and household members are eligible to receive five free counseling sessions, per issue every year, via Amazon’s Global Employee Assistance Program (EAP), Resources for Living. Employees can also access mental health care 24/7 through a partnership with the app Twill—a digital, self-guided mental health program. Amazon also partners with Brightline, a leading provider in virtual mental health support for children and teens.
Solution overview
SageMaker Canvas brings together a broad set of capabilities to help data professionals prepare, build, train, and deploy ML models without writing any code. SageMaker Data Wrangler has also been integrated into SageMaker Canvas, reducing the time it takes to import, prepare, transform, featurize, and analyze data. In a single visual interface, you can complete each step of a data preparation workflow: data selection, cleansing, exploration, visualization, and processing. Custom Spark commands can also expand the over 300 built-in data transformations. The built-in Data Quality and Insights report guides you in performing appropriate data cleansing, verifying data quality, and detecting anomalies such as duplicate rows and target leakage. Other analyses are also available to help you visualize and understand your data.
In this post, we try to understand the factors contributing to the mental health of an employee in the tech industry in a systematic manner. We begin by understanding the feature columns, presented in the following table.
| Survey Attribute | Survey Attribute Description |
Timestamp | Timestamp when survey was taken |
Age | Age of person taking survey |
Gender | Gender of person taking survey |
Country | Country of person taking survey |
state | If you live in the United States, which state or territory do you live in? |
self_employed | Are you self-employed? |
family_history | Do you have a family history of mental illness? |
treatment | Have you sought treatment for a mental health condition? |
work_interfere | If you have a mental health condition, do you feel that it interferes with your work? |
no_employees | How many employees does your company or organization have? |
remote_work | Do you work remotely (outside of an office) at least 50% of the time? |
tech_company | Is your employer primarily a tech company/organization? |
benefits | Does your employer provide mental health benefits? |
care_options | Do you know the options for mental health care your employer provides? |
wellness_program | Has your employer ever discussed mental health as part of an employee wellness program? |
seek_help | Does your employer provide resources to learn more about mental health issues and how to seek help? |
anonymity | Is your anonymity protected if you choose to take advantage of mental health or substance abuse treatment resources? |
leave | How easy is it for you to take medical leave for a mental health condition? |
mentalhealthconsequence | Do you think that discussing a mental health issue with your employer would have negative consequences? |
physhealthconsequence | Do you think that discussing a physical health issue with your employer would have negative consequences? |
coworkers | Would you be willing to discuss a mental health issue with your coworkers? |
physhealthinterview | Would you bring up a physical health issue with a potential employer in an interview? |
mentalvsphysical | Do you feel that your employer takes mental health as seriously as physical health? |
obs_consequence | Have you heard of or observed negative consequences for coworkers with mental health conditions in your workplace? |
comments | Any additional notes or comments |
Prerequisites
You should complete the following prerequisites before building this model:
- Have access to an AWS account
- Set up a SageMaker domain
- Download the sample dataset
Log in to SageMaker Canvas
When the initial setup is complete, you can access SageMaker Canvas with any of the following methods, depending on your environment’s setup:
- On the SageMaker console, choose Canvas in the navigation pane. Choose your user from the dropdown menu and launch the SageMaker Canvas application.
- To use Amazon SageMaker Studio, navigate to the SageMaker Studio interface. Go to the SageMaker Canvas page and launch the SageMaker Canvas application.
- You can also use your organization’s SAML 2.0-based single sign-on (SSO) methods, such as AWS IAM Identity Center. To learn more, see Secure access to Amazon SageMaker Studio with AWS SSO and a SAML application.
Import the dataset into SageMaker Canvas
In SageMaker Canvas, you can see quick actions to get started building and using ML and generative artificial intelligence (AI) models, with a no code platform. Feel free to explore any of the out-of-the-box models.
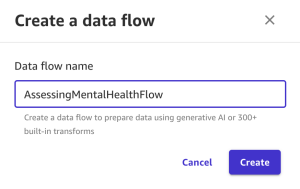
We start from creating a data flow. A data flow in SageMaker Canvas is used to build a data preparation pipeline that can be scheduled to automatically import, prepare, and feed into a model build. With a data flow, you can prepare data using generative AI, over 300 built-in transforms, or custom Spark commands.
Complete the following steps:
- Choose Prepare and analyze data.
- For Data flow name, enter a name (for example,
AssessingMentalHealthFlow). - Choose Create.
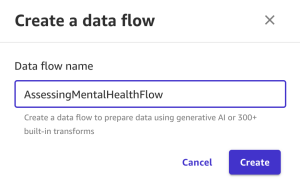
SageMaker Data Wrangler will open.
You can import data from multiple sources, ranging from AWS services, such as Amazon Simple Storage Service (Amazon S3) and Amazon Redshift, to third-party or partner services, including Snowflake or Databricks. To learn more about importing data to SageMaker Canvas, see Import data into Canvas.
- Choose Import data, then choose Tabular.
- Upload the dataset you downloaded in the prerequisites section.
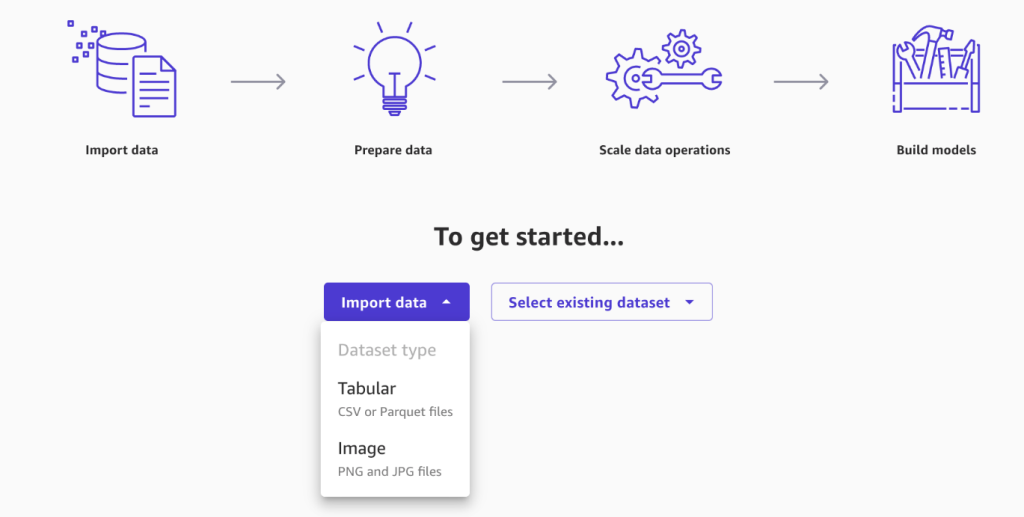
After a successful import, you will be presented with a preview of the data, which you can browse.
- Choose Import data to finish this step.
Run a Data Quality and Insights report
After you import the dataset, the SageMaker Data Wrangler data flow will open. You can run a Data Quality and Insights Report, which will perform an analysis of the data to determine potential issues to address during data preparation. Complete the following steps:
- Choose Run Data quality and insights report.
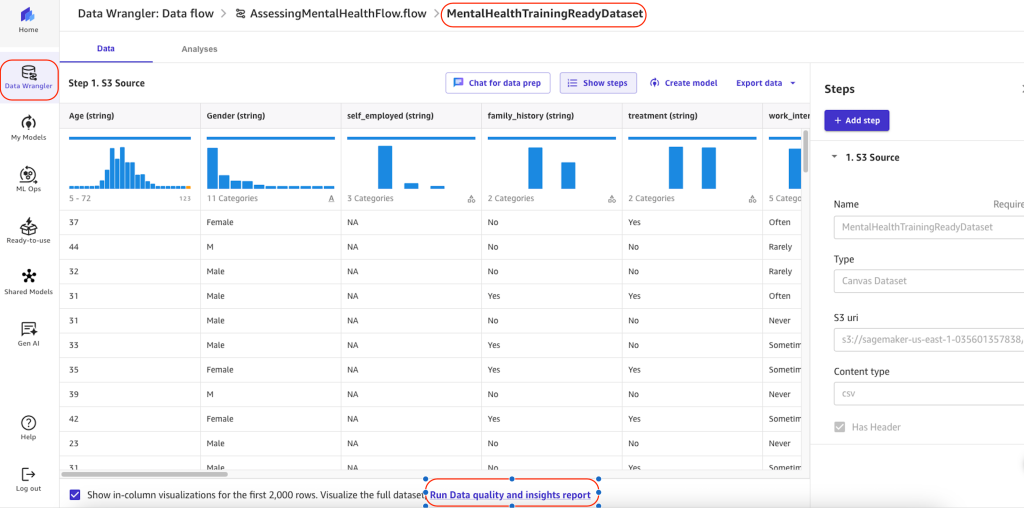
- For Analysis name, enter a name.
- For Target column, choose treatment.
- For Problem type, select Classification.
- For Data size, choose Sampled dataset.
- Choose Create.
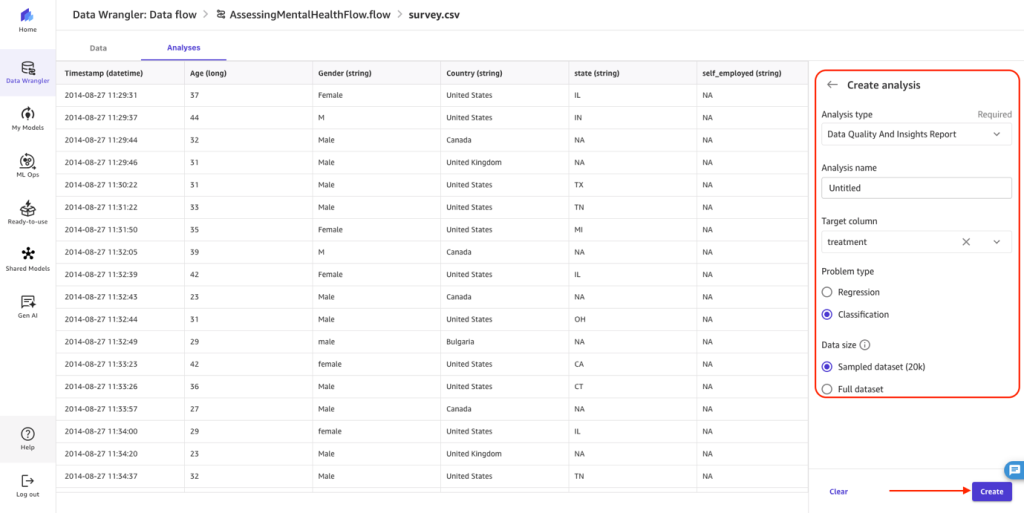
You are presented with the generated report, which details any high priority warnings, data issues, and other insights to be aware of as you add data transformations and move along the model building process.
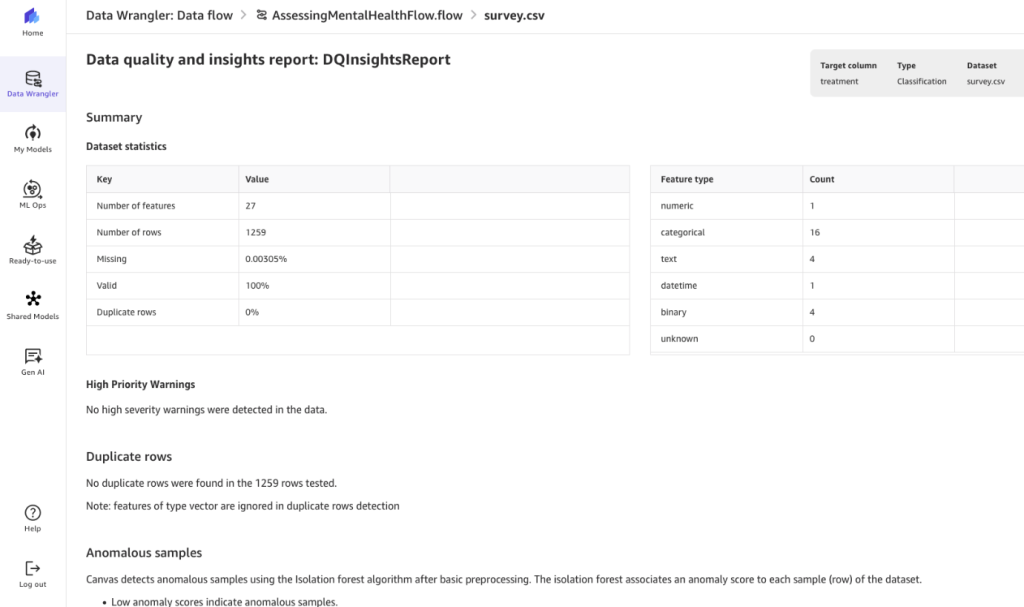
In this specific dataset, we can see that there are 27 features of different types, very little missing data, and no duplicates. To dive deeper into the report, refer to Get Insights On Data and Data Quality. To learn about other available analyzes, see Analyze and Visualize.
Prepare your data
As expected in the ML process, your dataset may require transformations to address issues such as missing values, outliers, or perform feature engineering prior to model building. SageMaker Canvas provides ML data transforms to clean, transform, and prepare your data for model building without having to write code. The transforms used are added to the model recipe, a record of the data preparation done on your data before building the model. You can refer to these advanced transformations and add them as transformation steps within your Data Wrangler flow.
Alternatively, you can use SageMaker Canvas to chat with your data and add transformations. We explore this option with some examples on our sample dataset.
Use the chat feature for exploratory analysis and building transformations
Before you use the chat feature to prepare data, note the following:
- Chat for data prep requires the
AmazonSageMakerCanvasAIServicesAccesspolicy. For more information, see AWS managed policy: AmazonSageMakerCanvasAIServicesAccess. - Chat for data prep requires access to Amazon Bedrock and the Anthropic Claude v2 model within it. For more information, see Model access.
- You must run SageMaker Canvas data prep in the same AWS Region as the Region where you’re running your model. Chat for data prep is available in the US East (N. Virginia), US West (Oregon), and Europe (Frankfurt) Regions.
To chat with your data, complete the following steps:
- Open your SageMaker Canvas data flow.
- Open your dataset by choosing Source or Data types.

- Choose Chat for data prep and specify your prompts in the chat window.
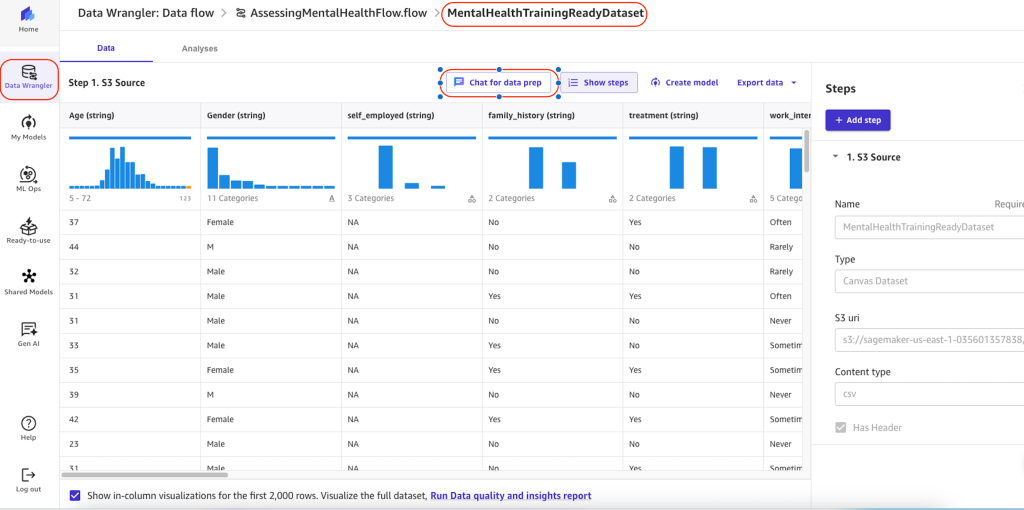
- Optionally, if an analysis has been generated by your query, choose Add to analyses to reference it for later.
- Optionally, if you’ve transformed your data using a prompt, do the following:
- Choose Preview to view the results.
- Optionally modify the code in the transform and choose Update.
- If you’re happy with the results of the transform, choose Add to steps to add it to the steps pane.
Let’s try a few exploratory analyses and transformations through the chat feature.
In the following example, we ask “How many rows does the dataset have?”

In the following example, we drop the columns Timestamp, Country, state, and comments, because these features will have least impact for classification of our model. Choose View code to see the generated Spark code that performs the transformation, then choose Add to steps to add the transformation to the data flow.
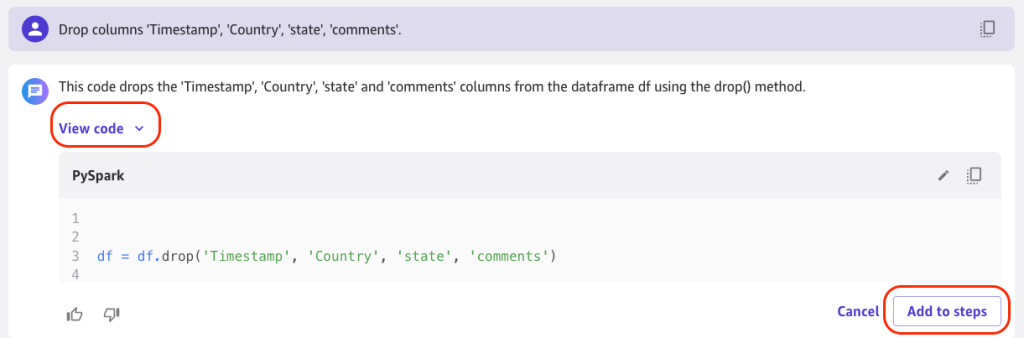
You can provide a name and choose Update to save the data flow.
In the next example, we ask “Show me all unique ages sorted.”
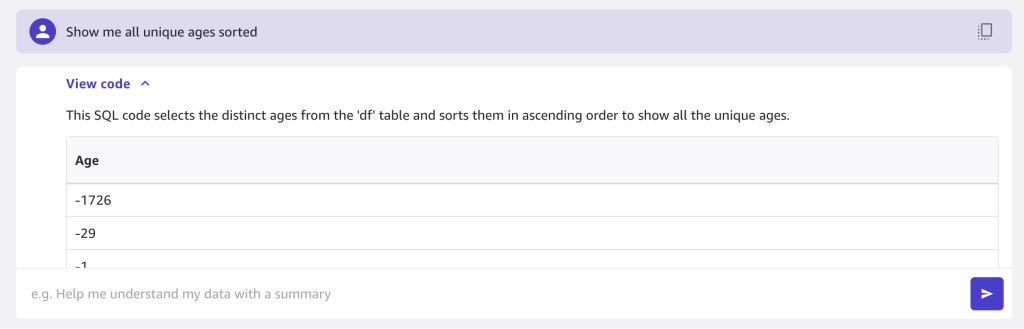
Some ages are negative, so we should filter on valid ages. We drop rows with age below 0 or more than 100 and add this to the steps.

In the following example, we ask “Create a bar chart for null values in the dataset.”
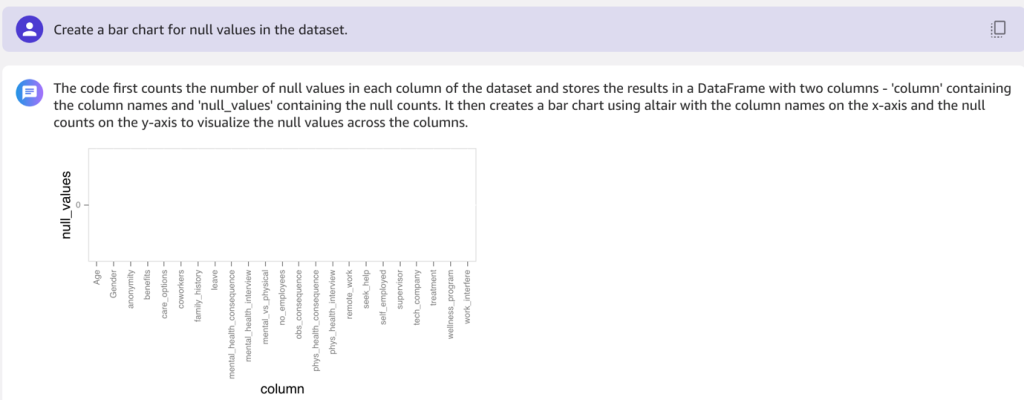
Then we ask for a bar chart for the treatment column.
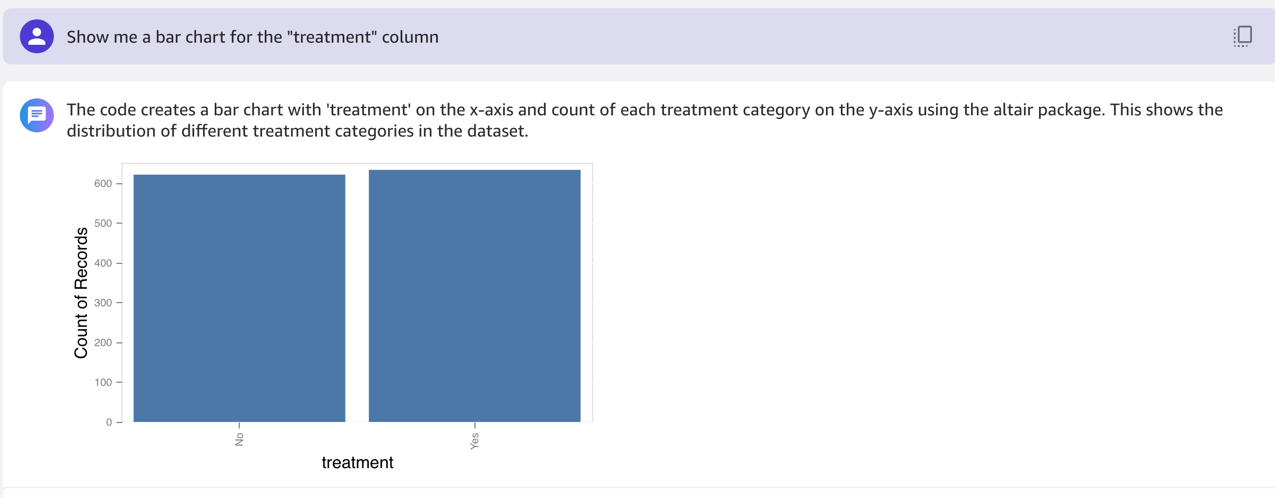
In the following example, we ask for a bar chart for the work_interfere column.
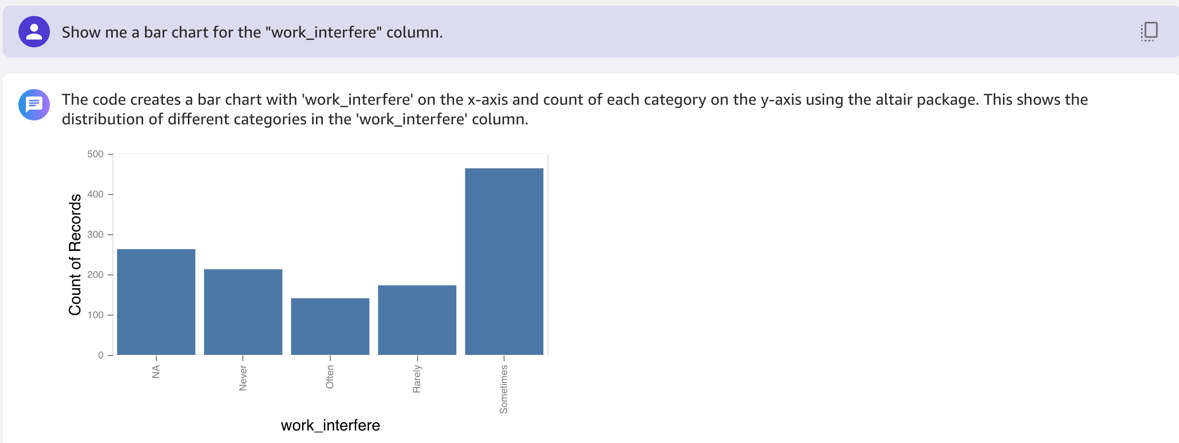
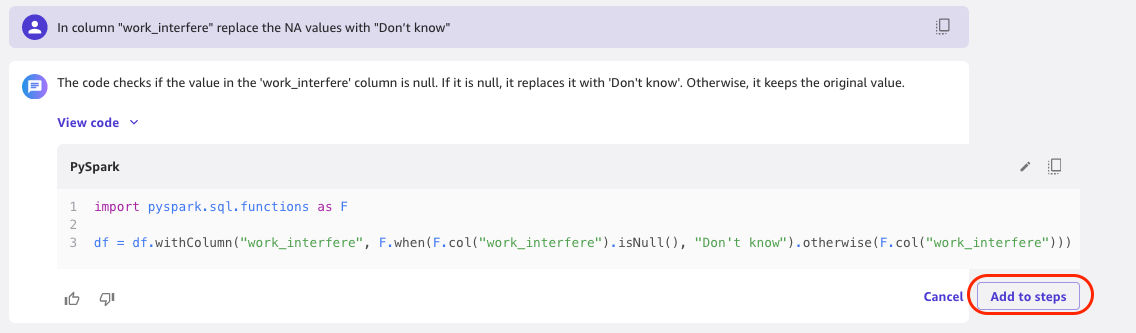
In the column work_interfere, we replace the NA values with “Don’t know.” We want to make the model weight missing values just as it weights people that have replied “Don’t know.”
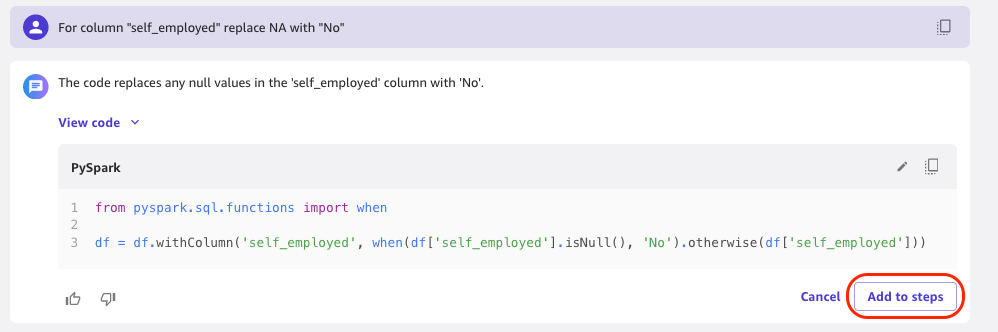
For the column self_employed, we want to replace NA with “No” to make the model weight missing values just as it weights people that have replied “NA.”
You can choose to add any other transformations as needed. If you’ve followed the preceding transformations, your steps should look like the following screenshot.
![]()
Perform an analysis on the transformed data
Now that transformations have been done on the data, you may want to perform analyses to make sure they haven’t affected data integrity.
To do so, navigate to the Analyses tab to create an analysis. For this example, we create a feature correlation analysis with the correlation type linear.
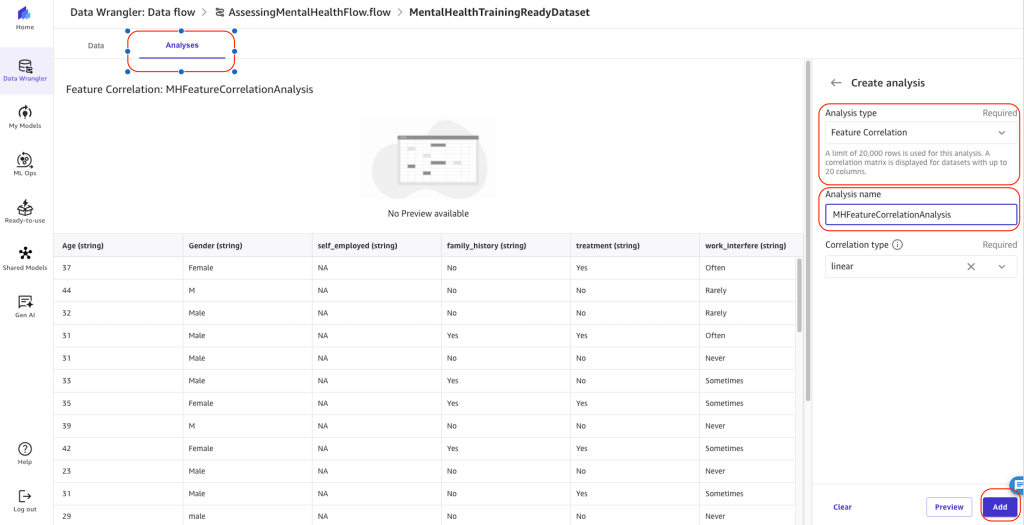
The analysis report will generate a correlation matrix. The correlation matrix measures the positive or negative correlation of features among themselves, between each other. A value closer to 1 means positive correlation, and a value closer to -1 means negative correlation.
Linear feature correlation is based on Pearson’s correlation. To find the relationship between a numeric variable (like age or income) and a categorical variable (like gender or education level), we first assign numeric values to the categories in a way that allows them to best predict the numeric variable. Then we calculate the correlation coefficient, which measures how strongly the two variables are related.
Linear categorical to categorical correlation is not supported.
Numeric to numeric correlation is in the range [-1, 1], where 0 implies no correlation, 1 implies perfect correlation, and -1 implies perfect inverse correlation. Numeric to categorical and categorical to categorical correlations are in the range [0, 1], where 0 implies no correlation and 1 implies perfect correlation.
Features that are not either numeric or categorical are ignored.
The following table lists for each feature what is the most correlated feature to it.
| Feature | Most Correlated Feature | Correlation |
|---|---|---|
Age (numeric) | Gender (categorical) | 0.248216 |
Gender (categorical) | Age (numeric) | 0.248216 |
seek_help (categorical) | Age (numeric) | 0.175808 |
no_employees (categorical) | Age (numeric) | 0.166486 |
benefits (categorical) | Age (numeric) | 0.157729 |
remote_work (categorical) | Age (numeric) | 0.139105 |
care_options (categorical) | Age (numeric) | 0.1183 |
wellness_program (categorical) | Age (numeric) | 0.117175 |
phys_health_consequence (categorical) | Age (numeric) | 0.0961159 |
work_interfere (categorical) | Age (numeric) | 0.0797424 |
treatment (categorical) | Age (numeric) | 0.0752661 |
mental_health_consequence (categorical) | Age (numeric) | 0.0687374 |
obs_consequence (categorical) | Age (numeric) | 0.0658778 |
phys_health_interview (categorical) | Age (numeric) | 0.0639178 |
self_employed (categorical) | Age (numeric) | 0.0628861 |
tech_company (categorical) | Age (numeric) | 0.0609773 |
leave (categorical) | Age (numeric) | 0.0601671 |
mental_health_interview (categorical) | Age (numeric) | 0.0600251 |
mental_vs_physical (categorical) | Age (numeric) | 0.0389857 |
anonymity (categorical) | Age (numeric) | 0.038797 |
coworkers (categorical) | Age (numeric) | 0.0181036 |
supervisor (categorical) | Age (numeric) | 0.0167315 |
family_history (categorical) | Age (numeric) | 0.00989271 |
The following figure shows our correlation matrix.

You can explore more analyses of different types. For more details, see Explore your data using visualization techniques.
Export the dataset and create a model
Return to the main data flow and run the SageMaker Data Wrangler validation flow. Upon successful validation, you are ready to export the dataset for model training.
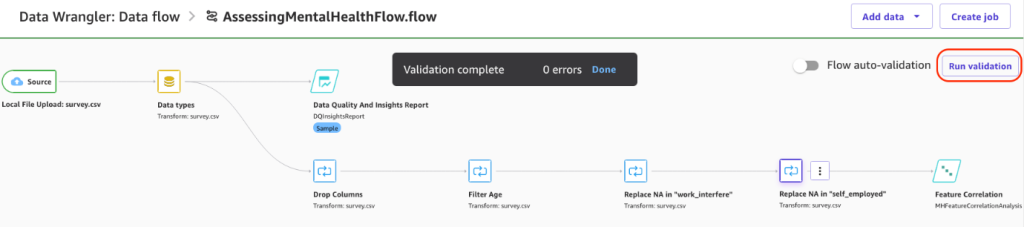
Next, you export your dataset and build an ML model on top of it. Complete the following steps:
- Open the expanded menu in the final transformation and choose Create model.
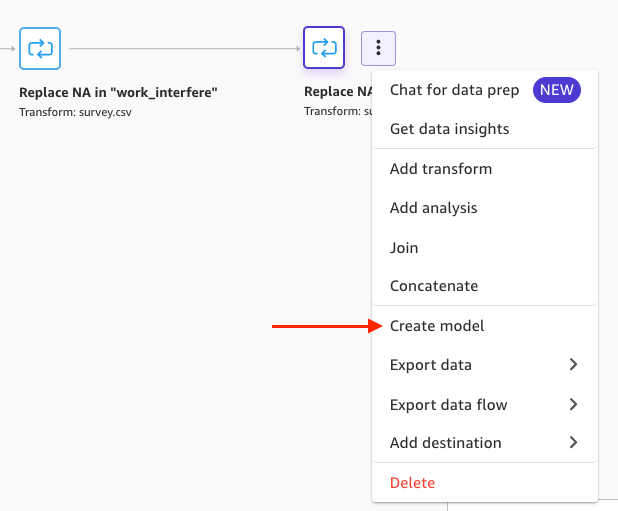
- For Dataset name, enter a name.
- Choose Export.
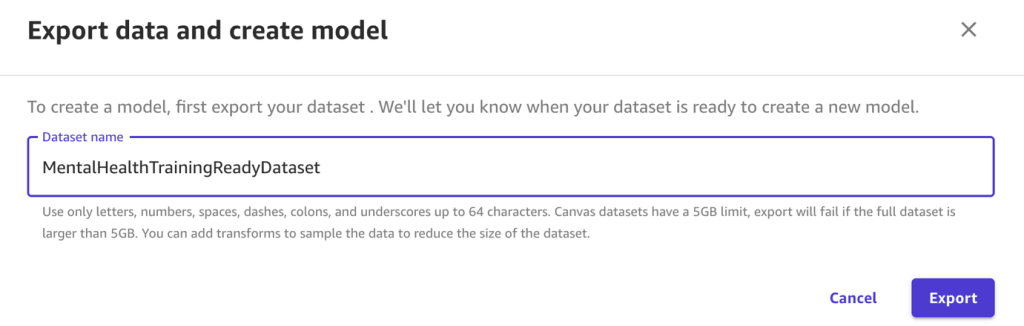
At this point, your mental health assessment dataset is ready for model training and testing.
- Choose Create model.

- For Model name, enter a name.
- For Problem type, select Predictive analysis.
SageMaker Canvas suggested this based on the dataset, but you can override this for your own experimentation. For more information about ready-to-use models provided by SageMaker Canvas, see Use Ready-to-use models.
- Choose Create.
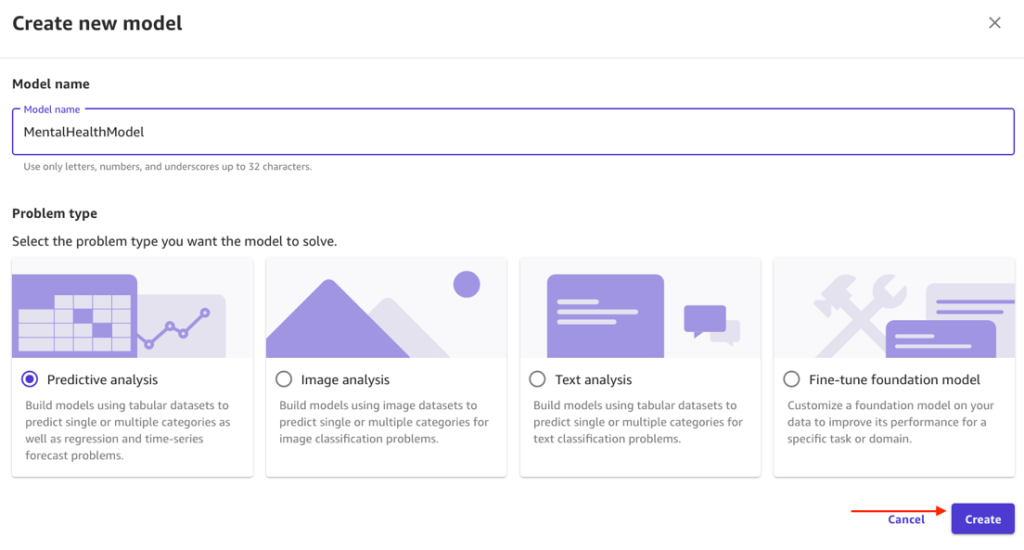
- For Target column, choose treatment as the column to predict.
Because Yes or No is predicted, SageMaker Canvas detected this is a two-category prediction model.
- Choose Configure model to set configurations.
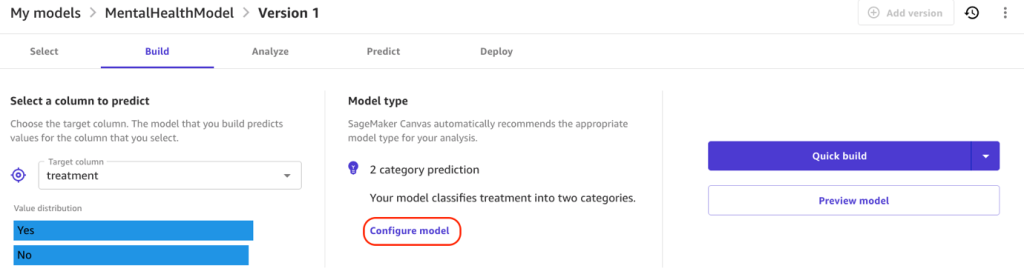
- For Objective metric, leave as the default F1.
F1 averages two important metrics: precision and recall.
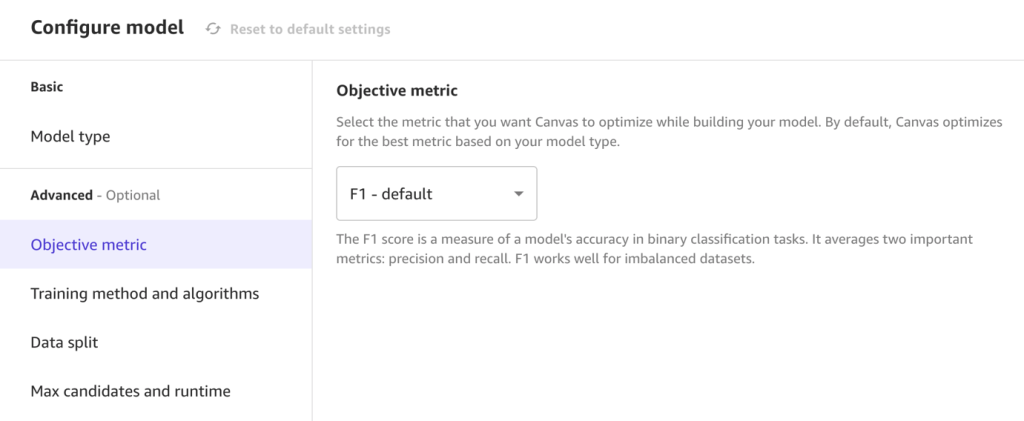
- For Training method, select Auto.
This option selects the algorithm most relevant to your dataset and the best range of hyperparameters to tune model candidates. Alternatively, you could use the ensemble or hyperparameter optimization training options. For more information, see Training modes and algorithm support.
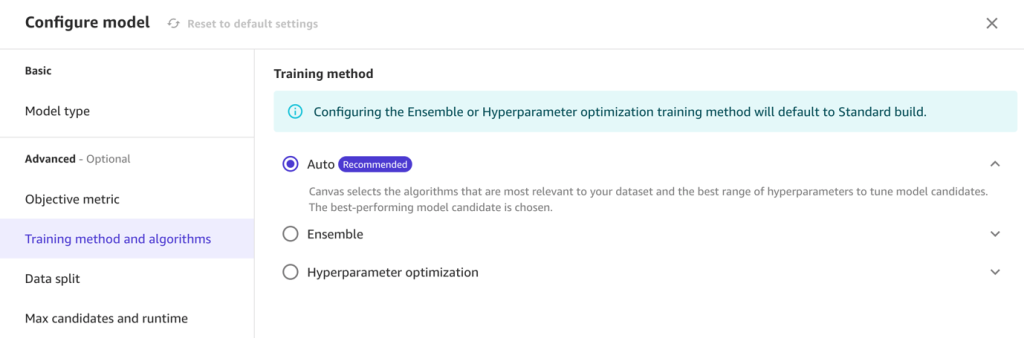
- For Data split, specify an 80/20 configuration for training and validation, respectively.
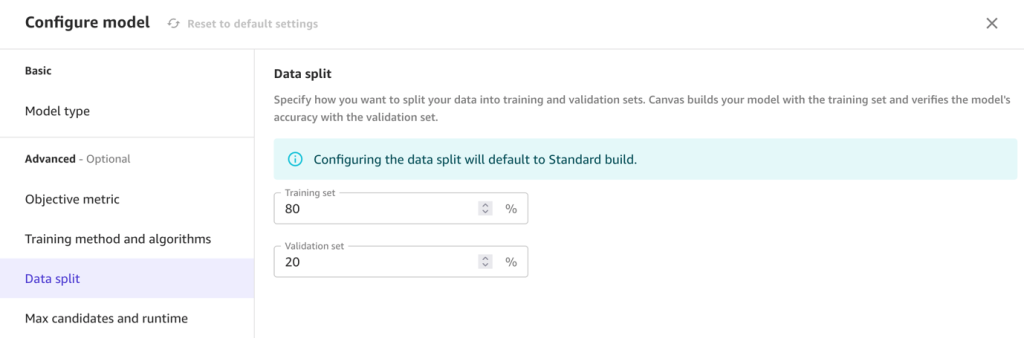
- Choose Save and then Preview model to generate a preview.
This preview runs on subset of data and provides information on estimated model accuracy and feature importance. Based on the results, you may still apply additional transformations to improve the estimated accuracy.
Although low impact features might add noise to the model, these may still be useful to describe situations specific to your use case. Always combine predictive power with your own context to determine which features to include.
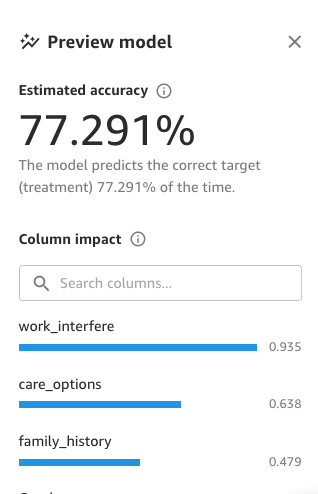
You’re now ready to build the full model with either Quick build or Standard build. Quick build only supports datasets with fewer than 50,000 rows and prioritizes speed over accuracy, training fewer combinations of models and hyperparameters, for rapid prototyping or proving out value. Standard build prioritizes accuracy and is necessary for exporting the full Jupyter notebook used for training.
- For this post, choose Standard build.

To learn more about how SageMaker Canvas uses training and validation datasets, see Evaluating Your Model’s Performance in Amazon SageMaker Canvas and SHAP Baselines for Explainability.
Your results may differ from those in this post. Machine learning introduces stochasticity in the model training process, which can lead to slight variations.

Here, we’ve built a model that will predict with about 87% accuracy whether an individual will seek mental health treatment. At this stage, think about how you could achieve a practical impact from the Machine Learning model. For example, here an organization may consider how they can apply the model to preemptively support individuals who’s attributes suggest they would seek treatment.
Review model metrics
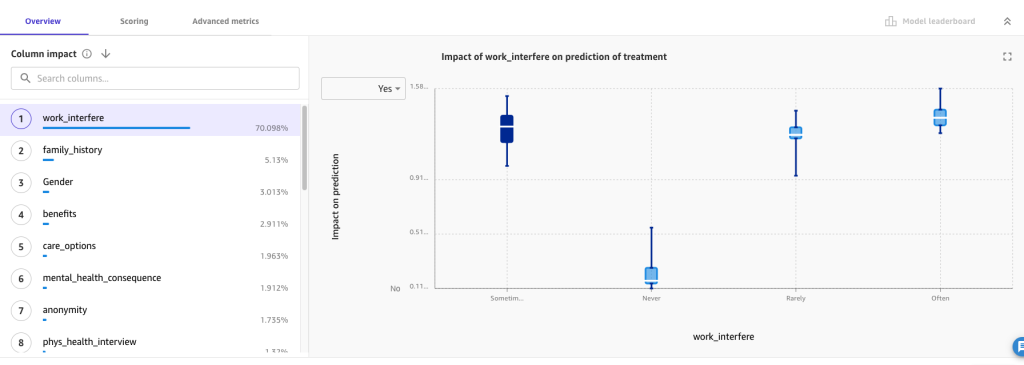
Let’s focus on the first tab, Overview. Here, Column impact is the estimated importance of each attribute in predicting the target. Information here can help organizations gain insights that lead to actions based on the model. For example, we see that the work_interfere column has the most significant impact in predication for treatment. Additionally, better benefits and care_options increase the likelihood of employees opting in to treatment.
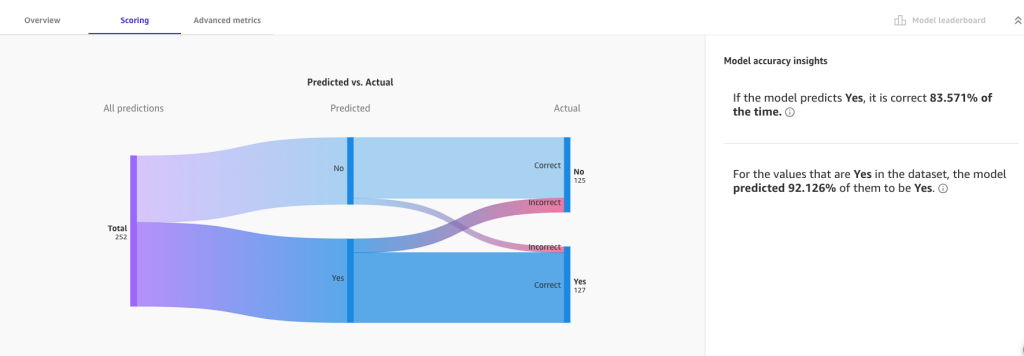
On the Scoring tab, we can visualize a Sankey (or ribbon) plot of the distribution of predicted values with respect to actual values, providing insight into how the model performed during validation.
For more detailed insights, we look at the Advanced metrics tab for metric values the model may have not been optimized for, the confusion matrix, and precision recall curve.
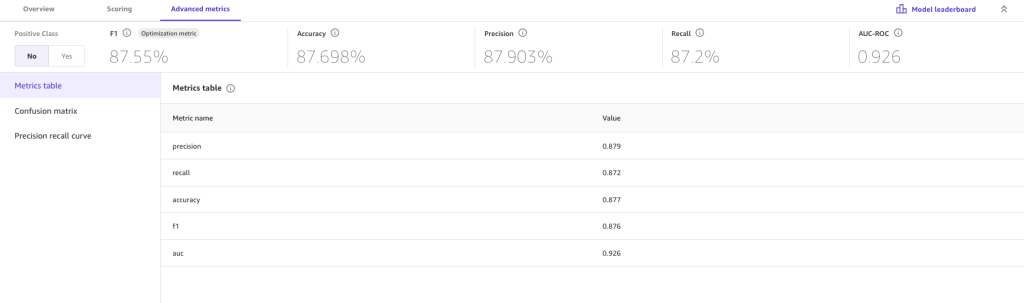
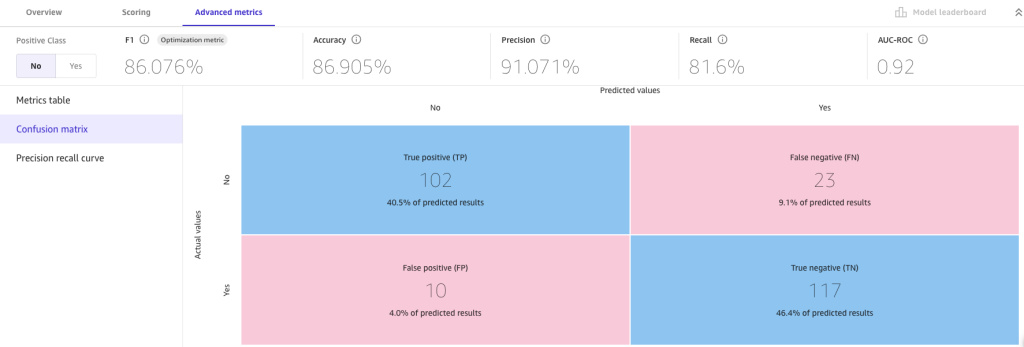
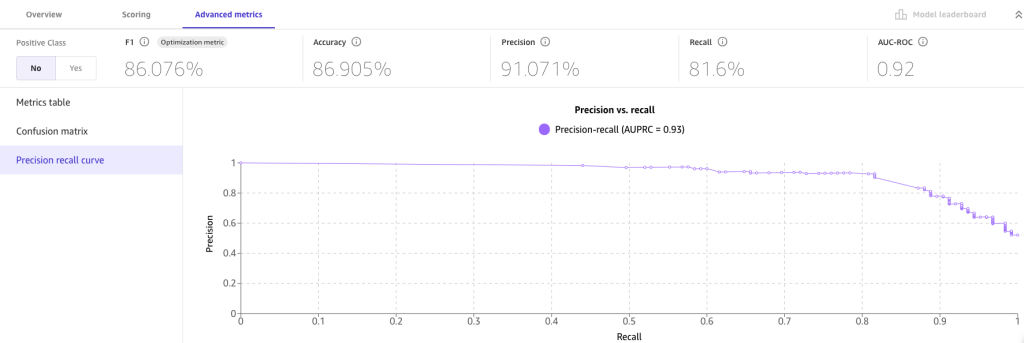
The advanced metrics suggest we can trust the resulting model. False positives (predicting an employee will opt in for treatment when they actually don’t) and false negatives (predicting an employee will opt out when they actually opt in) are low. High numbers for either may make us skeptical about the current build and more likely to revisit previous steps.
Test the model
Now let’s use the model for making predictions. Choose Predict to navigate to the Predict tab. SageMaker Canvas allows you to generate predictions in two forms:
- Single prediction (single “what-if scenario”)
- Batch prediction (multiple scenarios using a CSV file)
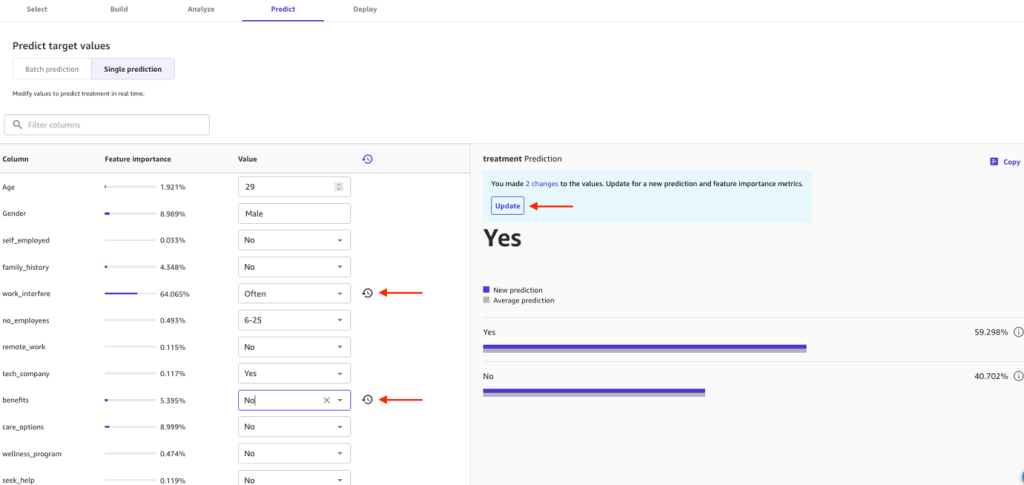
For a first test, let’s try a single prediction. Wait a few seconds for the model to load, and now you’re ready to generate new inferences. You can change the values to experiment with the attributes and their impact.
For example, let’s make the following updates:
- Change work_interfere from Often to Sometimes
- Change benefits from Yes to No
Choose Update and see if the treatment prediction is affected.
In SageMaker Canvas, you can generate batch predictions either manually or automatically on a schedule. Let’s try the manual approach. To learn about automating batch predictions, refer to Automate batch predictions.
- In practice, use a dataset different from training for testing predictions. For this example though, lets use the same file as before. Be sure to remove the work_interfere column.
- Choose Batch prediction and upload the downloaded file.
- Choose Generate predictions.
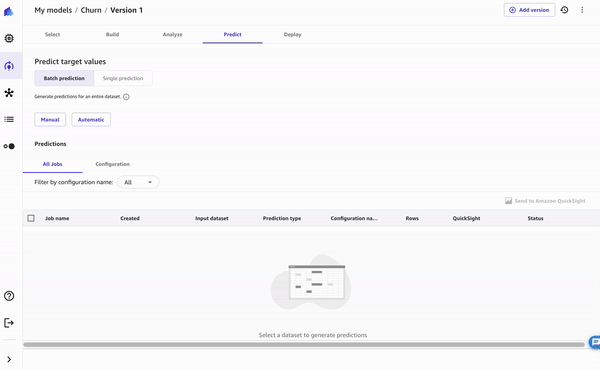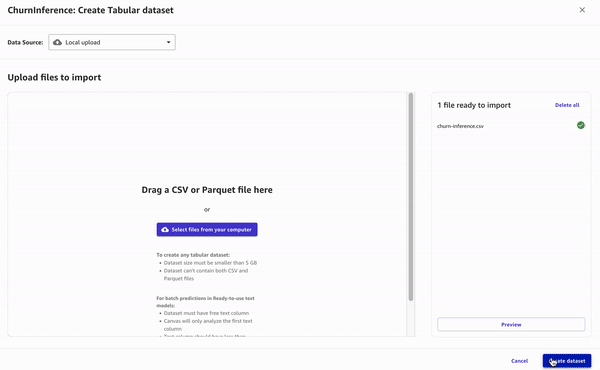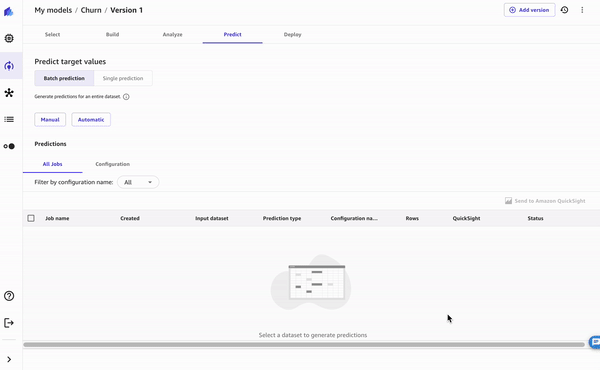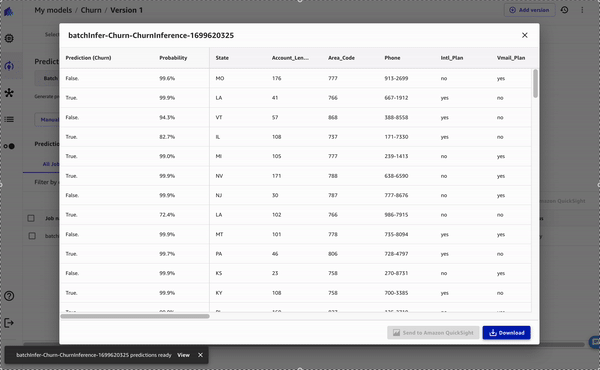
- When it’s complete, choose View to see the predictions.
Deploy the model
The final (optional) step of the SageMaker Canvas workflow for ML models is deploying the model. This uses SageMaker real-time inference endpoints to host the SageMaker Canvas model and expose an HTTPS endpoint for use by applications or developers.
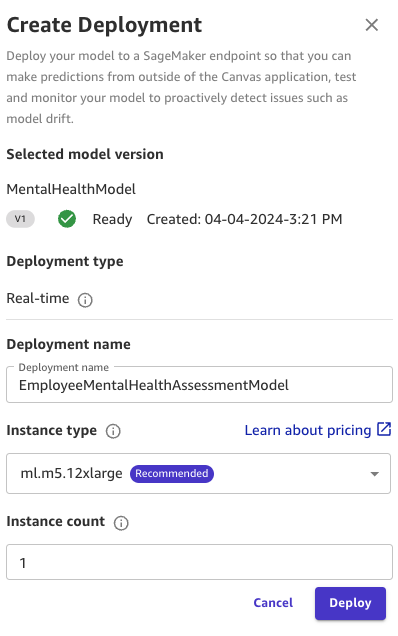
- On the Deploy tab, choose Create deployment.
- For Deployment name, enter a name.
- For Instance type, choose an instance (for this post, ml.m5.2xlarge).
- Set Instance count to 1.
- Choose Deploy.
This instance configuration is sufficient for the demo. You can change the configuration later from the SageMaker Canvas UI or using SageMaker APIs. To learn more about auto scaling such workloads, see Automatically Scale Amazon SageMaker Models.
After the deployment is successful, you can invoke the endpoint using AWS SDKs or direct HTTPs calls. For more information, see Deploy models for real-time inference.
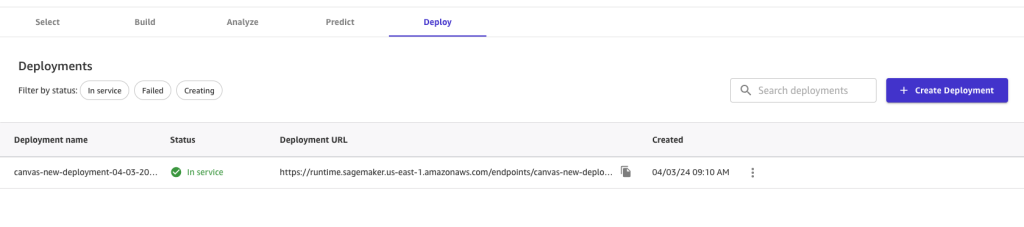
To learn more about model deployment, refer to Deploy your Canvas models to a SageMaker Endpoint and Deploy models for real-time inference.
Clean up
Make sure to log out from SageMaker Canvas by choosing Log out. Logging out of the SageMaker Canvas application will release all resources used by the workspace instance, therefore avoiding incurring additional unintended charges.
Summary
Mental health is a dynamic and evolving field, with new research and insights constantly emerging. Staying up to date with the latest developments and best practices can be challenging, especially in a public forum. Additionally, when discussing mental health, it’s essential to approach the topic with sensitivity, respect, and a commitment to providing accurate and helpful information.
In this post, we showcased an ML approach to building a mental health model using a sample dataset and SageMaker Canvas, a low-code no-code platform from AWS. This can serve as guidance for organizations looking to explore similar solutions for their specific needs. Implementing AI to assess employee mental health and offer preemptive support can yield a myriad of benefits. By promoting detection of potential mental health needs, intervention can be more personalized and reduce the risk of drastic complications in the future. A proactive approach can also enhance employee morale and productivity, mitigating the likelihood of absenteeism, turnover and ultimately leads to a healthier and more resilient workforce.. Overall, using AI for mental health prediction and support signifies a commitment to nurturing a supportive work environment where employees can thrive.
To explore more about SageMaker Canvas with industry-specific use cases, explore a hands-on workshop. To learn more about SageMaker Data Wrangler in SageMaker Canvas, refer to Prepare Data. You can also refer to the following YouTube video to learn more about the end-to-end ML workflow with SageMaker Canvas.
Although this post provides a technical perspective, we strongly encourage readers who are struggling with mental health issues to seek professional help. Remember, there is always help available for those who ask.
Together, let’s take a proactive step towards empowering mental health awareness and supporting those in need.
About the Authors
 Rushabh Lokhande is a Senior Data & ML Engineer with AWS Professional Services Analytics Practice. He helps customers implement big data, machine learning, analytics solutions, and generative AI implementations. Outside of work, he enjoys spending time with family, reading, running, and playing golf.
Rushabh Lokhande is a Senior Data & ML Engineer with AWS Professional Services Analytics Practice. He helps customers implement big data, machine learning, analytics solutions, and generative AI implementations. Outside of work, he enjoys spending time with family, reading, running, and playing golf.
 Bruno Klein is a Senior Machine Learning Engineer with AWS Professional Services Analytics Practice. He helps customers implement big data analytics solutions and generative AI implementations. Outside of work, he enjoys spending time with family, traveling, and trying new food.
Bruno Klein is a Senior Machine Learning Engineer with AWS Professional Services Analytics Practice. He helps customers implement big data analytics solutions and generative AI implementations. Outside of work, he enjoys spending time with family, traveling, and trying new food.
 Ryan Gomes is a Senior Data & ML Engineer with AWS Professional Services Analytics Practice. He is passionate about helping customers achieve better outcomes through analytics, machine learning, and generative AI solutions in the cloud. Outside of work, he enjoys fitness, cooking, and spending quality time with friends and family.
Ryan Gomes is a Senior Data & ML Engineer with AWS Professional Services Analytics Practice. He is passionate about helping customers achieve better outcomes through analytics, machine learning, and generative AI solutions in the cloud. Outside of work, he enjoys fitness, cooking, and spending quality time with friends and family.
Author: Rushabh Lokhande