

Reduce Amazon SageMaker inference cost with AWS Graviton
In this post, we focus on how you can take advantage of the AWS Graviton3-based Amazon Elastic Compute Cloud (EC2) C7g instances to help reduce inference costs by up to 50% relative to comparable EC2 instances for real-time inference on Amazon SageMaker… We show how you can evaluate the inference…
Amazon SageMaker provides a broad selection of machine learning (ML) infrastructure and model deployment options to help meet your ML inference needs. It’s a fully-managed service and integrates with MLOps tools so you can work to scale your model deployment, reduce inference costs, manage models more effectively in production, and reduce operational burden. SageMaker provides multiple inference options so you can pick the option that best suits your workload.
New generations of CPUs offer a significant performance improvement in ML inference due to specialized built-in instructions. In this post, we focus on how you can take advantage of the AWS Graviton3-based Amazon Elastic Compute Cloud (EC2) C7g instances to help reduce inference costs by up to 50% relative to comparable EC2 instances for real-time inference on Amazon SageMaker. We show how you can evaluate the inference performance and switch your ML workloads to AWS Graviton instances in just a few steps.
To cover the popular and broad range of customer applications, in this post we discuss the inference performance of PyTorch, TensorFlow, XGBoost, and scikit-learn frameworks. We cover computer vision (CV), natural language processing (NLP), classification, and ranking scenarios for models and ml.c6g, ml.c7g, ml.c5, and ml.c6i SageMaker instances for benchmarking.
Benchmarking results
AWS measured up to 50% cost savings for PyTorch, TensorFlow, XGBoost, and scikit-learn model inference with AWS Graviton3-based EC2 C7g instances relative to comparable EC2 instances on Amazon SageMaker. At the same time, the latency of inference is also reduced.
For comparison, we used four different instance types:
All four instances have 16 vCPUs and 32 GiB of memory.
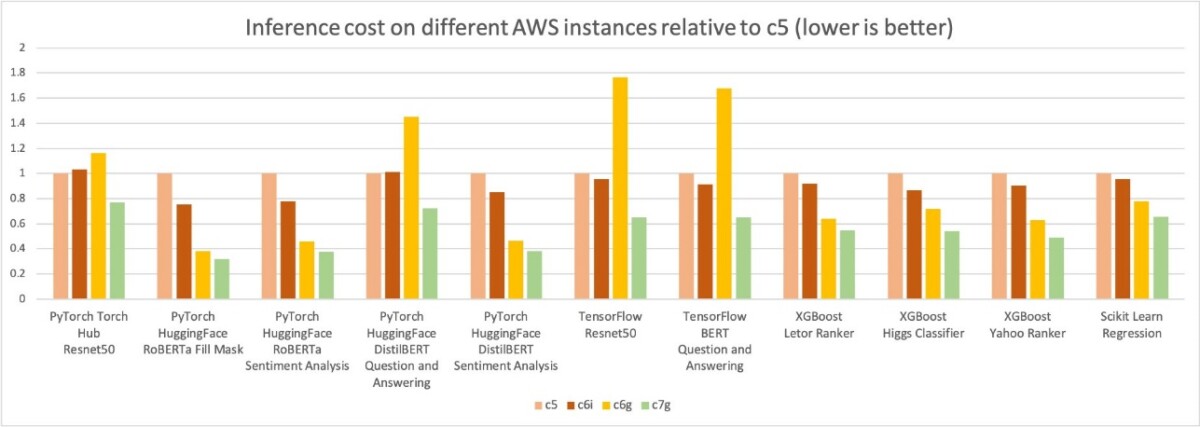
In the following graph, we measured the cost per million inference for the four instance types. We further normalized the cost per million inference results to a c5.4xlarge instance, which is measured as 1 on the Y-axis of the chart. You can see that for the XGBoost models, cost per million inference for c7g.4xlarge (AWS Graviton3) is about 50% of the c5.4xlarge and 40% of c6i.4xlarge; for the PyTorch NLP models, the cost savings is about 30–50% compared to c5 and c6i.4xlarge instances. For other models and frameworks, we measured at least 30% cost savings compared to c5 and c6i.4xlarge instances.

Similar to the preceding inference cost comparison graph, the following graph shows the model p90 latency for the same four instance types. We further normalized the latency results to the c5.4xlarge instance, which is measured as 1 in the Y-axis of the chart. The c7g.4xlarge (AWS Graviton3) model inference latency is up to 50% better than the latencies measured on c5.4xlarge and c6i.4xlarge.

Migrate to AWS Graviton instances
To deploy your models to AWS Graviton instances, you can either use AWS Deep Learning Containers (DLCs) or bring your own containers that are compatible with the ARMv8.2 architecture.
The migration (or new deployment) of your models to AWS Graviton instances is straightforward because not only does AWS provide containers to host models with PyTorch, TensorFlow, scikit-learn, and XGBoost, but the models are architecturally agnostic as well. You can also bring your own libraries, but be sure that your container is built with an environment that supports the ARMv8.2 architecture. For more information, see Building your own algorithm container.
You will need to complete three steps in order to deploy your model:
- Create a SageMaker model. This will contain, among other parameters, the information about the model file location, the container that will be used for the deployment, and the location of the inference script. (If you have an existing model already deployed in a compute optimized inference instance, you can skip this step.)
- Create an endpoint configuration. This will contain information about the type of instance you want for the endpoint (for example, ml.c7g.xlarge for AWS Graviton3), the name of the model you created in the previous step, and the number of instances per endpoint.
- Launch the endpoint with the endpoint configuration created in the previous step.
For detailed instructions, refer to Run machine learning inference workloads on AWS Graviton-based instances with Amazon SageMaker
Benchmarking methodology
We used Amazon SageMaker Inference Recommender to automate performance benchmarking across different instances. This service compares the performance of your ML model in terms of latency and cost on different instances and recommends the instance and configuration that gives the best performance for the lowest cost. We have collected the aforementioned performance data using Inference Recommender. For more details, refer to the GitHub repo.
You can use the sample notebook to run the benchmarks and reproduce the results. We used the following models for benchmarking:
- PyTorch – ResNet50 image classification, DistilBERT sentiment analysis, RoBERTa fill mask, and RoBERTa sentiment analysis
- TensorFlow – TF Hub ResNet 50 and ML Commons TensorFlow BERT
- XGBoost and scikit-learn – We tested four models to cover the classifiers, rankers, and linear regression scenarios
Conclusion
AWS measured up to 50% cost savings for PyTorch, TensorFlow, XGBoost, and scikit-learn model inference with AWS Graviton3-based EC2 C7g instances relative to comparable EC2 instances on Amazon SageMaker. You can migrate your existing inference use cases or deploy new ML models on AWS Graviton by following the steps provided in this post. You can also refer to the AWS Graviton Technical Guide, which provides the list of optimized libraries and best practices that will help you achieve cost benefits with AWS Graviton instances across different workloads.
If you find use cases where similar performance gains are not observed on AWS Graviton, please reach out us. We will continue to add more performance improvements to make AWS Graviton the most cost-effective and efficient general-purpose processor for ML inference.
About the authors
 Sunita Nadampalli is a Software Development Manager at AWS. She leads Graviton software performance optimizations for machine learning, HPC, and multimedia workloads. She is passionate about open-source development and delivering cost-effective software solutions with Arm SoCs.
Sunita Nadampalli is a Software Development Manager at AWS. She leads Graviton software performance optimizations for machine learning, HPC, and multimedia workloads. She is passionate about open-source development and delivering cost-effective software solutions with Arm SoCs.
 Jaymin Desai is a Software Development Engineer with the Amazon SageMaker Inference team. He is passionate about taking AI to the masses and improving the usability of state-of-the-art AI assets by productizing them into features and services. In his free time, he enjoys exploring music and traveling.
Jaymin Desai is a Software Development Engineer with the Amazon SageMaker Inference team. He is passionate about taking AI to the masses and improving the usability of state-of-the-art AI assets by productizing them into features and services. In his free time, he enjoys exploring music and traveling.
 Mike Schneider is a Systems Developer, based in Phoenix AZ. He is a member of Deep Learning containers, supporting various Framework container images, to include Graviton Inference. He is dedicated to infrastructure efficiency and stability.
Mike Schneider is a Systems Developer, based in Phoenix AZ. He is a member of Deep Learning containers, supporting various Framework container images, to include Graviton Inference. He is dedicated to infrastructure efficiency and stability.
 Mohan Gandhi is a Senior Software Engineer at AWS. He has been with AWS for the last 10 years and has worked on various AWS services like EMR, EFA and RDS. Currently, he is focused on improving the SageMaker Inference Experience. In his spare time, he enjoys hiking and marathons.
Mohan Gandhi is a Senior Software Engineer at AWS. He has been with AWS for the last 10 years and has worked on various AWS services like EMR, EFA and RDS. Currently, he is focused on improving the SageMaker Inference Experience. In his spare time, he enjoys hiking and marathons.
 Qingwei Li is a Machine Learning Specialist at Amazon Web Services. He received his Ph.D. in Operations Research after he broke his advisor’s research grant account and failed to deliver the Nobel Prize he promised. Currently he helps customers in financial service and insurance industry build machine learning solutions on AWS. In his spare time, he likes reading and teaching.
Qingwei Li is a Machine Learning Specialist at Amazon Web Services. He received his Ph.D. in Operations Research after he broke his advisor’s research grant account and failed to deliver the Nobel Prize he promised. Currently he helps customers in financial service and insurance industry build machine learning solutions on AWS. In his spare time, he likes reading and teaching.
 Wayne Toh is a Specialist Solutions Architect for Graviton at AWS. He focuses on helping customers adopt ARM architecture for large scale container workloads. Prior to joining AWS, Wayne worked for several large software vendors, including IBM and Red Hat.
Wayne Toh is a Specialist Solutions Architect for Graviton at AWS. He focuses on helping customers adopt ARM architecture for large scale container workloads. Prior to joining AWS, Wayne worked for several large software vendors, including IBM and Red Hat.
 Lauren Mullennex is a Solutions Architect based in Denver, CO. She works with customers to help them architect solutions on AWS. In her spare time, she enjoys hiking and cooking Hawaiian cuisine.
Lauren Mullennex is a Solutions Architect based in Denver, CO. She works with customers to help them architect solutions on AWS. In her spare time, she enjoys hiking and cooking Hawaiian cuisine.
Author: Sunita Nadampalli