

Scale your machine learning workloads on Amazon ECS powered by AWS Trainium instances

Containers can fully encapsulate not just your training code, but the entire dependency stack down to the hardware libraries and drivers… In late 2022, AWS announced the general availability of Amazon EC2 Trn1 instances powered by AWS Trainium accelerators, which are purpose built for high-perfo…
Running machine learning (ML) workloads with containers is becoming a common practice. Containers can fully encapsulate not just your training code, but the entire dependency stack down to the hardware libraries and drivers. What you get is an ML development environment that is consistent and portable. With containers, scaling on a cluster becomes much easier.
In late 2022, AWS announced the general availability of Amazon EC2 Trn1 instances powered by AWS Trainium accelerators, which are purpose built for high-performance deep learning training. Trn1 instances deliver up to 50% savings on training costs over other comparable Amazon Elastic Compute Cloud (Amazon EC2) instances. Also, the AWS Neuron SDK was released to improve this acceleration, giving developers tools to interact with this technology such as to compile, runtime, and profile to achieve high-performance and cost-effective model trainings.
Amazon Elastic Container Service (Amazon ECS) is a fully managed container orchestration service that simplifies your deployment, management, and scaling of containerized applications. Simply describe your application and the resources required, and Amazon ECS will launch, monitor, and scale your application across flexible compute options with automatic integrations to other supporting AWS services that your application needs.
In this post, we show you how to run your ML training jobs in a container using Amazon ECS to deploy, manage, and scale your ML workload.
Solution overview
We walk you through the following high-level steps:
- Provision an ECS cluster of Trn1 instances with AWS CloudFormation.
- Build a custom container image with the Neuron SDK and push it to Amazon Elastic Container Registry (Amazon ECR).
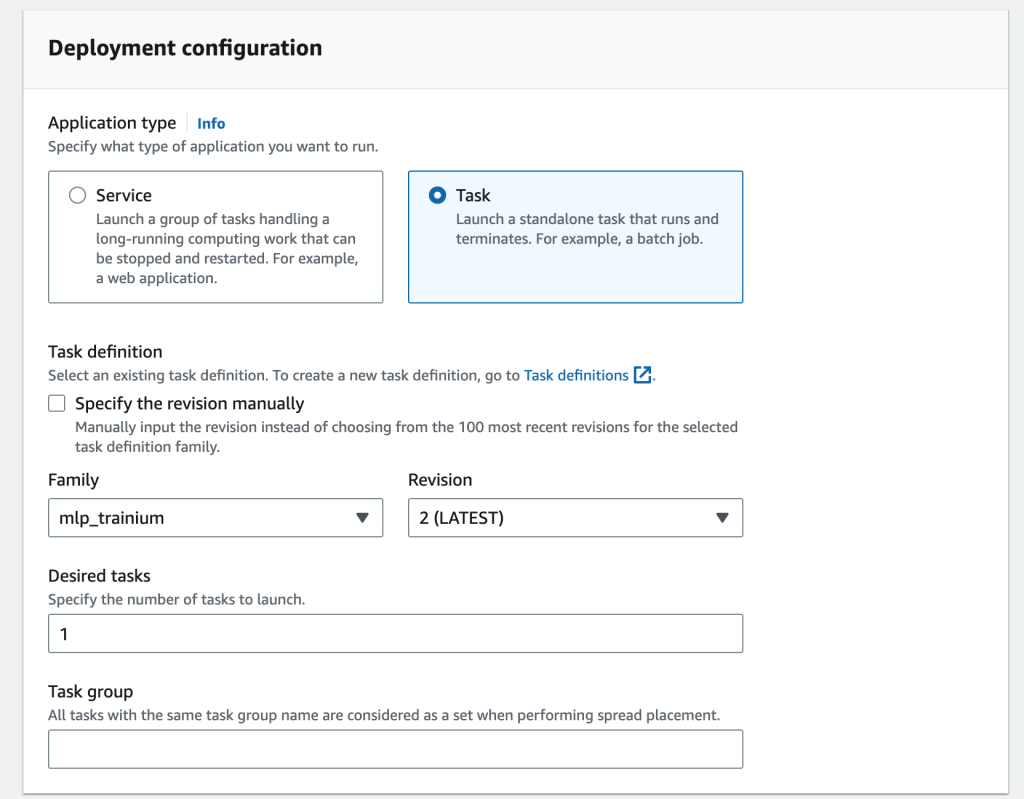
- Create a task definition to define an ML training job to be run by Amazon ECS.
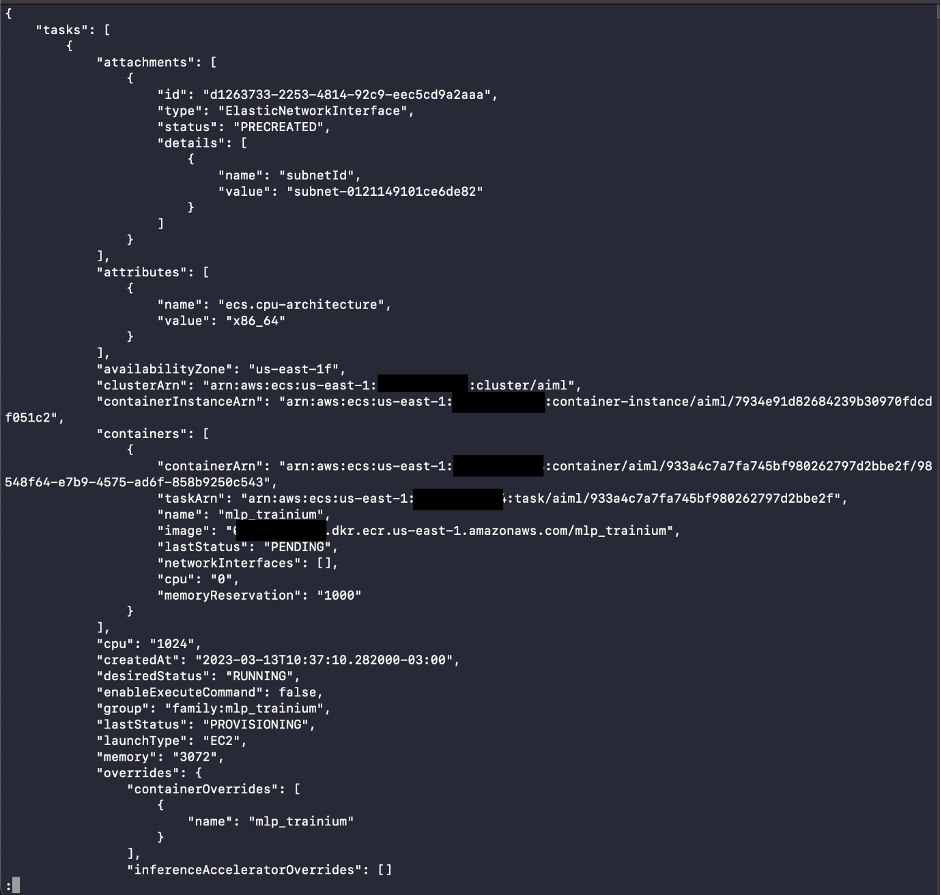
- Run the ML task on Amazon ECS.
Prerequisites
To follow along, familiarity with core AWS services such as Amazon EC2 and Amazon ECS is implied.
Provision an ECS cluster of Trn1 instances
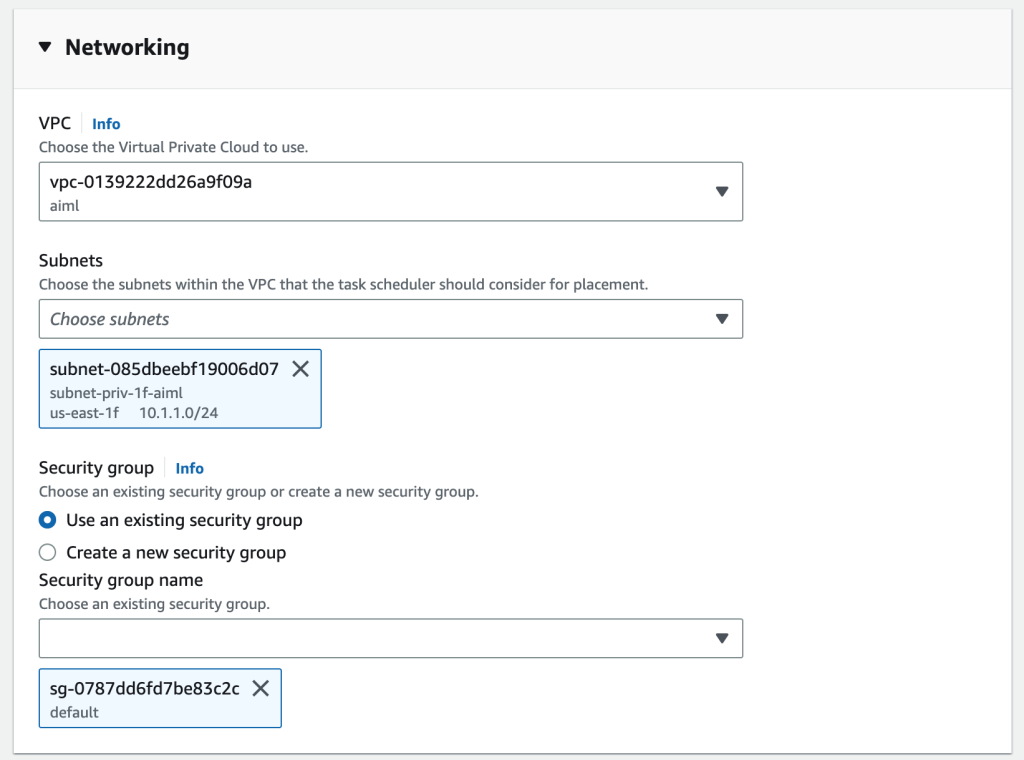
To get started, launch the provided CloudFormation template, which will provision required resources such as a VPC, ECS cluster, and EC2 Trainium instance.
We use the Neuron SDK to run deep learning workloads on AWS Inferentia and Trainium-based instances. It supports you in your end-to-end ML development lifecycle to create new models, optimize them, then deploy them for production. To train your model with Trainium, you need to install the Neuron SDK on the EC2 instances where the ECS tasks will run to map the NeuronDevice associated with the hardware, as well as the Docker image that will be pushed to Amazon ECR to access the commands to train your model.
Standard versions of Amazon Linux 2 or Ubuntu 20 don’t come with AWS Neuron drivers installed. Therefore, we have two different options.
The first option is to use a Deep Learning Amazon Machine Image (DLAMI) that has the Neuron SDK already installed. A sample is available on the GitHub repo. You can choose a DLAMI based on the opereating system. Then run the following command to get the AMI ID:
The output will be as follows:
ami-06c40dd4f80434809
This AMI ID can change over time, so make sure to use the command to get the right AMI ID.
Now you can change this AMI ID in the CloudFormation script and use the ready-to-use Neuron SDK. To do this, look for EcsAmiId in Parameters:
The second option is to create an instance filling the userdata field during stack creation. You don’t need to install it because CloudFormation will set this up. For more information, refer to the Neuron Setup Guide.
For this post, we use option 2, in case you need to use a custom image. Complete the following steps:
- Launch the provided CloudFormation template.
- For KeyName, enter a name of your desired key pair, and it will preload the parameters. For this post, we use
trainium-key. - Enter a name for your stack.
- If you’re running in the
us-east-1Region, you can keep the values for ALBName and AZIds at their default.
To check what Availability Zone in the Region has Trn1 available, run the following command:

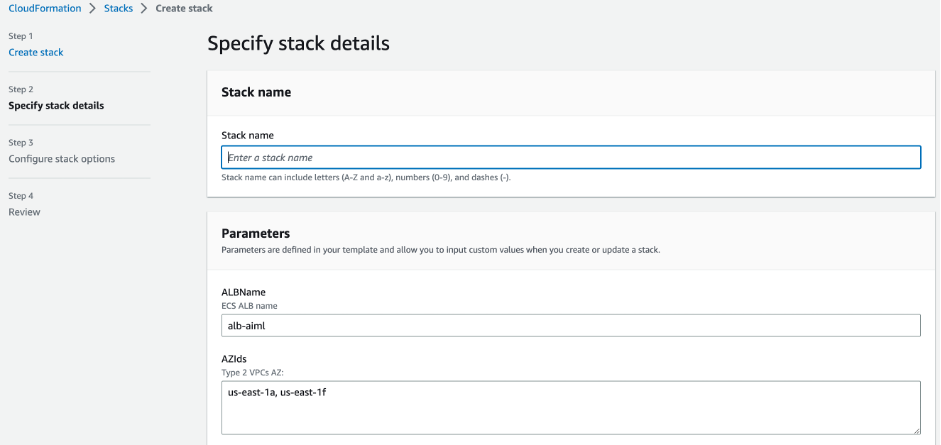
- Choose Next and finish creating the stack.
When the stack is complete, you can move to the next step.
Prepare and push an ECR image with the Neuron SDK
Amazon ECR is a fully managed container registry offering high-performance hosting, so you can reliably deploy application images and artifacts anywhere. We use Amazon ECR to store a custom Docker image containing our scripts and Neuron packages needed to train a model with ECS jobs running on Trn1 instances. You can create an ECR repository using the AWS Command Line Interface (AWS CLI) or AWS Management Console. For this post, we use the console. Complete the following steps:
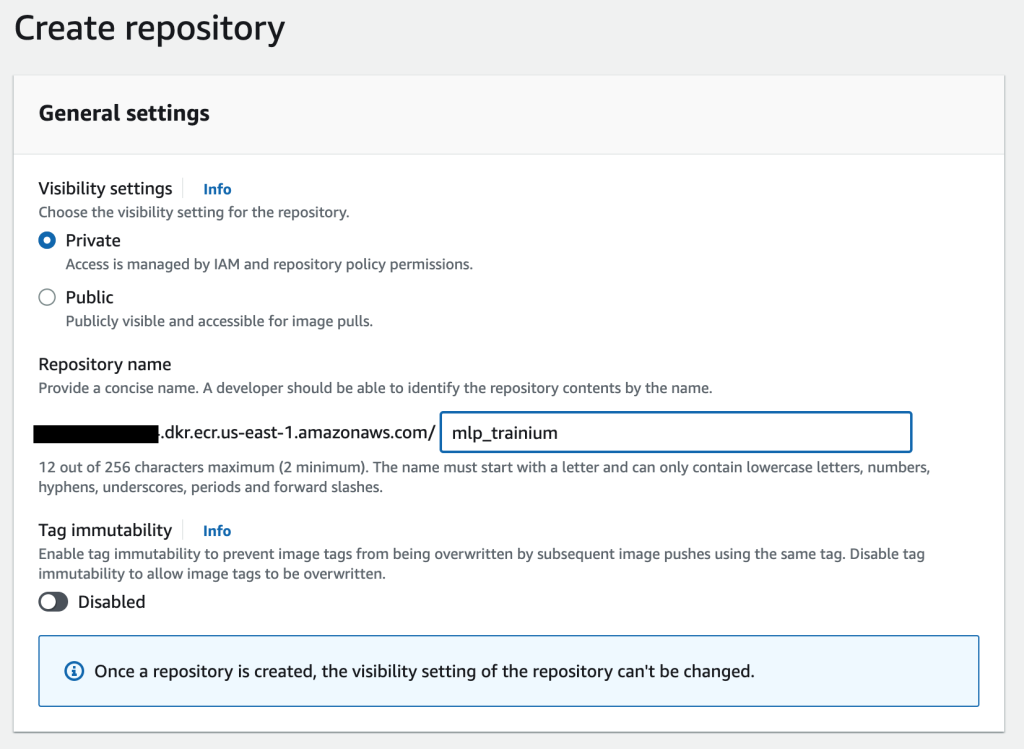
- On the Amazon ECR console, create a new repository.
- For Visibility settings¸ select Private.
- For Repository name, enter a name.
- Choose Create repository.
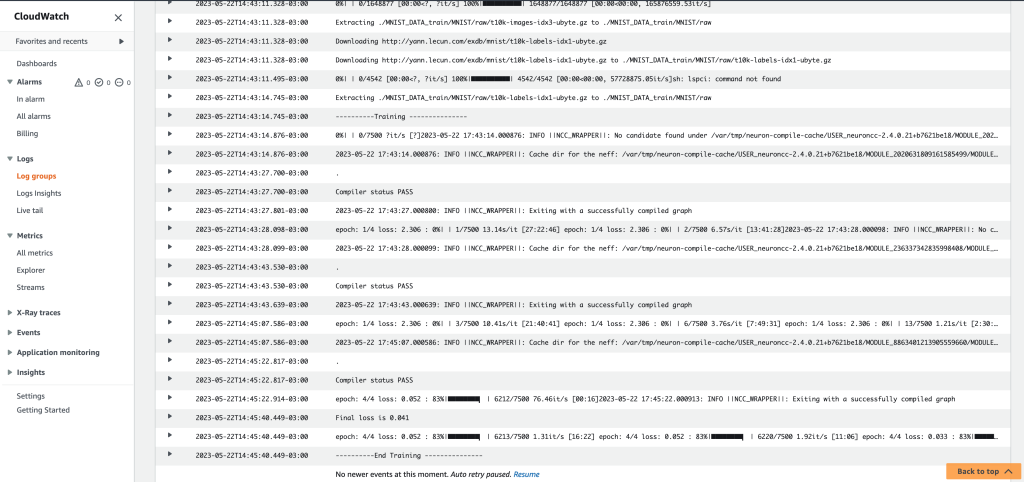
Now that you have a repository, let’s build and push an image, which could be built locally (into your laptop) or in a AWS Cloud9 environment. We are training a multi-layer perceptron (MLP) model. For the original code, refer to Multi-Layer Perceptron Training Tutorial.
It’s already compatible with Neuron, so you don’t need to change any code.
- 5. Create a Dockerfile that has the commands to install the Neuron SDK and training scripts:


 Guilherme Ricci is a Senior Startup Solutions Architect on Amazon Web Services, helping startups modernize and optimize the costs of their applications. With over 10 years of experience with companies in the financial sector, he is currently working with a team of AI/ML specialists.
Guilherme Ricci is a Senior Startup Solutions Architect on Amazon Web Services, helping startups modernize and optimize the costs of their applications. With over 10 years of experience with companies in the financial sector, he is currently working with a team of AI/ML specialists. Evandro Franco is an AI/ML Specialist Solutions Architect working on Amazon Web Services. He helps AWS customers overcome business challenges related to AI/ML on top of AWS. He has more than 15 years working with technology, from software development, infrastructure, serverless, to machine learning.
Evandro Franco is an AI/ML Specialist Solutions Architect working on Amazon Web Services. He helps AWS customers overcome business challenges related to AI/ML on top of AWS. He has more than 15 years working with technology, from software development, infrastructure, serverless, to machine learning. Matthew McClean leads the Annapurna ML Solution Architecture team that helps customers adopt AWS Trainium and AWS Inferentia products. He is passionate about generative AI and has been helping customers adopt AWS technologies for the last 10 years.
Matthew McClean leads the Annapurna ML Solution Architecture team that helps customers adopt AWS Trainium and AWS Inferentia products. He is passionate about generative AI and has been helping customers adopt AWS technologies for the last 10 years.Author: Guilherme Ricci