

Search enterprise data assets using LLMs backed by knowledge graphs
In this solution, we integrate large language models (LLMs) hosted on Amazon Bedrock backed by a knowledge base that is derived from a knowledge graph built on Amazon Neptune to create a powerful search paradigm that enables natural language-based questions to integrate search across documents stor…
Enterprises are facing challenges in accessing their data assets scattered across various sources because of increasing complexities in managing vast amount of data. Traditional search methods often fail to provide comprehensive and contextual results, particularly for unstructured data or complex queries.
Search solutions in modern big data management must facilitate efficient and accurate search of enterprise data assets that can adapt to the arrival of new assets. Customers want to search through all of the data and applications across their organization, and they want to see the provenance information for all of the documents retrieved. The application needs to search through the catalog and show the metadata information related to all of the data assets that are relevant to the search context. To accomplish all of these goals, the solution should include the following features:
- Provide connections between related entities and data sources
- Consolidate fragmented data cataloging systems that contain metadata
- Provide reasoning behind the search outputs
In this post, we present a generative AI-powered semantic search solution that empowers business users to quickly and accurately find relevant data assets across various enterprise data sources. In this solution, we integrate large language models (LLMs) hosted on Amazon Bedrock backed by a knowledge base that is derived from a knowledge graph built on Amazon Neptune to create a powerful search paradigm that enables natural language-based questions to integrate search across documents stored in Amazon Simple Storage Service (Amazon S3), data lake tables hosted on the AWS Glue Data Catalog, and enterprise assets in Amazon DataZone.
Foundation models (FMs) on Amazon Bedrock provide powerful generative models for text and language tasks. However, FMs lack domain-specific knowledge and reasoning capabilities. Knowledge graphs available on Neptune provide a means to represent interconnected facts and entities with inferencing and reasoning abilities for domains. Equipping FMs with structured reasoning abilities using domain-specific knowledge graphs harnesses the best of both approaches. This allows FMs to retain their inductive abilities while grounding their language understanding and generation in well-structured domain knowledge and logical reasoning. In the context of enterprise data asset search powered by a metadata catalog hosted on services such Amazon DataZone, AWS Glue, and other third-party catalogs, knowledge graphs can help integrate this linked data and also enable a scalable search paradigm that integrates metadata that evolves over time.
Solution overview
The solution integrates with your existing data catalogs and repositories, creating a unified, scalable semantic layer across the entire data landscape. When users ask questions in plain English, the search is not just for keywords; it comprehends the query’s intent and context, relating it to relevant tables, documents, and datasets across your organization. This semantic understanding enables more accurate, contextual, and insightful search results, making the entire company’s data as accessible and simple to search as using a consumer search engine, but with the depth and specificity your business demands. This significantly enhances decision-making, efficiency, and innovation throughout your organization by unlocking the full potential of your data assets. The following video shows the sample working solution.

Using graph data processing and the integration of natural language-based search on embedded graphs, these hybrid systems can unlock powerful insights from complex data structures.
The solution presented in this post consists of an ingestion pipeline and a search application UI that the user can submit queries to in natural language while searching for data assets.
The following diagram illustrates the end-to-end architecture, consisting of the metadata API layer, ingestion pipeline, embedding generation workflow, and frontend UI.

The ingestion pipeline (3) ingests metadata (1) from services (2), including Amazon DataZone, AWS Glue, and Amazon Athena, to a Neptune database after converting the JSON response from the service APIs into an RDF triple format. The RDF is converted into text and loaded into an S3 bucket, which is accessed by Amazon Bedrock (4) as the source of the knowledge base. You can extend this solution to include metadata from third-party cataloging solutions as well. The end-users access the application, which is hosted on Amazon CloudFront (5).
A state machine in AWS Step Functions defines the workflow of the ingestion process by invoking AWS Lambda functions, as illustrated in the following figure.

The functions perform the following actions:
- Read metadata from services (Amazon DataZone, AWS Glue, and Athena) in JSON format. Enhance the JSON format metadata to JSON-LD format by adding context, and load the data to an Amazon Neptune Serverless database as RDF triples. The following is an example of RDF triples in N-triples file format:
For more details about RDF data format, refer to the W3C documentation.
- Run SPARQL queries in the Neptune database to populate additional triples from inference rules. This step enriches the metadata by using the graph inferencing and reasoning capabilities. The following is a SPARQL query that inserts new metadata inferred from existing triples:
- Read triples from the Neptune database and convert them into text format using an LLM hosted on Amazon Bedrock. This solution uses Anthropic’s Claude 3 Haiku v1 for RDF-to-text conversion, storing the resulting text files in an S3 bucket.
Amazon Bedrock Knowledge Bases is configured to use the preceding S3 bucket as a data source to create a knowledge base. Amazon Bedrock Knowledge Bases creates vector embeddings from the text files using the Amazon Titan Text Embeddings v2 model.
A Streamlit application is hosted in Amazon Elastic Container Service (Amazon ECS) as a task, which provides a chatbot UI for users to submit queries against the knowledge base in Amazon Bedrock.
Prerequisites
The following are prerequisites to deploy the solution:
- An AWS account.
- The following LLM models must be enabled. For more information, see Add or remove access to Amazon Bedrock foundation models.
- Anthropic’s Claude 3 Haiku v1 – For converting triples to text.
- Anthropic’s Claude 3 Sonnet v1 – Used in the app for response generation.
- Amazon Titan Text Embeddings v2 – For embedding the documents and store in knowledge base.
- An AWS Identity and Access Management (IAM) role that has the privileges to run the AWS CloudFormation
- A user pool created in Amazon Cognito. A user pool application client is created for the user pool. Select User name for Cognito user pool sign-in options.

- Capture the user pool ID and application client ID, which will be required while launching the CloudFormation stack for building the web application.
- Create an Amazon Cognito user (for example, username=test_user) for your Amazon Cognito user pool that will be used to log in to the application. An email address must be included while creating the user.

Prepare the test data
A sample dataset is needed for testing the functionalities of the solution. In your AWS account, prepare a table using Amazon DataZone and Athena completing Step 1 through Step 8 in Amazon DataZone QuickStart with AWS Glue data. This will create a table and capture its metadata in the Data Catalog and Amazon DataZone.
To test how the solution is combining metadata from different data catalogs, create another table only in the Data Catalog, not in Amazon DataZone. On the Athena console, open the query editor and run the following query to create a new table:
Deploy the application
Complete the following steps to deploy the application:
- To launch the CloudFormation template, choose Launch Stack or download the template file (yaml) and launch the CloudFormation stack in your AWS account.

- Modify the stack name or leave as default, then choose Next.
- In the Parameters section, input the Amazon Cognito user pool ID (CognitoUserPoolId) and application client ID (CognitoAppClientId). This is required for successful deployment of the stacks.

- Review and update other AWS CloudFormation parameters if required. You can use the default values for all the parameters and continue with the stack deployment.
The following table lists the default parameters for the CloudFormation template.Parameter Name Description Default Value EnvironmentName Unique name to distinguish different web applications in the same AWS account (min length 1 and max length 4). dev S3DataPrefixKB S3 object prefix where the knowledge base source documents (metadata files) should be stored. knowledge_base Cpu CPU configuration of the ECS task. 512 Memory Memory configuration of the ECS task. 1024 ContainerPort Port for the ECS task host and container. 80 DesiredTaskCount Number of desired ECS task count. 1 MinContainers Minimum containers for auto scaling. Should be less than or equal to DesiredTaskCount. 1 MaxContainers Maximum containers for auto scaling. Should be greater than or equal to DesiredTaskCount. 3 AutoScalingTargetValue CPU utilization target percentage for ECS task auto scaling. 80 - Launch the stack.

The CloudFormation stack creates the required resources to launch the application by invoking a series of nested stacks. It deploys the following resources in your AWS account:
- An S3 bucket to save metadata details from AWS Glue, Athena, and Amazon DataZone, and its corresponding text data
- An additional S3 bucket to store code, artifacts, and logs related to the deployment
- A virtual private cloud (VPC), subnets, and network infrastructure
- An Amazon OpenSearch Serverless index
- An Amazon Bedrock knowledge base
- A data source for the knowledge base that connects to the S3 data bucket provisioned, with an event rule to sync the data
- A Lambda function that watches for objects dropped under the S3 prefix configured as parameter S3DataPrefixKB and starts an ingestion job using Amazon Bedrock Knowledge Bases APIs, which will read data from Amazon S3, chunk it, convert the chunks into embeddings using the Amazon Titan Embeddings model, and store these embeddings in OpenSearch Serverless
- An serverless Neptune database to store the RDF triples
- A State Functions state machine that invokes a series of Lambda functions that read from the different AWS services, generate RDF triples, and convert them to text documents
- An ECS cluster and service to host the Streamlit web application
After the CloudFormation stack is deployed, a Step Functions workflow will run automatically that orchestrates the metadata extract, transform, and load (ETL) job, and stores the final results in Amazon S3. View the execution status and details of the workflow by fetching the state machine Amazon Resource Name (ARN) from the CloudFormation stack. If AWS Lake Formation is enabled for the AWS Glue databases and tables in the account, complete the following steps after the CloudFormation stack is deployed to update the permission and extract the metadata details from AWS Glue and update the metadata details to load to the knowledge base:
- Add a role to the AWS Glue Lambda function that grants access to the AWS Glue database.

- Fetch the state machine ARN from the CloudFormation stack.

- Run the state machine with default input values to extract the metadata details and write to Amazon S3.


You can search for the application stack name <MainStackName>-deploy-<EnvironmentName> (for example, mm-enterprise-search-deploy-dev) on the AWS CloudFormation console. Locate the web application URL in the stack outputs (CloudfrontURL). Launch the web application by choosing the URL link.

Use the application
You can access the application from a web browser using the domain name of the Amazon CloudFront distribution created in the deployment steps. Log in using a user credential that exists in the Amazon Cognito user pool.

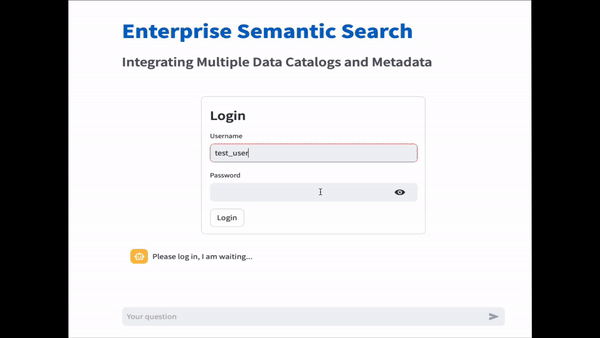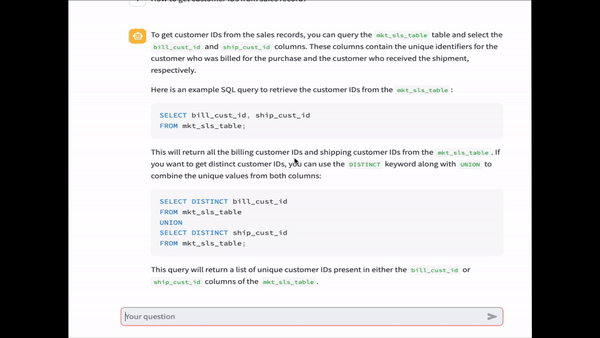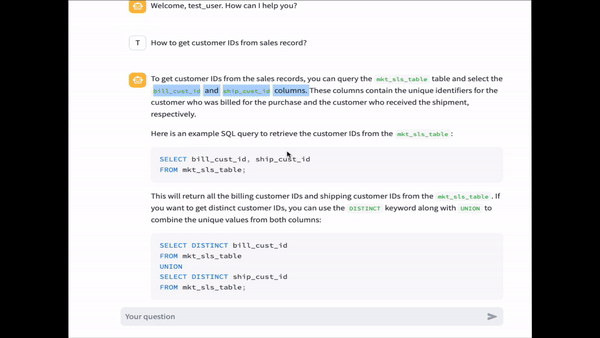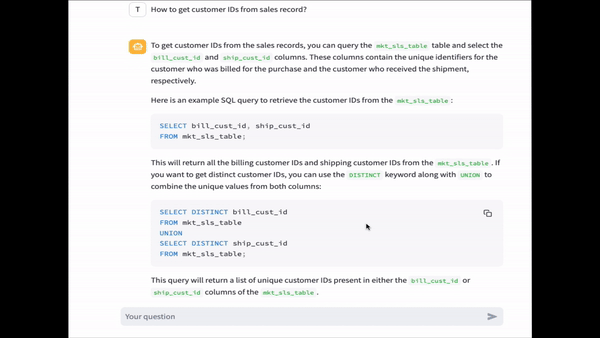
Now you can submit a query using a text input. The AWS account used in this example contains sample tables related to sales and marketing. We ask the question, “How to query sales data?” The answer includes metadata on the table mkt_sls_table that was created in the previous steps.

We ask another question: “How to get customer names from sales data?” In the previous steps, we created the raw_customer table, which wasn’t published as a data asset in Amazon DataZone. The table only exists in the Data Catalog. The application returns an answer that combines metadata from Amazon DataZone and AWS Glue.

This powerful solution opens up exciting possibilities for enterprise data discovery and insights. We encourage you to deploy it in your own environment and experiment with different types of queries across your data assets. Try combining information from multiple sources, asking complex questions, and see how the semantic understanding improves your search experience.
Clean up
The total cost of running this setup is less than $10 per day. However, we recommend deleting the CloudFormation stack after use because the deployed resources incur costs. Deleting the main stack also deletes all the nested stacks except the VPC because of dependency. You also need to delete the VPC from the Amazon VPC console.
Conclusion
In this post, we presented a comprehensive and extendable multimodal search solution of enterprise data assets. The integration of LLMs and knowledge graphs shows that by combining the strengths of these technologies, organizations can unlock new levels of data discovery, reasoning, and insight generation, ultimately driving innovation and progress across a wide range of domains.
To learn more about LLM and knowledge graph use cases, refer to the following resources:
- Building commonsense knowledge graphs to aid product recommendation
- Using knowledge graphs to build GraphRAG applications with Amazon Bedrock and Amazon Neptune
- Build a knowledge graph on Amazon Neptune with AI-powered video analysis using Media2Cloud
About the Authors
 Sudipta Mitra is a Generative AI Specialist Solutions Architect at AWS, who helps customers across North America use the power of data and AI to transform their businesses and solve their most challenging problems. His mission is to enable customers achieve their business goals and create value with data and AI. He helps architect solutions across AI/ML applications, enterprise data platforms, data governance, and unified search in enterprises.
Sudipta Mitra is a Generative AI Specialist Solutions Architect at AWS, who helps customers across North America use the power of data and AI to transform their businesses and solve their most challenging problems. His mission is to enable customers achieve their business goals and create value with data and AI. He helps architect solutions across AI/ML applications, enterprise data platforms, data governance, and unified search in enterprises.
 Gi Kim is a Data & ML Engineer with the AWS Professional Services team, helping customers build data analytics solutions and AI/ML applications. With over 20 years of experience in solution design and development, he has a background in multiple technologies, and he works with specialists from different industries to develop new innovative solutions using his skills. When he is not working on solution architecture and development, he enjoys playing with his dogs at a beach under the San Francisco Golden Gate Bridge.
Gi Kim is a Data & ML Engineer with the AWS Professional Services team, helping customers build data analytics solutions and AI/ML applications. With over 20 years of experience in solution design and development, he has a background in multiple technologies, and he works with specialists from different industries to develop new innovative solutions using his skills. When he is not working on solution architecture and development, he enjoys playing with his dogs at a beach under the San Francisco Golden Gate Bridge.
 Surendiran Rangaraj is a Data & ML Engineer at AWS who helps customers unlock the power of big data, machine learning, and generative AI applications for their business solutions. He works closely with a diverse range of customers to design and implement tailored strategies that boost efficiency, drive growth, and enhance customer experiences.
Surendiran Rangaraj is a Data & ML Engineer at AWS who helps customers unlock the power of big data, machine learning, and generative AI applications for their business solutions. He works closely with a diverse range of customers to design and implement tailored strategies that boost efficiency, drive growth, and enhance customer experiences.
Author: Surendiran Rangaraj