

Securing generative AI: data, compliance, and privacy considerations
When you use a generative AI-based service, you should understand how the information that you enter into the application is stored, processed, shared, and used by the model provider or the provider of the environment that the model runs in… Organizations that offer generative AI solutions have …
Generative artificial intelligence (AI) has captured the imagination of organizations and individuals around the world, and many have already adopted it to help improve workforce productivity, transform customer experiences, and more.
When you use a generative AI-based service, you should understand how the information that you enter into the application is stored, processed, shared, and used by the model provider or the provider of the environment that the model runs in. Organizations that offer generative AI solutions have a responsibility to their users and consumers to build appropriate safeguards, designed to help verify privacy, compliance, and security in their applications and in how they use and train their models.
This post continues our series on how to secure generative AI, and provides guidance on the regulatory, privacy, and compliance challenges of deploying and building generative AI workloads. We recommend that you start by reading the first post of this series: Securing generative AI: An introduction to the Generative AI Security Scoping Matrix, which introduces you to the Generative AI Scoping Matrix—a tool to help you identify your generative AI use case—and lays the foundation for the rest of our series.
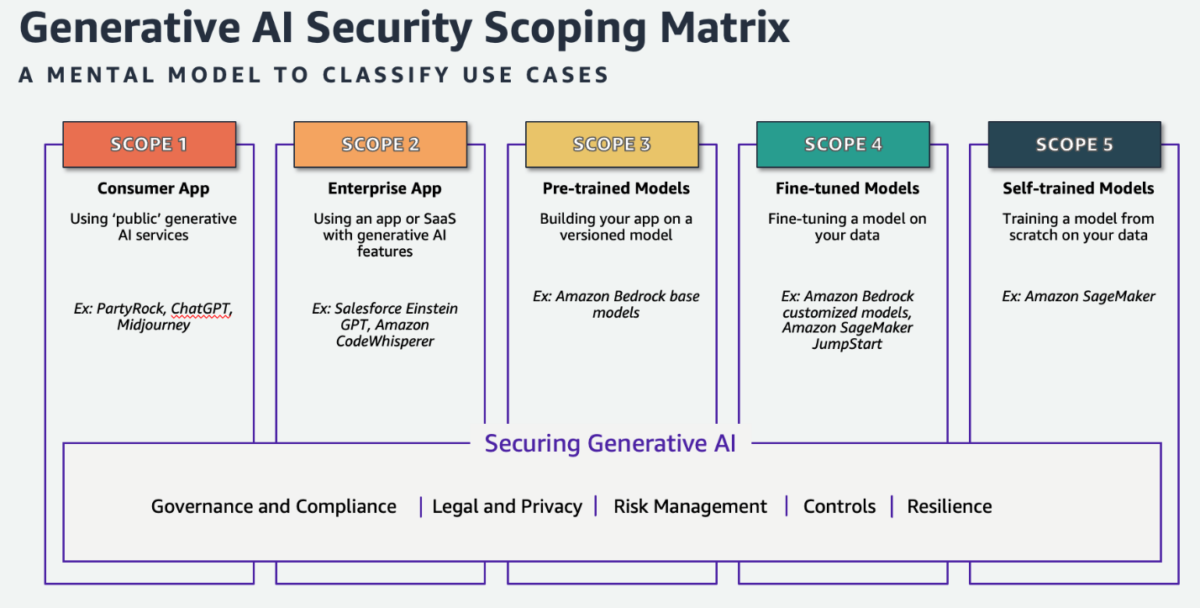
Figure 1 shows the scoping matrix:

Figure 1: Generative AI Scoping Matrix
Broadly speaking, we can classify the use cases in the scoping matrix into two categories: prebuilt generative AI applications (Scopes 1 and 2), and self-built generative AI applications (Scopes 3–5). Although some consistent legal, governance, and compliance requirements apply to all five scopes, each scope also has unique requirements and considerations. We will cover some key considerations and best practices for each scope.
Scope 1: Consumer applications
Consumer applications are typically aimed at home or non-professional users, and they’re usually accessed through a web browser or a mobile app. Many applications that created the initial excitement around generative AI fall into this scope, and can be free or paid for, using a standard end-user license agreement (EULA). Although they might not be built specifically for enterprise use, these applications have widespread popularity. Your employees might be using them for their own personal use and might expect to have such capabilities to help with work tasks.
Many large organizations consider these applications to be a risk because they can’t control what happens to the data that is input or who has access to it. In response, they ban Scope 1 applications. Although we encourage due diligence in assessing the risks, outright bans can be counterproductive. Banning Scope 1 applications can cause unintended consequences similar to that of shadow IT, such as employees using personal devices to bypass controls that limit use, reducing visibility into the applications that they use. Instead of banning generative AI applications, organizations should consider which, if any, of these applications can be used effectively by the workforce, but within the bounds of what the organization can control, and the data that are permitted for use within them.
To help your workforce understand the risks associated with generative AI and what is acceptable use, you should create a generative AI governance strategy, with specific usage guidelines, and verify your users are made aware of these policies at the right time. For example, you could have a proxy or cloud access security broker (CASB) control that, when accessing a generative AI based service, provides a link to your company’s public generative AI usage policy and a button that requires them to accept the policy each time they access a Scope 1 service through a web browser when using a device that your organization issued and manages. This helps verify that your workforce is trained and understands the risks, and accepts the policy before using such a service.
To help address some key risks associated with Scope 1 applications, prioritize the following considerations:
- Identify which generative AI services your staff are currently using and seeking to use.
- Understand the service provider’s terms of service and privacy policy for each service, including who has access to the data and what can be done with the data, including prompts and outputs, how the data might be used, and where it’s stored.
- Understand the source data used by the model provider to train the model. How do you know the outputs are accurate and relevant to your request? Consider implementing a human-based testing process to help review and validate that the output is accurate and relevant to your use case, and provide mechanisms to gather feedback from users on accuracy and relevance to help improve responses.
- Seek legal guidance about the implications of the output received or the use of outputs commercially. Determine who owns the output from a Scope 1 generative AI application, and who is liable if the output uses (for example) private or copyrighted information during inference that is then used to create the output that your organization uses.
- The EULA and privacy policy of these applications will change over time with minimal notice. Changes in license terms can result in changes to ownership of outputs, changes to processing and handling of your data, or even liability changes on the use of outputs. Create a plan/strategy/mechanism to monitor the policies on approved generative AI applications. Review the changes and adjust your use of the applications accordingly.
For Scope 1 applications, the best approach is to consider the input prompts and generated content as public, and not to use personally identifiable information (PII), highly sensitive, confidential, proprietary, or company intellectual property (IP) data with these applications.
Scope 1 applications typically offer the fewest options in terms of data residency and jurisdiction, especially if your staff are using them in a free or low-cost price tier. If your organization has strict requirements around the countries where data is stored and the laws that apply to data processing, Scope 1 applications offer the fewest controls, and might not be able to meet your requirements.
Scope 2: Enterprise applications
The main difference between Scope 1 and Scope 2 applications is that Scope 2 applications provide the opportunity to negotiate contractual terms and establish a formal business-to-business (B2B) relationship. They are aimed at organizations for professional use with defined service level agreements (SLAs) and licensing terms and conditions, and they are usually paid for under enterprise agreements or standard business contract terms. The enterprise agreement in place usually limits approved use to specific types (and sensitivities) of data.
Most aspects from Scope 1 apply to Scope 2. However, in Scope 2, you are intentionally using your proprietary data and encouraging the widespread use of the service across your organization. When assessing the risk, consider these additional points:
- Determine the acceptable classification of data that is permitted to be used with each Scope 2 application, update your data handling policy to reflect this, and include it in your workforce training.
- Understand the data flow of the service. Ask the provider how they process and store your data, prompts, and outputs, who has access to it, and for what purpose. Do they have any certifications or attestations that provide evidence of what they claim and are these aligned with what your organization requires. Make sure that these details are included in the contractual terms and conditions that you or your organization agree to.
- What (if any) data residency requirements do you have for the types of data being used with this application? Understand where your data will reside and if this aligns with your legal or regulatory obligations.
- Many major generative AI vendors operate in the USA. If you are based outside the USA and you use their services, you have to consider the legal implications and privacy obligations related to data transfers to and from the USA.
- Vendors that offer choices in data residency often have specific mechanisms you must use to have your data processed in a specific jurisdiction. You might need to indicate a preference at account creation time, opt into a specific kind of processing after you have created your account, or connect to specific regional endpoints to access their service.
- Most Scope 2 providers want to use your data to enhance and train their foundational models. You will probably consent by default when you accept their terms and conditions. Consider whether that use of your data is permissible. If your data is used to train their model, there is a risk that a later, different user of the same service could receive your data in their output. If you need to prevent reuse of your data, find the opt-out options for your provider. You might need to negotiate with them if they don’t have a self-service option for opting out.
- When you use an enterprise generative AI tool, your company’s usage of the tool is typically metered by API calls. That is, you pay a certain fee for a certain number of calls to the APIs. Those API calls are authenticated by the API keys the provider issues to you. You need to have strong mechanisms for protecting those API keys and for monitoring their usage. If the API keys are disclosed to unauthorized parties, those parties will be able to make API calls that are billed to you. Usage by those unauthorized parties will also be attributed to your organization, potentially training the model (if you’ve agreed to that) and impacting subsequent uses of the service by polluting the model with irrelevant or malicious data.
Scope 3: Pre-trained models
In contrast to prebuilt applications (Scopes 1 and 2), Scope 3 applications involve building your own generative AI applications by using a pretrained foundation model available through services such as Amazon Bedrock and Amazon SageMaker JumpStart. You can use these solutions for your workforce or external customers. Much of the guidance for Scopes 1 and 2 also applies here; however, there are some additional considerations:
- A common feature of model providers is to allow you to provide feedback to them when the outputs don’t match your expectations. Does the model vendor have a feedback mechanism that you can use? If so, make sure that you have a mechanism to remove sensitive content before sending feedback to them.
- Does the provider have an indemnification policy in the event of legal challenges for potential copyright content generated that you use commercially, and has there been case precedent around it?
- Is your data included in prompts or responses that the model provider uses? If so, for what purpose and in which location, how is it protected, and can you opt out of the provider using it for other purposes, such as training? At Amazon, we don’t use your prompts and outputs to train or improve the underlying models in Amazon Bedrock and SageMaker JumpStart (including those from third parties), and humans won’t review them. Also, we don’t share your data with third-party model providers. Your data remains private to you within your AWS accounts.
- Establish a process, guidelines, and tooling for output validation. How do you make sure that the right information is included in the outputs based on your fine-tuned model, and how do you test the model’s accuracy? For example:
- If the application is generating text, create a test and output validation process that is tested by humans on a regular basis (for example, once a week) to verify the generated outputs are producing the expected results.
- Another approach could be to implement a feedback mechanism that the users of your application can use to submit information on the accuracy and relevance of output.
- If generating programming code, this should be scanned and validated in the same way that any other code is checked and validated in your organization.
Scope 4: Fine-tuned models
Scope 4 is an extension of Scope 3, where the model that you use in your application is fine-tuned with data that you provide to improve its responses and be more specific to your needs. The considerations for Scope 3 are also relevant to Scope 4; in addition, you should consider the following:
- What is the source of the data used to fine-tune the model? Understand the quality of the source data used for fine-tuning, who owns it, and how that could lead to potential copyright or privacy challenges when used.
- Remember that fine-tuned models inherit the data classification of the whole of the data involved, including the data that you use for fine-tuning. If you use sensitive data, then you should restrict access to the model and generated content to that of the classified data.
- As a general rule, be careful what data you use to tune the model, because changing your mind will increase cost and delays. If you tune a model on PII directly, and later determine that you need to remove that data from the model, you can’t directly delete data. With current technology, the only way for a model to unlearn data is to completely retrain the model. Retraining usually requires a lot of time and money.
Scope 5: Self-trained models
With Scope 5 applications, you not only build the application, but you also train a model from scratch by using training data that you have collected and have access to. Currently, this is the only approach that provides full information about the body of data that the model uses. The data can be internal organization data, public data, or both. You control many aspects of the training process, and optionally, the fine-tuning process. Depending on the volume of data and the size and complexity of your model, building a scope 5 application requires more expertise, money, and time than any other kind of AI application. Although some customers have a definite need to create Scope 5 applications, we see many builders opting for Scope 3 or 4 solutions.
For Scope 5 applications, here are some items to consider:
- You are the model provider and must assume the responsibility to clearly communicate to the model users how the data will be used, stored, and maintained through a EULA.
- Unless required by your application, avoid training a model on PII or highly sensitive data directly.
- Your trained model is subject to all the same regulatory requirements as the source training data. Govern and protect the training data and trained model according to your regulatory and compliance requirements. After the model is trained, it inherits the data classification of the data that it was trained on.
- To limit potential risk of sensitive information disclosure, limit the use and storage of the application users’ data (prompts and outputs) to the minimum needed.
AI regulation and legislation
AI regulations are rapidly evolving and this could impact you and your development of new services that include AI as a component of the workload. At AWS, we’re committed to developing AI responsibly and taking a people-centric approach that prioritizes education, science, and our customers, to integrate responsible AI across the end-to-end AI lifecycle. For more details, see our Responsible AI resources. To help you understand various AI policies and regulations, the OECD AI Policy Observatory is a good starting point for information about AI policy initiatives from around the world that might affect you and your customers. At the time of publication of this post, there are over 1,000 initiatives across more 69 countries.
In this section, we consider regulatory themes from two different proposals to legislate AI: the European Union (EU) Artificial Intelligence (AI) Act (EUAIA), and the United States Executive Order on Artificial Intelligence.
Our recommendation for AI regulation and legislation is simple: monitor your regulatory environment, and be ready to pivot your project scope if required.
Theme 1: Data privacy
According to the UK Information Commissioners Office (UK ICO), the emergence of generative AI doesn’t change the principles of data privacy laws, or your obligations to uphold them. There are implications when using personal data in generative AI workloads. Personal data might be included in the model when it’s trained, submitted to the AI system as an input, or produced by the AI system as an output. Personal data from inputs and outputs can be used to help make the model more accurate over time via retraining.
For AI projects, many data privacy laws require you to minimize the data being used to what is strictly necessary to get the job done. To go deeper on this topic, you can use the eight questions framework published by the UK ICO as a guide. We recommend using this framework as a mechanism to review your AI project data privacy risks, working with your legal counsel or Data Protection Officer.
In simple terms, follow the maxim “don’t record unnecessary data” in your project.
Theme 2: Transparency and explainability
The OECD AI Observatory defines transparency and explainability in the context of AI workloads. First, it means disclosing when AI is used. For example, if a user interacts with an AI chatbot, tell them that. Second, it means enabling people to understand how the AI system was developed and trained, and how it operates. For example, the UK ICO provides guidance on what documentation and other artifacts you should provide that describe how your AI system works. In general, transparency doesn’t extend to disclosure of proprietary sources, code, or datasets. Explainability means enabling the people affected, and your regulators, to understand how your AI system arrived at the decision that it did. For example, if a user receives an output that they don’t agree with, then they should be able to challenge it.
So what can you do to meet these legal requirements? In practical terms, you might be required to show the regulator that you have documented how you implemented the AI principles throughout the development and operation lifecycle of your AI system. In addition to the ICO guidance, you can also consider implementing an AI Management system based on ISO42001:2023.
Diving deeper on transparency, you might need to be able to show the regulator evidence of how you collected the data, as well as how you trained your model.
Transparency with your data collection process is important to reduce risks associated with data. One of the leading tools to help you manage the transparency of the data collection process in your project is Pushkarna and Zaldivar’s Data Cards (2022) documentation framework. The Data Cards tool provides structured summaries of machine learning (ML) data; it records data sources, data collection methods, training and evaluation methods, intended use, and decisions that affect model performance. If you import datasets from open source or public sources, review the Data Provenance Explorer initiative. This project has audited over 1,800 datasets for licensing, creators, and origin of data.
Transparency with your model creation process is important to reduce risks associated with explainability, governance, and reporting. Amazon SageMaker has a feature called Model Cards that you can use to help document critical details about your ML models in a single place, and streamlining governance and reporting. You should catalog details such as intended use of the model, risk rating, training details and metrics, and evaluation results and observations.
When you use models that were trained outside of your organization, then you will need to rely on Standard Contractual Clauses. SCC’s enable sharing and transfer of any personal information that the model might have been trained on, especially if data is being transferred from the EU to third countries. As part of your due diligence, you should contact the vendor of your model to ask for a Data Card, Model Card, Data Protection Impact Assessment (for example, ISO29134:2023), or Transfer Impact Assessment (for example, IAPP). If no such documentation exists, then you should factor this into your own risk assessment when making a decision to use that model. Two examples of third-party AI providers that have worked to establish transparency for their products are Twilio and SalesForce. Twilio provides AI Nutrition Facts labels for its products to make it simple to understand the data and model. SalesForce addresses this challenge by making changes to their acceptable use policy.
Theme 3: Automated decision making and human oversight
The final draft of the EUAIA, which starts to come into force from 2026, addresses the risk that automated decision making is potentially harmful to data subjects because there is no human intervention or right of appeal with an AI model. Responses from a model have a likelihood of accuracy, so you should consider how to implement human intervention to increase certainty. This is important for workloads that can have serious social and legal consequences for people—for example, models that profile people or make decisions about access to social benefits. We recommend that when you are developing your business case for an AI project, consider where human oversight should be applied in the workflow.
The UK ICO provides guidance on what specific measures you should take in your workload. You might give users information about the processing of the data, introduce simple ways for them to request human intervention or challenge a decision, carry out regular checks to make sure that the systems are working as intended, and give individuals the right to contest a decision.
The US Executive Order for AI describes the need to protect people from automatic discrimination based on sensitive characteristics. The order places the onus on the creators of AI products to take proactive and verifiable steps to help verify that individual rights are protected, and the outputs of these systems are equitable.
Prescriptive guidance on this topic would be to assess the risk classification of your workload and determine points in the workflow where a human operator needs to approve or check a result. Addressing bias in the training data or decision making of AI might include having a policy of treating AI decisions as advisory, and training human operators to recognize those biases and take manual actions as part of the workflow.
Theme 4: Regulatory classification of AI systems
Just like businesses classify data to manage risks, some regulatory frameworks classify AI systems. It is a good idea to become familiar with the classifications that might affect you. The EUAIA uses a pyramid of risks model to classify workload types. If a workload has an unacceptable risk (according to the EUAIA), then it might be banned altogether.
Banned workloads
The EUAIA identifies several AI workloads that are banned, including CCTV or mass surveillance systems, systems used for social scoring by public authorities, and workloads that profile users based on sensitive characteristics. We recommend you perform a legal assessment of your workload early in the development lifecycle using the latest information from regulators.
High risk workloads
There are also several types of data processing activities that the Data Privacy law considers to be high risk. If you are building workloads in this category then you should expect a higher level of scrutiny by regulators, and you should factor extra resources into your project timeline to meet regulatory requirements. The good news is that the artifacts you created to document transparency, explainability, and your risk assessment or threat model, might help you meet the reporting requirements. To see an example of these artifacts. see the AI and data protection risk toolkit published by the UK ICO.
Examples of high-risk processing include innovative technology such as wearables, autonomous vehicles, or workloads that might deny service to users such as credit checking or insurance quotes. We recommend that you engage your legal counsel early in your AI project to review your workload and advise on which regulatory artifacts need to be created and maintained. You can see further examples of high risk workloads at the UK ICO site here.
The EUAIA also pays particular attention to profiling workloads. The UK ICO defines this as “any form of automated processing of personal data consisting of the use of personal data to evaluate certain personal aspects relating to a natural person, in particular to analyse or predict aspects concerning that natural person’s performance at work, economic situation, health, personal preferences, interests, reliability, behaviour, location or movements.” Our guidance is that you should engage your legal team to perform a review early in your AI projects.
We recommend that you factor a regulatory review into your timeline to help you make a decision about whether your project is within your organization’s risk appetite. We recommend you maintain ongoing monitoring of your legal environment as the laws are rapidly evolving.
Theme 6: Safety
ISO42001:2023 defines safety of AI systems as “systems behaving in expected ways under any circumstances without endangering human life, health, property or the environment.”
The United States AI Bill of Rights states that people have a right to be protected from unsafe or ineffective systems. In October 2023, President Biden issued the Executive Order on Safe, Secure and Trustworthy Artificial Intelligence, which highlights the requirement to understand the context of use for an AI system, engaging the stakeholders in the community that will be affected by its use. The Executive Order also describes the documentation, controls, testing, and independent validation of AI systems, which aligns closely with the explainability theme that we discussed previously. For your workload, make sure that you have met the explainability and transparency requirements so that you have artifacts to show a regulator if concerns about safety arise. The OECD also offers prescriptive guidance here, highlighting the need for traceability in your workload as well as regular, adequate risk assessments—for example, ISO23894:2023 AI Guidance on risk management.
Conclusion
Although generative AI might be a new technology for your organization, many of the existing governance, compliance, and privacy frameworks that we use today in other domains apply to generative AI applications. Data that you use to train generative AI models, prompt inputs, and the outputs from the application should be treated no differently to other data in your environment and should fall within the scope of your existing data governance and data handling policies. Be mindful of the restrictions around personal data, especially if children or vulnerable people can be impacted by your workload. When fine-tuning a model with your own data, review the data that is used and know the classification of the data, how and where it’s stored and protected, who has access to the data and trained models, and which data can be viewed by the end user. Create a program to train users on the uses of generative AI, how it will be used, and data protection policies that they need to adhere to. For data that you obtain from third parties, make a risk assessment of those suppliers and look for Data Cards to help ascertain the provenance of the data.
Regulation and legislation typically take time to formulate and establish; however, existing laws already apply to generative AI, and other laws on AI are evolving to include generative AI. Your legal counsel should help keep you updated on these changes. When you build your own application, you should be aware of new legislation and regulation that is in draft form (such as the EU AI Act) and whether it will affect you, in addition to the many others that might already exist in locations where you operate, because they could restrict or even prohibit your application, depending on the risk the application poses.
At AWS, we make it simpler to realize the business value of generative AI in your organization, so that you can reinvent customer experiences, enhance productivity, and accelerate growth with generative AI. If you want to dive deeper into additional areas of generative AI security, check out the other posts in our Securing Generative AI series:
- Securing Generative AI: An introduction to the Generative AI Security Scoping Matrix
- Designing generative AI workloads for resilience
- Securing Generative AI: Applying relevant security controls
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, start a new thread on the Generative AI on AWS re:Post or contact AWS Support.
Author: Mark Keating