

Securing MLflow in AWS: Fine-grained access control with AWS native services
This post provides a solution tailored to customers that are already using MLflow, an open-source platform for managing ML workflows… In a previous post, we discussed MLflow and how it can run on AWS and be integrated with SageMaker—in particular, when tracking training jobs as experiments and…
With Amazon SageMaker, you can manage the whole end-to-end machine learning (ML) lifecycle. It offers many native capabilities to help manage ML workflows aspects, such as experiment tracking, and model governance via the model registry. This post provides a solution tailored to customers that are already using MLflow, an open-source platform for managing ML workflows.
In a previous post, we discussed MLflow and how it can run on AWS and be integrated with SageMaker—in particular, when tracking training jobs as experiments and deploying a model registered in MLflow to the SageMaker managed infrastructure. However, the open-source version of MLflow doesn’t provide native user access control mechanisms for multiple tenants on the tracking server. This means any user with access to the server has admin rights and can modify experiments, model versions, and stages. This can be a challenge for enterprises in regulated industries that need to keep strong model governance for audit purposes.
In this post, we address these limitations by implementing the access control outside of the MLflow server and offloading authentication and authorization tasks to Amazon API Gateway, where we implement fine-grained access control mechanisms at the resource level using Identity and Access Management (IAM). By doing so, we can achieve robust and secure access to the MLflow server from both SageMaker managed infrastructure and Amazon SageMaker Studio, without having to worry about credentials and all the complexity behind credential management. The modular design proposed in this architecture makes modifying access control logic straightforward without impacting the MLflow server itself. Lastly, thanks to SageMaker Studio extensibility, we further improve the data scientist experience by making MLflow accessible within Studio, as shown in the following screenshot.

MLflow has integrated the feature that enables request signing using AWS credentials into the upstream repository for its Python SDK, improving the integration with SageMaker. The changes to the MLflow Python SDK are available for everyone since MLflow version 1.30.0.
At a high level, this post demonstrates the following:
- How to deploy an MLflow server on a serverless architecture running on a private subnet not accessible directly from the outside. For this task, we build on top the following GitHub repo: Manage your machine learning lifecycle with MLflow and Amazon SageMaker.
- How to expose the MLflow server via private integrations to an API Gateway, and implement a secure access control for programmatic access via the SDK and browser access via the MLflow UI.
- How to log experiments and runs, and register models to an MLflow server from SageMaker using the associated SageMaker execution roles to authenticate and authorize requests, and how to authenticate via Amazon Cognito to the MLflow UI. We provide examples demonstrating experiment tracking and using the model registry with MLflow from SageMaker training jobs and Studio, respectively, in the provided notebook.
- How to use MLflow as a centralized repository in a multi-account setup.
- How to extend Studio to enhance the user experience by rendering MLflow within Studio. For this task, we show how to take advantage of Studio extensibility by installing a JupyterLab extension.
Now let’s dive deeper into the details.
Solution overview
You can think about MLflow as three different core components working side by side:
- A REST API for the backend MLflow tracking server
- SDKs for you to programmatically interact with the MLflow tracking server APIs from your model training code
- A React front end for the MLflow UI to visualize your experiments, runs, and artifacts
At a high level, the architecture we have envisioned and implemented is shown in the following figure.

Prerequisites
Before deploying the solution, make sure you have access to an AWS account with admin permissions.
Deploy the solution infrastructure
To deploy the solution described in this post, follow the detailed instructions in the GitHub repository README. To automate the infrastructure deployment, we use the AWS Cloud Development Kit (AWS CDK). The AWS CDK is an open-source software development framework to create AWS CloudFormation stacks through automatic CloudFormation template generation. A stack is a collection of AWS resources that can be programmatically updated, moved, or deleted. AWS CDK constructs are the building blocks of AWS CDK applications, representing the blueprint to define cloud architectures.
We combine four stacks:
- The MLFlowVPCStack stack performs the following actions:
- Deploys an Mlflow tracking server on a serverless infrastructure running on Amazon Elastic Container Service (Amazon ECS) and AWS Fargate on a private subnet.
- Deploys an Amazon Aurora Serverless database for the data store and Amazon Simple Storage Service (Amazon S3) for the artifact store.
- The RestApiGatewayStack stack performs the following actions:
- Exposes the MLflow server via AWS PrivateLink to an REST API Gateway.
- Deploys an Amazon Cognito user pool to manage the users accessing the UI (still empty after the deployment).
- Deploys an AWS Lambda authorizer to verify the JWT token with the Amazon Cognito user pool ID keys and returns IAM policies to allow or deny a request. This authorization strategy is applied to
<MLFlow-Tracking-Server-URI>/*. - Adds an IAM authorizer. This will be applied to the to the
<MLFlow-Tracking-Server-URI>/api/*, which will take precedence over the previous one.
- The AmplifyMLFlowStack stack performs the following action:
- Creates an app linked to the patched MLflow repository in AWS CodeCommit to build and deploy the MLflow UI.
- The SageMakerStudioUserStack stack performs the following actions:
- Deploys a Studio domain (if one doesn’t exist yet).
- Adds three users, each one with a different SageMaker execution role implementing a different access level:
- mlflow-admin – Has admin-like permission to any MLflow resources.
- mlflow-reader – Has read-only admin permissions to any MLflow resources.
- mlflow-model-approver – Has the same permissions as mlflow-reader, plus can register new models from existing runs in MLflow and promote existing registered models to new stages.
Deploy the MLflow tracking server on a serverless architecture
Our aim is to have a reliable, highly available, cost-effective, and secure deployment of the MLflow tracking server. Serverless technologies are the perfect candidate to satisfy all these requirements with minimal operational overhead. To achieve that, we build a Docker container image for the MLflow experiment tracking server, and we run it in on AWS Fargate on Amazon ECS in its dedicated VPC running on a private subnet. MLflow relies on two storage components: the backend store and for the artifact store. For the backend store, we use Aurora Serverless, and for the artifact store, we use Amazon S3. For the high-level architecture, refer to Scenario 4: MLflow with remote Tracking Server, backend and artifact stores. Extensive details on how to do this task can be found in the following GitHub repo: Manage your machine learning lifecycle with MLflow and Amazon SageMaker.
Secure MLflow via API Gateway
At this point, we still don’t have an access control mechanism in place. As a first step, we expose MLflow to the outside world using AWS PrivateLink, which establishes a private connection between the VPC and other AWS services, in our case API Gateway. Incoming requests to MLflow are then proxied via a REST API Gateway, giving us the possibility to implement several mechanisms to authorize incoming requests. For our purposes, we focus on only two:
- Using IAM authorizers – With IAM authorizers, the requester must have the right IAM policy assigned to access the API Gateway resources. Every request must add authentication information to requests sent via HTTP by AWS Signature Version 4.
- Using Lambda authorizers – This offers the greatest flexibility because it leaves full control over how a request can be authorized. Eventually, the Lambda authorizer must return an IAM policy, which in turn will be evaluated by API Gateway on whether the request should be allowed or denied.
For the full list of supported authentication and authorization mechanisms in API Gateway, refer to Controlling and managing access to a REST API in API Gateway.
MLflow Python SDK authentication (IAM authorizer)
The MLflow experiment tracking server implements a REST API to interact in a programmatic way with the resources and artifacts. The MLflow Python SDK provides a convenient way to log metrics, runs, and artifacts, and it interfaces with the API resources hosted under the namespace <MLflow-Tracking-Server-URI>/api/. We configure API Gateway to use the IAM authorizer for resource access control on this namespace, thereby requiring every request to be signed with AWS Signature Version 4.
To facilitate the request signing process, starting from MLflow 1.30.0, this capability can be seamlessly enabled. Make sure that the requests_auth_aws_sigv4 library is installed in the system and set the MLFLOW_TRACKING_AWS_SIGV4 environment variable to True. More information can be found in the official MLflow documentation.
At this point, the MLflow SDK only needs AWS credentials. Because request_auth_aws_sigv4 uses Boto3 to retrieve credentials, we know that it can load credentials from the instance metadata when an IAM role is associated with an Amazon Elastic Compute Cloud (Amazon EC2) instance (for other ways to supply credentials to Boto3, see Credentials). This means that it can also load AWS credentials when running from a SageMaker managed instance from the associated execution role, as discussed later in this post.
Configure IAM policies to access MLflow APIs via API Gateway
You can use IAM roles and policies to control who can invoke resources on API Gateway. For more details and IAM policy reference statements, refer to Control access for invoking an API.
The following code shows an example IAM policy that grants the caller permissions to all methods on all resources on the API Gateway shielding MLflow, practically giving admin access to the MLflow server:
{
"Version": "2012-10-17",
"Statement": [
{
"Action": "execute-api:Invoke",
"Resource": "arn:aws:execute-api:<REGION>:<ACCOUNT_ID>:<MLFLOW_API_ID>/<STAGE>/*/*",
"Effect": "Allow"
}
]
}If we want a policy that allows a user read-only access to all resources, the IAM policy would look like the following code:
{
"Version": "2012-10-17",
"Statement": [
{
"Action": "execute-api:Invoke",
"Resource": [
"arn:aws:execute-api:<REGION>:<ACCOUNT_ID>:<MLFLOW_API_ID>/<STAGE>/GET/*",
"arn:aws:execute-api:<REGION>:<ACCOUNT_ID>:<MLFLOW_API_ID>/<STAGE>/POST/api/2.0/mlflow/runs/search/",
"arn:aws:execute-api:<REGION>:<ACCOUNT_ID>:<MLFLOW_API_ID>/<STAGE>/POST/api/2.0/mlflow/experiments/search",
],
"Effect": "Allow"
}
]
}Another example might be a policy to give specific users permissions to register models to the model registry and promote them later to specific stages (staging, production, and so on):
{
"Version": "2012-10-17",
"Statement": [
{
"Action": "execute-api:Invoke",
"Resource": [
"arn:aws:execute-api:<REGION>:<ACCOUNT_ID>:<MLFLOW_API_ID>/<STAGE>/GET/*",
"arn:aws:execute-api:<REGION>:<ACCOUNT_ID>:<MLFLOW_API_ID>/<STAGE>/POST/api/2.0/mlflow/runs/search/",
"arn:aws:execute-api:<REGION>:<ACCOUNT_ID>:<MLFLOW_API_ID>/<STAGE>/POST/api/2.0/mlflow/experiments/search",
"arn:aws:execute-api:<REGION>:<ACCOUNT_ID>:<MLFLOW_API_ID>/<STAGE>/POST/api/2.0/mlflow/model-versions/*",
"arn:aws:execute-api:<REGION>:<ACCOUNT_ID>:<MLFLOW_API_ID>/<STAGE>/POST/api/2.0/mlflow/registered-models/*"
],
"Effect": "Allow"
}
]
}MLflow UI authentication (Lambda authorizer)
Browser access to the MLflow server is handled by the MLflow UI implemented with React. The MLflow UI hasn’t been designed to support authenticated users. Implementing a robust login flow might appear a daunting task, but luckily we can rely on the Amplify UI React components for authentication, which greatly reduces the effort to create a login flow in a React application, using Amazon Cognito for the identities store.
Amazon Cognito allows us to manage our own user base and also support third-party identity federation, making it feasible to build, for example, ADFS federation (see Building ADFS Federation for your Web App using Amazon Cognito User Pools for more details). Tokens issued by Amazon Cognito must be verified on API Gateway. Simply verifying the token is not enough for fine-grained access control, therefore the Lambda authorizer allows us the flexibility to implement the logic we need. We can then build our own Lambda authorizer to verify the JWT token and generate the IAM policies to let the API Gateway deny or allow the request. The following diagram illustrates the MLflow login flow.

For more information about the actual code changes, refer to the patch file cognito.patch, applicable to MLflow version 2.3.1.
This patch introduces two capabilities:
- Add the Amplify UI components and configure the Amazon Cognito details via environment variables that implement the login flow
- Extract the JWT from the session and create an Authorization header with a bearer token of where to send the JWT
Although maintaining diverging code from the upstream always adds more complexity than relying on the upstream, it’s worth noting that the changes are minimal because we rely on the Amplify React UI components.
With the new login flow in place, let’s create the production build for our updated MLflow UI. AWS Amplify Hosting is an AWS service that provides a git-based workflow for CI/CD and hosting of web apps. The build step in the pipeline is defined by the buildspec.yaml, where we can inject as environment variables details about the Amazon Cognito user pool ID, the Amazon Cognito identity pool ID, and the user pool client ID needed by the Amplify UI React component to configure the authentication flow. The following code is an example of the buildspec.yaml file:
version: "1.0"
applications:
- frontend:
phases:
preBuild:
commands:
- fallocate -l 4G /swapfile
- chmod 600 /swapfile
- mkswap /swapfile
- swapon /swapfile
- swapon -s
- yarn install
build:
commands:
- echo "REACT_APP_REGION=$REACT_APP_REGION" >> .env
- echo "REACT_APP_COGNITO_USER_POOL_ID=$REACT_APP_COGNITO_USER_POOL_ID" >> .env
- echo "REACT_APP_COGNITO_IDENTITY_POOL_ID=$REACT_APP_COGNITO_IDENTITY_POOL_ID" >> .env
- echo "REACT_APP_COGNITO_USER_POOL_CLIENT_ID=$REACT_APP_COGNITO_USER_POOL_CLIENT_ID" >> .env
- yarn run build
artifacts:
baseDirectory: build
files:
- "**/*"Securely log experiments and runs using the SageMaker execution role
One of the key aspects of the solution discussed here is the secure integration with SageMaker. SageMaker is a managed service, and as such, it performs operations on your behalf. What SageMaker is allowed to do is defined by the IAM policies attached to the execution role that you associate to a SageMaker training job, or that you associate to a user profile working from Studio. For more information on the SageMaker execution role, refer to SageMaker Roles.
By configuring the API Gateway to use IAM authentication on the <MLFlow-Tracking-Server-URI>/api/* resources, we can define a set of IAM policies on the SageMaker execution role that will allow SageMaker to interact with MLflow according to the access level specified.
When setting the MLFLOW_TRACKING_AWS_SIGV4 environment variable to True while working in Studio or in a SageMaker training job, the MLflow Python SDK will automatically sign all requests, which will be validated by the API Gateway:
os.environ['MLFLOW_TRACKING_AWS_SIGV4'] = "True"
mlflow.set_tracking_uri(tracking_uri)
mlflow.set_experiment(experiment_name)Test the SageMaker execution role with the MLflow SDK
If you access the Studio domain that was generated, you will find three users:
- mlflow-admin – Associated to an execution role with similar permissions as the user in the Amazon Cognito group admins
- mlflow-reader – Associated to an execution role with similar permissions as the user in the Amazon Cognito group readers
- mlflow-model-approver – Associated to an execution role with similar permissions as the user in the Amazon Cognito group model-approvers
To test the three different roles, refer to the labs provided as part of this sample on each user profile.
The following diagram illustrates the workflow for Studio user profiles and SageMaker job authentication with MLflow.

Similarly, when running SageMaker jobs on the SageMaker managed infrastructure, if you set the environment variable MLFLOW_TRACKING_AWS_SIGV4 to True, and the SageMaker execution role passed to the jobs has the correct IAM policy to access the API Gateway, you can securely interact with your MLflow tracking server without needing to manage the credentials yourself. When running SageMaker training jobs and initializing an estimator class, you can pass environment variables that SageMaker will inject and make it available to the training script, as shown in the following code:
environment={
"AWS_DEFAULT_REGION": region,
"MLFLOW_EXPERIMENT_NAME": experiment_name,
"MLFLOW_TRACKING_URI": tracking_uri,
"MLFLOW_AMPLIFY_UI_URI": mlflow_amplify_ui,
"MLFLOW_TRACKING_AWS_SIGV4": "true",
"MLFLOW_USER": user
}
estimator = SKLearn(
entry_point='train.py',
source_dir='source_dir',
role=role,
metric_definitions=metric_definitions,
hyperparameters=hyperparameters,
instance_count=1,
instance_type='ml.m5.large',
framework_version='1.0-1',
base_job_name='mlflow',
environment=environment
)Visualize runs and experiments from the MLflow UI
After the first deployment is complete, let’s populate the Amazon Cognito user pool with three users, each belonging to a different group, to test the permissions we have implemented. You can use this script add_users_and_groups.py to seed the user pool. After running the script, if you check the Amazon Cognito user pool on the Amazon Cognito console, you should see the three users created.

On the REST API Gateway side, the Lambda authorizer will first verify the signature of the token using the Amazon Cognito user pool key and verify the claims. Only after that will it extract the Amazon Cognito group the user belongs to from the claim in the JWT token (cognito:groups) and apply different permissions based on the group that we have programmed.
For our specific case, we have three groups:
- admins – Can see and can edit everything
- readers – Can only see everything
- model-approvers – The same as readers, plus can register models, create versions, and promote model versions to the next stage
Depending on the group, the Lambda authorizer will generate different IAM policies. This is just an example on how authorization can be achieved; with a Lambda authorizer, you can implement any logic you need. We have opted to build the IAM policy at run time in the Lambda function itself; however, you can pregenerate appropriate IAM policies, store them in Amazon DynamoDB, and retrieve them at run time according to your own business logic. However, if you want to restrict only a subset of actions, you need to be aware of the MLflow REST API definition.
You can explore the code for the Lambda authorizer on the GitHub repo.
Multi-account considerations
Data science workflows have to pass multiple stages as they progress from experimentation to production. A common approach involves separate accounts dedicated to different phases of the AI/ML workflow (experimentation, development, and production). However, sometimes it’s desirable to have a dedicated account that acts as central repository for models. Although our architecture and sample refer to a single account, it can be easily extended to implement this last scenario, thanks to the IAM capability to switch roles even across accounts.
The following diagram illustrates an architecture using MLflow as a central repository in an isolated AWS account.

For this use case, we have two accounts: one for the MLflow server, and one for the experimentation accessible by the data science team. To enable cross-account access from a SageMaker training job running in the data science account, we need the following elements:
- A SageMaker execution role in the data science AWS account with an IAM policy attached that allows assuming a different role in the MLflow account:
{
"Version": "2012-10-17",
"Statement": {
"Effect": "Allow",
"Action": "sts:AssumeRole",
"Resource": "<ARN-ROLE-IN-MLFLOW-ACCOUNT>"
}
}- An IAM role in the MLflow account with the right IAM policy attached that grants access to the MLflow tracking server, and allows the SageMaker execution role in the data science account to assume it:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"AWS": "<ARN-SAGEMAKER-EXECUTION-ROLE-IN-DATASCIENCE-ACCOUNT>"
},
"Action": "sts:AssumeRole"
}
]
}Within the training script running in the data science account, you can use this example before initializing the MLflow client. You need to assume the role in the MLflow account and store the temporary credentials as environment variables, because this new set of credentials will be picked up by a new Boto3 session initialized within the MLflow client.
import boto3
# Session using the SageMaker Execution Role in the Data Science Account
session = boto3.Session()
sts = session.client("sts")
response = sts.assume_role(
RoleArn="<ARN-ROLE-IN-MLFLOW-ACCOUNT>",
RoleSessionName="AssumedMLflowAdmin"
)
credentials = response['Credentials']
os.environ['AWS_ACCESS_KEY_ID'] = credentials['AccessKeyId']
os.environ['AWS_SECRET_ACCESS_KEY'] = credentials['SecretAccessKey']
os.environ['AWS_SESSION_TOKEN'] = credentials['SessionToken']
# set remote mlflow server and initialize a new boto3 session in the context
# of the assumed role
mlflow.set_tracking_uri(tracking_uri)
experiment = mlflow.set_experiment(experiment_name)In this example, RoleArn is the ARN of the role you want to assume, and RoleSessionName is name that you choose for the assumed session. The sts.assume_role method returns temporary security credentials that the MLflow client will use to create a new client for the assumed role. The MLflow client then will send signed requests to API Gateway in the context of the assumed role.
Render MLflow within SageMaker Studio
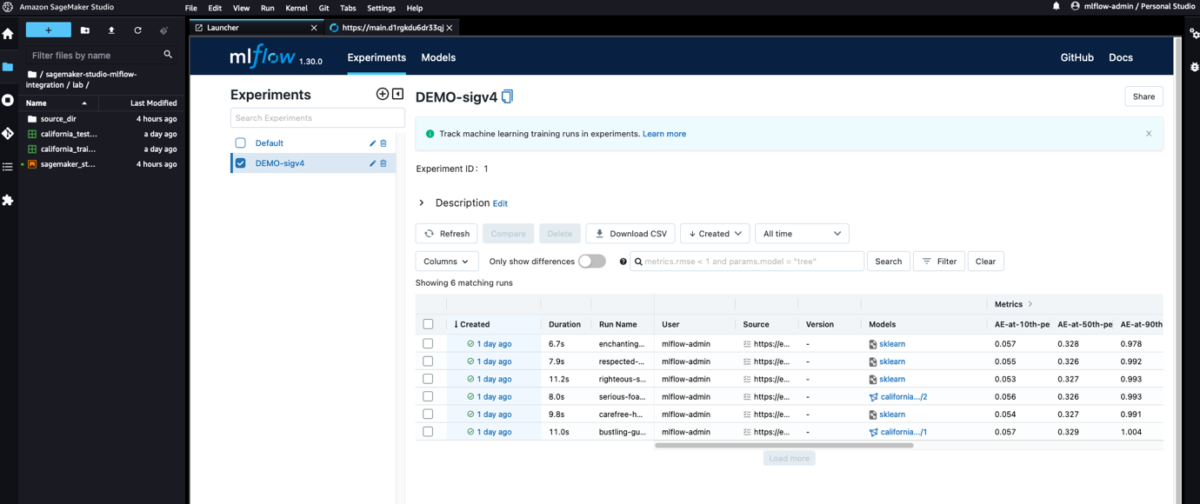
SageMaker Studio is based on JupyterLab, and just as in JupyterLab, you can install extensions to boost your productivity. Thanks to this flexibility, data scientists working with MLflow and SageMaker can further improve their integration by accessing the MLflow UI from the Studio environment and immediately visualizing the experiments and runs logged. The following screenshot shows an example of MLflow rendered in Studio.

For information about installing JupyterLab extensions in Studio, refer to Amazon SageMaker Studio and SageMaker Notebook Instance now come with JupyterLab 3 notebooks to boost developer productivity. For details on adding automation via lifecycle configurations, refer to Customize Amazon SageMaker Studio using Lifecycle Configurations.
In the sample repository supporting this post, we provide instructions on how to install the jupyterlab-iframe extension. After the extension has been installed, you can access the MLflow UI without leaving Studio using the same set of credentials you have stored in the Amazon Cognito user pool.
Next steps
There are several options for expanding upon this work. One idea is to consolidate the identity store for both SageMaker Studio and the MLflow UI. Another option would be to utilize a third-party identity federation service with Amazon Cognito, and then utilize AWS IAM Identity Center (successor to AWS Single Sign-On) to grant access to Studio using the same third-party identity. Another one is to introduce full automation using Amazon SageMaker Pipelines for the CI/CD part of the model building, and using MLflow as a centralized experiment tracking server and model registry with strong governance capabilities, as well as automation to automatically deploy approved models to a SageMaker hosting endpoint.
Conclusion
The aim of this post was to provide enterprise-level access control for MLflow. To achieve this, we separated the authentication and authorization processes from the MLflow server and transferred them to API Gateway. We utilized two authorization methods offered by API Gateway, IAM authorizers and Lambda authorizers, to cater to the requirements of both the MLflow Python SDK and the MLflow UI. It’s important to understand that users are external to MLflow, therefore a consistent governance requires maintaining the IAM policies, especially in case of very granular permissions. Finally, we demonstrated how to enhance the experience of data scientists by integrating MLflow into Studio through simple extensions.
Try out the solution on your own by accessing the GitHub repo and let us know if you have any questions in the comments!
Additional resources
For more information about SageMaker and MLflow, see the following:
- MLOps foundation roadmap for enterprises with Amazon SageMaker
- Build a cross-account MLOps workflow using the Amazon SageMaker model registry
- Managing your machine learning lifecycle with MLflow and Amazon SageMaker
- SageMaker Studio Administration Best Practices
About the Authors
 Paolo Di Francesco is a Senior Solutions Architect at Amazon Web Services (AWS). He holds a PhD in Telecommunication Engineering and has experience in software engineering. He is passionate about machine learning and is currently focusing on using his experience to help customers reach their goals on AWS, in particular in discussions around MLOps. Outside of work, he enjoys playing football and reading.
Paolo Di Francesco is a Senior Solutions Architect at Amazon Web Services (AWS). He holds a PhD in Telecommunication Engineering and has experience in software engineering. He is passionate about machine learning and is currently focusing on using his experience to help customers reach their goals on AWS, in particular in discussions around MLOps. Outside of work, he enjoys playing football and reading.
 Chris Fregly is a Principal Specialist Solution Architect for AI and machine learning at Amazon Web Services (AWS) based in San Francisco, California. He is co-author of the O’Reilly Book, “Data Science on AWS.” Chris is also the Founder of many global meetups focused on Apache Spark, TensorFlow, Ray, and KubeFlow. He regularly speaks at AI and machine learning conferences across the world including O’Reilly AI, Open Data Science Conference, and Big Data Spain.
Chris Fregly is a Principal Specialist Solution Architect for AI and machine learning at Amazon Web Services (AWS) based in San Francisco, California. He is co-author of the O’Reilly Book, “Data Science on AWS.” Chris is also the Founder of many global meetups focused on Apache Spark, TensorFlow, Ray, and KubeFlow. He regularly speaks at AI and machine learning conferences across the world including O’Reilly AI, Open Data Science Conference, and Big Data Spain.
 Irshad Buchh is a Principal Solutions Architect at Amazon Web Services (AWS). Irshad works with large AWS Global ISV and SI partners and helps them build their cloud strategy and broad adoption of Amazon’s cloud computing platform. Irshad interacts with CIOs, CTOs and their Architects and helps them and their end customers implement their cloud vision. Irshad owns the strategic and technical engagements and ultimate success around specific implementation projects, and developing a deep expertise in the Amazon Web Services technologies as well as broad know-how around how applications and services are constructed using the Amazon Web Services platform.
Irshad Buchh is a Principal Solutions Architect at Amazon Web Services (AWS). Irshad works with large AWS Global ISV and SI partners and helps them build their cloud strategy and broad adoption of Amazon’s cloud computing platform. Irshad interacts with CIOs, CTOs and their Architects and helps them and their end customers implement their cloud vision. Irshad owns the strategic and technical engagements and ultimate success around specific implementation projects, and developing a deep expertise in the Amazon Web Services technologies as well as broad know-how around how applications and services are constructed using the Amazon Web Services platform.
Author: Paolo Di Francesco