

Vector search for Amazon MemoryDB is now generally available
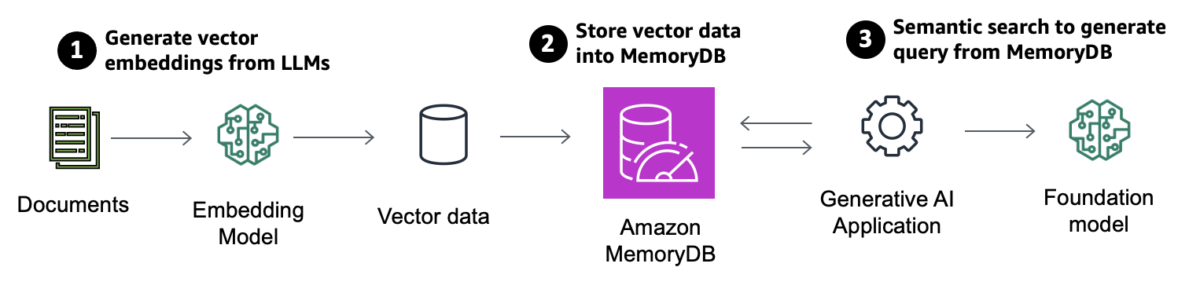
Today, we are announcing the general availability of vector search for Amazon MemoryDB, a new capability that you can use to store, index, retrieve, and search vectors to develop real-time machine learning (ML) and generative artificial intelligence (generative AI) applications with in-memory perfor…
Today, we are announcing the general availability of vector search for Amazon MemoryDB, a new capability that you can use to store, index, retrieve, and search vectors to develop real-time machine learning (ML) and generative artificial intelligence (generative AI) applications with in-memory performance and multi-AZ durability.
With this launch, Amazon MemoryDB delivers the fastest vector search performance at the highest recall rates among popular vector databases on Amazon Web Services (AWS). You no longer have to make trade-offs around throughput, recall, and latency, which are traditionally in tension with one another.
You can now use one MemoryDB database to store your application data and millions of vectors with single-digit millisecond query and update response times at the highest levels of recall. This simplifies your generative AI application architecture while delivering peak performance and reducing licensing cost, operational burden, and time to deliver insights on your data.
With vector search for Amazon MemoryDB, you can use the existing MemoryDB API to implement generative AI use cases such as Retrieval Augmented Generation (RAG), anomaly (fraud) detection, document retrieval, and real-time recommendation engines. You can also generate vector embeddings using artificial intelligence and machine learning (AI/ML) services like Amazon Bedrock and Amazon SageMaker and store them within MemoryDB.
Which use cases would benefit most from vector search for MemoryDB?
You can use vector search for MemoryDB for the following specific use cases:
1. Real-time semantic search for retrieval-augmented generation (RAG)
You can use vector search to retrieve relevant passages from a large corpus of data to augment a large language model (LLM). This is done by taking your document corpus, chunking them into discrete buckets of texts, and generating vector embeddings for each chunk with embedding models such as the Amazon Titan Multimodal Embeddings G1 model, then loading these vector embeddings into Amazon MemoryDB.

With RAG and MemoryDB, you can build real-time generative AI applications to find similar products or content by representing items as vectors, or you can search documents by representing text documents as dense vectors that capture semantic meaning.
2. Low latency durable semantic caching
Semantic caching is a process to reduce computational costs by storing previous results from the foundation model (FM) in-memory. You can store prior inferenced answers alongside the vector representation of the question in MemoryDB and reuse them instead of inferencing another answer from the LLM.

If a user’s query is semantically similar based on a defined similarity score to a prior question, MemoryDB will return the answer to the prior question. This use case will allow your generative AI application to respond faster with lower costs from making a new request to the FM and provide a faster user experience for your customers.
3. Real-time anomaly (fraud) detection
You can use vector search for anomaly (fraud) detection to supplement your rule-based and batch ML processes by storing transactional data represented by vectors, alongside metadata representing whether those transactions were identified as fraudulent or valid.

The machine learning processes can detect users’ fraudulent transactions when the net new transactions have a high similarity to vectors representing fraudulent transactions. With vector search for MemoryDB, you can detect fraud by modeling fraudulent transactions based on your batch ML models, then loading normal and fraudulent transactions into MemoryDB to generate their vector representations through statistical decomposition techniques such as principal component analysis (PCA).
As inbound transactions flow through your front-end application, you can run a vector search against MemoryDB by generating the transaction’s vector representation through PCA, and if the transaction is highly similar to a past detected fraudulent transaction, you can reject the transaction within single-digit milliseconds to minimize the risk of fraud.
Getting started with vector search for Amazon MemoryDB
Look at how to implement a simple semantic search application using vector search for MemoryDB.
Step 1. Create a cluster to support vector search
You can create a MemoryDB cluster to enable vector search within the MemoryDB console. Choose Enable vector search in the Cluster settings when you create or update a cluster. Vector search is available for MemoryDB version 7.1 and a single shard configuration.

Step 2. Create vector embeddings using the Amazon Titan Embeddings model
You can use Amazon Titan Text Embeddings or other embedding models to create vector embeddings, which is available in Amazon Bedrock. You can load your PDF file, split the text into chunks, and get vector data using a single API with LangChain libraries integrated with AWS services.
import redis
import numpy as np
from langchain.document_loaders import PyPDFLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.embeddings import BedrockEmbeddings
# Load a PDF file and split document
loader = PyPDFLoader(file_path=pdf_path)
pages = loader.load_and_split()
text_splitter = RecursiveCharacterTextSplitter(
separators=["nn", "n", ".", " "],
chunk_size=1000,
chunk_overlap=200,
)
chunks = loader.load_and_split(text_splitter)
# Create MemoryDB vector store the chunks and embedding details
client = RedisCluster(
host=' mycluster.memorydb.us-east-1.amazonaws.com',
port=6379,
ssl=True,
ssl_cert_reqs="none",
decode_responses=True,
)
embedding = BedrockEmbeddings (
region_name="us-east-1",
endpoint_url=" https://bedrock-runtime.us-east-1.amazonaws.com",
)
#Save embedding and metadata using hset into your MemoryDB cluster
for id, dd in enumerate(chucks*):
y = embeddings.embed_documents([dd])
j = np.array(y, dtype=np.float32).tobytes()
client.hset(f'oakDoc:{id}', mapping={'embed': j, 'text': chunks[id] } )Once you generate the vector embeddings using the Amazon Titan Text Embeddings model, you can connect to your MemoryDB cluster and save these embeddings using the MemoryDB HSET command.
Step 3. Create a vector index
To query your vector data, create a vector index using theFT.CREATE command. Vector indexes are also constructed and maintained over a subset of the MemoryDB keyspace. Vectors can be saved in JSON or HASH data types, and any modifications to the vector data are automatically updated in a keyspace of the vector index.
from redis.commands.search.field import TextField, VectorField
index = client.ft(idx:testIndex).create_index([
VectorField(
"embed",
"FLAT",
{
"TYPE": "FLOAT32",
"DIM": 1536,
"DISTANCE_METRIC": "COSINE",
}
),
TextField("text")
]
)In MemoryDB, you can use four types of fields: numbers fields, tag fields, text fields, and vector fields. Vector fields support K-nearest neighbor searching (KNN) of fixed-sized vectors using the flat search (FLAT) and hierarchical navigable small worlds (HNSW) algorithm. The feature supports various distance metrics, such as euclidean, cosine, and inner product. We will use the euclidean distance, a measure of the angle distance between two points in vector space. The smaller the euclidean distance, the closer the vectors are to each other.
Step 4. Search the vector space
You can use FT.SEARCH and FT.AGGREGATE commands to query your vector data. Each operator uses one field in the index to identify a subset of the keys in the index. You can query and find filtered results by the distance between a vector field in MemoryDB and a query vector based on some predefined threshold (RADIUS).
from redis.commands.search.query import Query
# Query vector data
query = (
Query("@vector:[VECTOR_RANGE $radius $vec]=>{$YIELD_DISTANCE_AS: score}")
.paging(0, 3)
.sort_by("vector score")
.return_fields("id", "score")
.dialect(2)
)
# Find all vectors within 0.8 of the query vector
query_params = {
"radius": 0.8,
"vec": np.random.rand(VECTOR_DIMENSIONS).astype(np.float32).tobytes()
}
results = client.ft(index).search(query, query_params).docsFor example, when using cosine similarity, the RADIUS value ranges from 0 to 1, where a value closer to 1 means finding vectors more similar to the search center.
Here is an example result to find all vectors within 0.8 of the query vector.
[Document {'id': 'doc:a', 'payload': None, 'score': '0.243115246296'},
Document {'id': 'doc:c', 'payload': None, 'score': '0.24981123209'},
Document {'id': 'doc:b', 'payload': None, 'score': '0.251443207264'}]To learn more, you can look at a sample generative AI application using RAG with MemoryDB as a vector store.
What’s new at GA
At re:Invent 2023, we released vector search for MemoryDB in preview. Based on customers’ feedback, here are the new features and improvements now available:
VECTOR_RANGEto allow MemoryDB to operate as a low latency durable semantic cache, enabling cost optimization and performance improvements for your generative AI applications.SCOREto better filter on similarity when conducting vector search.- Shared memory to not duplicate vectors in memory. Vectors are stored within the MemoryDB keyspace and pointers to the vectors are stored in the vector index.
- Performance improvements at high filtering rates to power the most performance-intensive generative AI applications.
Now available
Vector search is available in all Regions that MemoryDB is currently available. Learn more about vector search for Amazon MemoryDB in the AWS documentation.
Give it a try in the MemoryDB console and send feedback to the AWS re:Post for Amazon MemoryDB or through your usual AWS Support contacts.
— Channy
Author: Channy Yun